导语
Elasticsearch(文中简称 ES)是分布式全文搜索引擎,产品提供高可用、易扩展以及近实时的搜索能力,广泛应用于数据存储、搜索和实时分析。很多服务的可用性对 ES 重度依赖。因此,保障 ES 自身可用性,是实现服务高可用的重中之重。
基于京东云丰富的运维实战经验,接下来我们将陆续推出 ES 运维干货,欢迎小伙伴们持续关注。今天带来第一篇内容——Elasticsearch监控实战。
↓↓↓
监控,是服务可用性保障的关键之一。本文从运维角度,对 ES 服务监控进行了系统性总结,涵盖监控工具选型、监控采集项筛选介绍,最后列举了几个借助监控发现的ES线上问题。
ES监控概览
针对 ES 进行监控,主要期望解决这几种场景:
ES 日常服务巡检,帮助运维开发人员及时发现隐患
ES 服务异常后,帮助运维开发人员及时发现故障
采集的 ES 监控指标,帮助运维开发人员迅速定位问题根因
能够及时发现ES服务异常,这是最主要目标。
监控工具选型
借助运维工具,在 ES 实际运维工作中能极大提升运维开发人员的工作效率。目前 ES 可用的监控工具或插件很多,对多种监控工具进行评测分析后,我们最终的监控工具选型为:
X-Pack+kibana
索引信息、集群整体信息很有帮助,尤其是各索引的索引、搜索速率,索引延迟数据等。其中,X-Pack 是官方给出的插件(Monitoring 为开放特性),需要注意的是,ES 集群上线前就需要安装 X-Pack 插件。图一展现了在 Kibana 中,Monitoring 的部分功能。
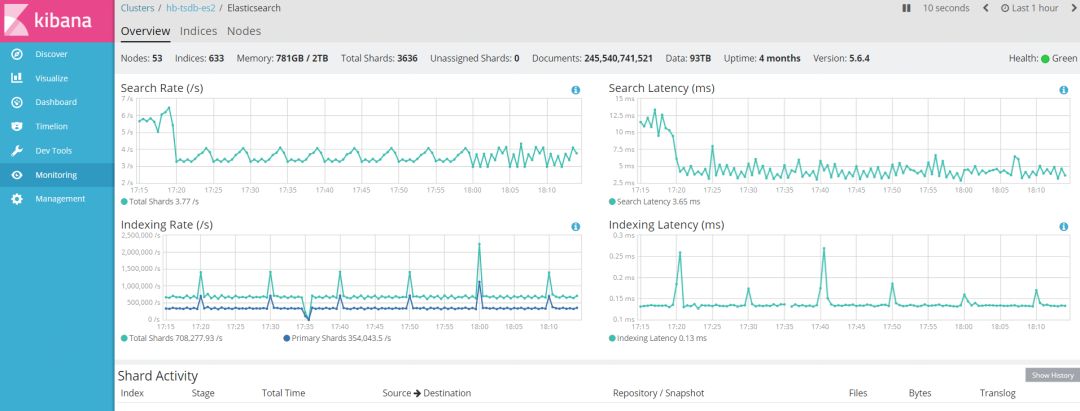
图一 Monitoring部分功能
Jmxtrans-ES+influxdb
主要进行核心数据采集、监控。ES 本身提供的 jmx 信息有限,这里使用了Jmxtrans-ES(自研)工具,通过 http 接口获取信息后,写入到 influxdb。ES 与 influxdb 的结合,官方给出的方案是读取 X-Pack 中的索引信息,考虑到 X-pack 索引是存储在 ES,保留时间有限,以及与京东云内部监控系统的对接,我们自研了 Jmxtrans-ES 工具进行核心信息采集,也自研了 ES-Monitor功能监控工具,仪表盘通过 Grafana 进行展现。图二展现了 ES 集群部分核心数据。
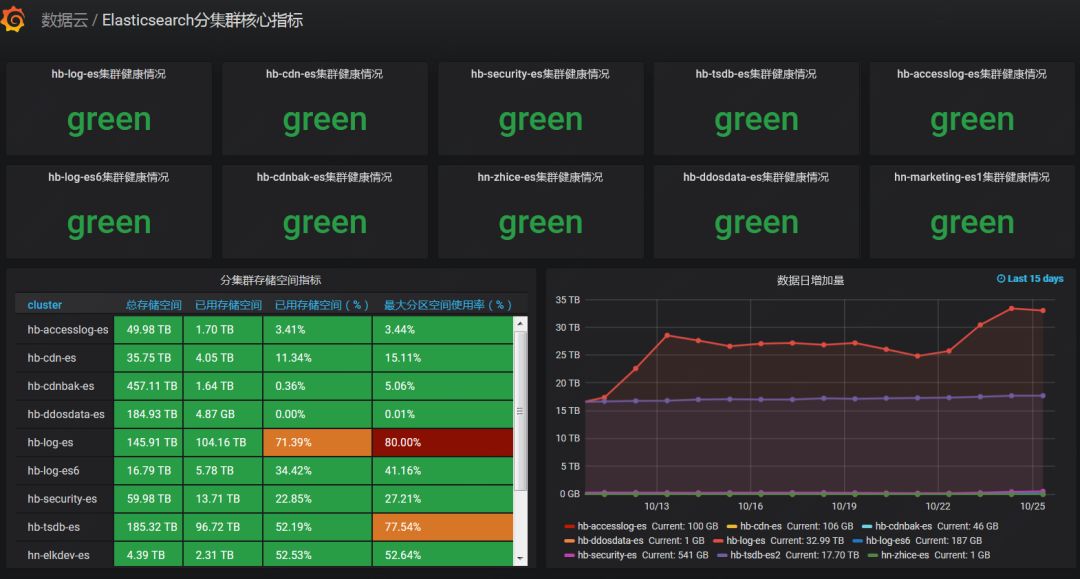
图二 ES集群部分核心数据
Elasticsearch-HQ
这款工具属于清新风格。之前使用的 head 插件,在集群规模达到一定程度后,head 插件信息展现不理想,因此使用了 HQ 代替 head 部分功能。如果很难记住管理 API,可以借助 ES-command 工具。图三展现了 ElasticHQ 管理界面。

图三 ElasticHQ管理界面
告警对接京东云内部告警平台。
采集项筛选
实战中,ES 集群部署使用 5.x 版本,区分协调(coordinating)、摄取(ingest)、主(master)、数据(data)等节点,独立部署,数据节点机器异构。
按照 SRE 黑盒监控和白盒监控进行分类:
1、黑盒监控
集群功能
索引创建、删除、文档写入、查询等基本功能。实际监控中,创建索引时,需要控制好频率以及分片的分配情况。实战中,由于索引创建频率较高,并且分片数量设置不合理,导致集群 pending 任务堆积,导致正常业务创建索引出现大量延迟或失败。
集群整体状态
理论上,集群正常状态为 green,出现 red 时,集群肯定存在部分索引主备分片全部丢失情况。集群状态为 yellow 时,也不能完全代表集群没有问题。比如,创建索引时,如果分片没有完全分配完成,也会出现 yellow 状态。因此,集群出现 yellow 时,也需要重点关注或排查集群可能存在的问题。
活跃分片数百分比
Pending任务数
Pending任务数99%时间均为0,如果出现长时间为非0情况,集群肯定出现了异常。
2、白盒监控
1)容量
作为存储组件,对于存储容量的监控至关重要。
总存储空间:ES 本身没有提供此方面监控数据,需要自行进行计算。
已用存储空间:总存储空间是不能全部使用完,需要预留一部分空间。
最大分区使用:在 ES 中,如果某数据节点单块数据目录使用率超过90%(默认值,可以通过 cluster.routing.allocation.disk.watermark 相关配置来调整),则会进行分片数据迁移。因此,在数据盘存在异构的集群中,为避免分片迁移,监控此值,至关重要。
机器(或实例)资源(CPU、Load、Disk、JVM)
分片数量:最好不超过一万个分片。官方推荐,单个实例 JVM 内存不超过30GB,不超过600个分片。另外,分片是由 Master 来维护其状态的,而 Master 在任何集群规模下,有且仅有一个节点在工作,其余均为候选主节点,因此分片数量越高,Master 常态的压力越大,故障后恢复的耗时也越长。合理的分片数量与集群节点数、写入数据量、磁盘读写性能等存在一定关系,具体可以参考官方说明。
线程池队列长度
2)流量
索引、搜索速率:需要监控总量,但是需要采集主要 index 的数据,便于问题定位。例如哪个索引突增流量将集群压垮了?如果没有细化的 index 的相关数据采集,就只能通过 index 的体积来进行间接判断,延时也类似。
集群网络IO
集群数据节点IO:实际部署中,会区分摄取(ingest)、主(master)、数据(data)等节点,这里重点监控数据节点IO。
3)延迟
索引、搜索延迟
慢查询
4)错误
集群异常节点数
索引、搜索拒绝数量
主节点错误日志
借助监控发现的问题
场景1:
如果 Elasticsearch 集群出现问题,通过 ES 接口获取到的监控数据可能出现响应超时,无法响应情况,造成监控工具不可用。
发现方式:功能监控响应超时告警
优化建议:1)避免该场景出现:需要在日常巡检排查中,发现集群隐患,优化集群配置项,消除隐患;2)如果出现此问题:那么针对各实例的存活性,错误日志监控不可缺失,通过此监控信息快速定位。
场景2:
如果某数据节点任何一个数据目录不可用(比如磁盘故障,其他应用占满数据目录)则新建索引若有分片分配到上面之后,则会出现创建索引失败。
发现方式:功能监控告警、pending 任务堆积告警
优化建议:为避免此问题出现,数据盘可以做 raid5 或 raid10,避免多个服务共用同一数据目录等。当然数据目录的可用性,也需要有方法能够知道。
场景3:
某索引因程序问题,出现大量创建 type,导致集群异常。
发现方式:pending 任务堆积告警,之后排查各索引写入速率,找到异常索引
优化建议:定期排查重点索引的数据写入合理性,以及服务巡检。
附:
涉及的部分开源软件,Git地址
ElasticHQ:https://github.com/ElasticHQ/elasticsearch-HQ
部分运维脚本,Git地址
Elasticsearch Monitor:https://github.com/cloud-op/monitor
关注我们
注意:本文归作者所有,未经作者允许,不得转载

