 来这里找志同道合的小伙伴!
来这里找志同道合的小伙伴!
随着业务规模的不断扩大,面临着服务数量不断膨胀、线上环境日益复杂、服务依赖错综复杂等运维痛点,服务依赖自动梳理、拓扑自动生成、调用实时追踪、异常明细分析、调用来源追踪、实时容量规划、问题根因分析等基本的运维诉求及解决方案就尤其重要。
如此庞大的业务规模及服务集群,每个用户场景都需要通过几十甚至上百个应用协同完成。如何确定每一次交易过程中,每个系统处理耗时分别是多少?每个系统在处理这笔交易时分别在数据库、缓存、日志、RPC、业务逻辑上分别耗时多少?如何快速确定系统的真正瓶颈点?
PS:本文的所有案例数据皆为模拟数据。
SGM的产生背景
随着互联网的不断发展,业务场景不断创新,业务变化之快超乎想象。如何通过抽象与建模,及时响应研发团队对各种各样的业务场景的快速监控与运维,对研发和运维都非常重要。
面对一系列复杂的问题,SGM 应运而生,提供了一整套服务治理与监控的解决方案,在每日千亿级调用中,可以追溯每次调用的详细分析。目前承载着上千核心应用的监控任务,每天日调用量超过千亿。
SGM的设计目标

▲图1 SGM的设计目标
SGM 立足于三大基本诉求,希望做到最全的监控、最准的报警、最快的运维。为开发人员提供问题最根本的解决思路,为运维人员提供系统最实时的运行状况,为管理人员提供项目最全面的性能分析。
SGM的设计理念
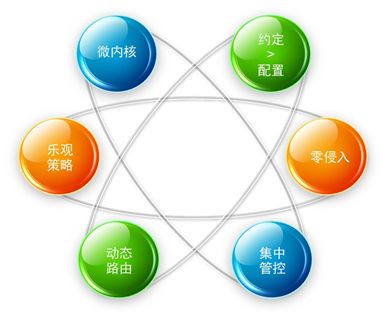
▲图2 SGM 的设计理念
平台的设计始终贯彻「约定大于配置」和「零侵入」的极致设计理念,以极易的接入体验和强大的监控功能深受研发同学的好评。
微内核:系统采用 plugin 模式,把自己当成第三方扩展,更多的代码运行在应用的 ClassLoader;
约定大于配置:在部署规范、配置规范的基础上自动发现接口及方法,约定默认返回码及返回描述;
零侵入:只依赖 jar 包,无任何代码入侵;
集中管控:从全局、应用、方法级别管控,每个采集字段可管控;
动态路由:日志传输节点远程控制,无限扩容;
乐观策略:监控项全异步处理,对象软引用,极端情况下采用抛弃策略,降低内存消耗。
SGM中的核心概念
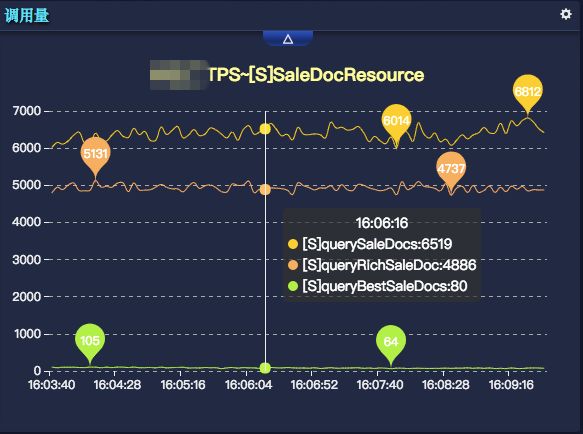
1)应用、服务、方法调用量、性能、成功率、可用率等基础监控与预警
调用量、性能、成功率和可用率是 SGM 作为业务监控系统所需要满足的最基本、最核心的功能。调用量监控指标为 TPS,性能指标包括 AVG、TP99、TP90、TP50 等,性能监控指标主要针对失败率进行的,可用率是反映应用程序本身异常的指标。
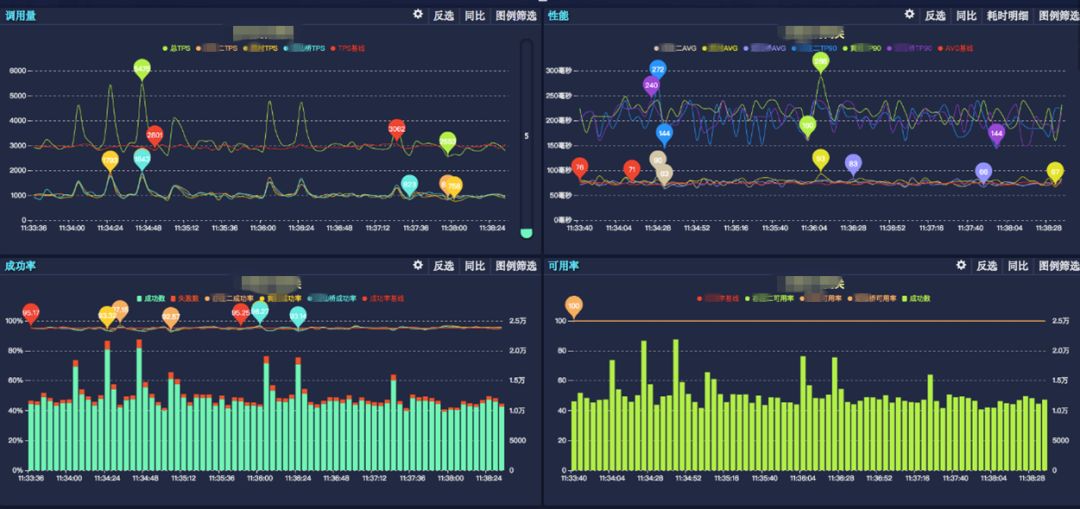
▲图3 性能监控图
通过选定应用、服务、方法及监控时间区间,SGM 会展示所选条件下的 TPS、AVG、成功率、可用率等曲线。
TPS:应用每秒钟处理的请求数
AVG:应用对每个请求响应的平均时间
TP99:99%的请求的响应时间小于或等于该值
TP90:90%的请求的响应时间小于或等于该值
TP50:50%的请求的响应时间小于或等于该值
失败率:应用对请求响应的成功、失败比率
可用率:应用对请求响应的成功、异常比率。这里的异常指的应用程序本身抛出的异常,不包括方法本身返回失败码的情况。通过这种筛选,能更精确定位出程序本身有异常问题的,如果应用配置了可用率的告警,也大大降低告警的误报率。
2)JVM 各种指标的监控与预警
JVM(JavaVirtualMachine,Java 虚拟机)是 JRE(JavaRuntimeEnvironment,Java 运行环境)的一部分。它是一个虚构出来的计算机,是通过在实际的计算机上仿真模拟各种计算机功能来实现的。JVM 有自己完善的硬件架构,如处理器、堆栈、寄存器等,还具有相应的指令系统。Java 语言最重要的特点就是跨平台运行。使用JVM就是为了支持与操作系统无关,实现跨平台。
SGM 提供对于监控 JVM 运行状态的实时监控,可通过图表展示 JVM 内存分配情况、内存使用情况、垃圾收集信息等内容。并可根据配置的 JVM 告警策略,在 GC 频繁发生的情况下通知相关人员。
3)动态容量规划,实时显示应用容量水位
现有技术评估容量都局限于人为压测评估或者静态评估,SGM 取代了人为压测评估方式,通过程序智能计算应用容量,将静态的容量评估变成动态的容量评估,使实时的容量评估和弹性伸缩成为可能。
SGM 通过获取到的方法耗时明细,结合连接数、线程池等指标,得出应用的单机容量,在此基础上再叠加 CPU、磁盘、网络带宽等指标来最终得到系统的单机容量。
水位即单台机器当前调用量占容量的比重,这个值会实时刷新显示当前水位。

调用链是一次请求所经过的所有系统的集合产生的链条,反馈了系统间的依赖关系及时序,是分布式服务跟踪的关键所在。
调用链是由调用的源头系统产生一个全局唯一的 ID (「RootID」),每个调用节点产生一个自身的节点 ID (「NodeID」),通过应用层协议将两个唯一的 ID 透传到各服务节点,每个节点产生一条调用日志,最终由服务端通过这些调用日志还原系统行为的过程。
目前 SGM 支持的应用层协议包括 HTTP(Servlet、 NettyHTTP Decoder、 Apache HttpClient、JDK HttpURLConnection)、JMS(ActiveMQ、)、AMQP(RabbitMQ)、DUBBO、JSF、JDBC(MySQL、Oracle、SQLServer)、Redis 等等,如下示意图及案例图。
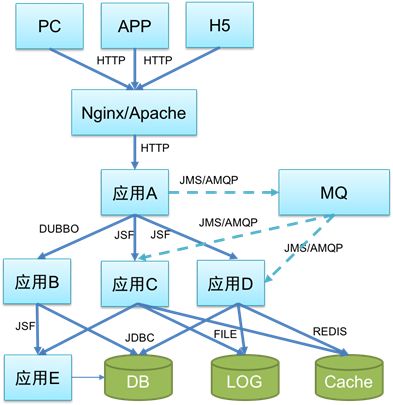
▲图4 调用链示意图
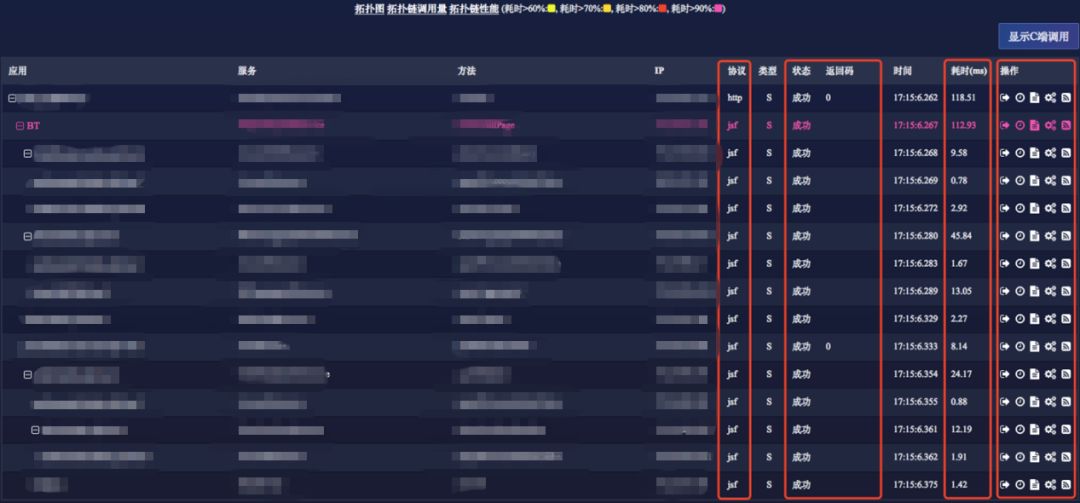
▲图5 调用链案例图
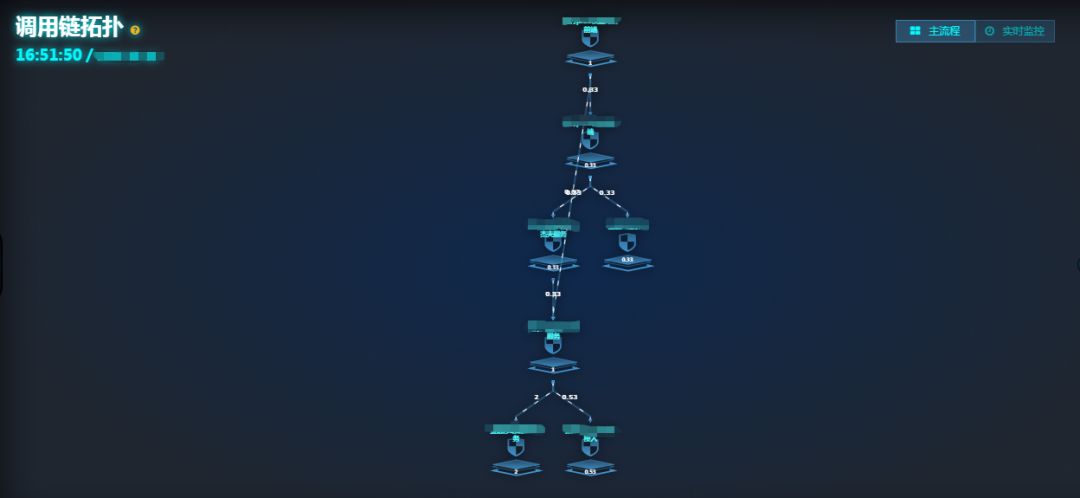
▲图6 调用链案例图
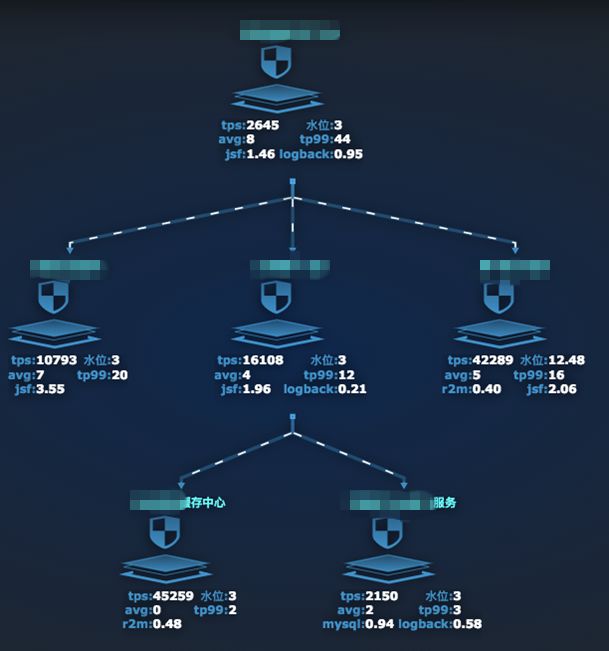
针对这条调用链拓扑也可同时查看拓扑图上各节点的实时监控数据,包含 TPS、AVG、水位、底层监控(mysql、logback 等)耗时等信息:
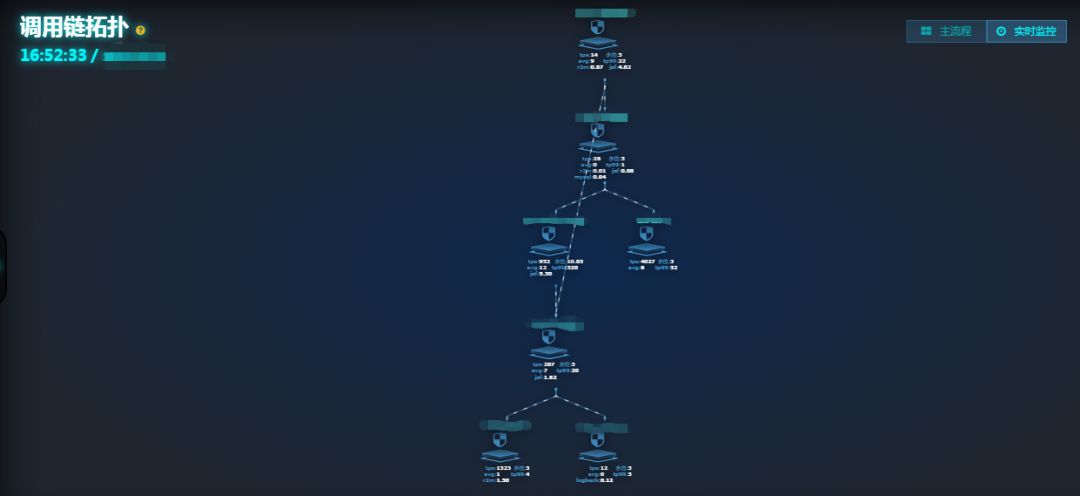
如下图所示,每一个服务端方法的调用都可以查看其耗时详情,这个在定位方法性能问题时有着尤为重要的作用。无需再借助其他繁琐的第三方工具,在查看调用链的同时,方法耗时详情也一目了然,耗时的分块包括逻辑、数据库、调用接口等。
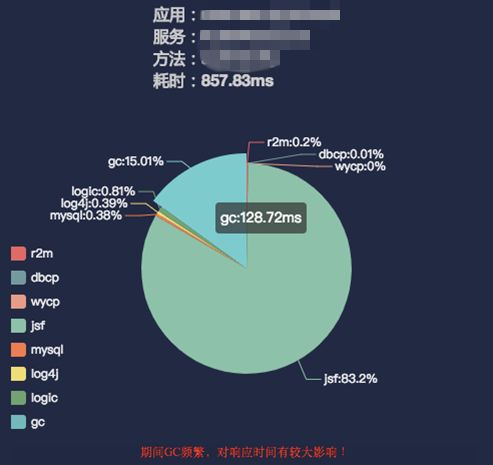
▲图7 耗时详情
业务监控是对业务监控目标的高度抽象,主要分为以下几大类:分类监控、比值监控、流程监控、自定义监控大屏。这几类监控并非相互独立,可以通过组合使用完成更复杂的监控需求。业务监控是满足监控需求多样化及实现监控配置化的基础。
1)分类监控
分类监控是指通过提取方法中某一个或多个参数字段,按照不同的值进行分门别类的一种监控手段。例如交互接口中,指定编号字段为提取参数,按照不同的编号来进行不同的监控。如果单独一家出现问题,那外部接口方面出问题概率较高,反之,如果所有出问题,则内部出现问题的概率较高,这也是定位问题范围及原因的一种方式。

▲图8 分类监控

▲图9 成功率
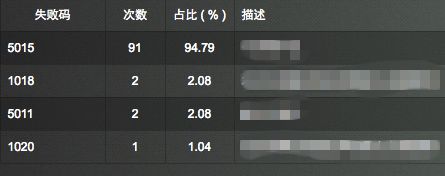
▲图10 失败原因分析
2)比值监控
比值监控是通过指定不同方法的调用量(成功、失败、全部)分别作为分子和分母,将产生的比值作为监控指标的一种监控手段。例如支付的成功量作为分子,下单的成功量作为分母,产生的比值即为支付转化率,支付转化率是考核支付公司的一项重要指标。
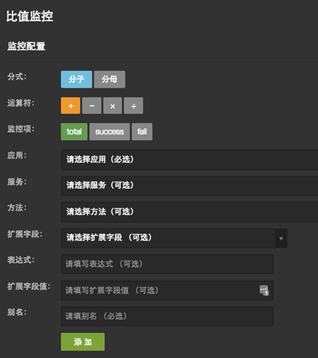
▲图11 比值监控配置
通过多个方法的调用量的比值作为监控指标典型案例:转化率、回执率等等。
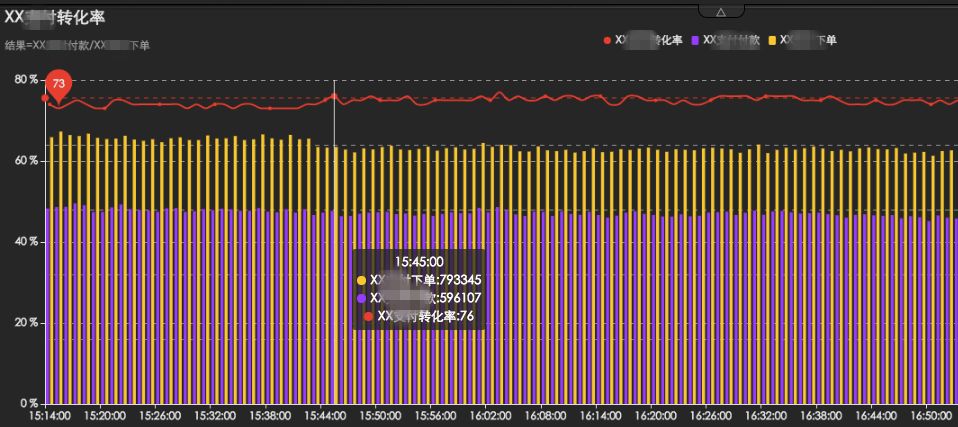
▲图12 XX转化率
3)流程监控
从业务的角度,通过配置应用、服务、方法、以及扩展字段的方式,来组建一个业务流程走向,对每个流程节点进行监控,包括性能监控和业务累加数据监控,其中业务累加数据是根据方法配置中,对扩展字段的取值来累加的。流程监控能实现更直观的针对独立流程进行全方位监控。
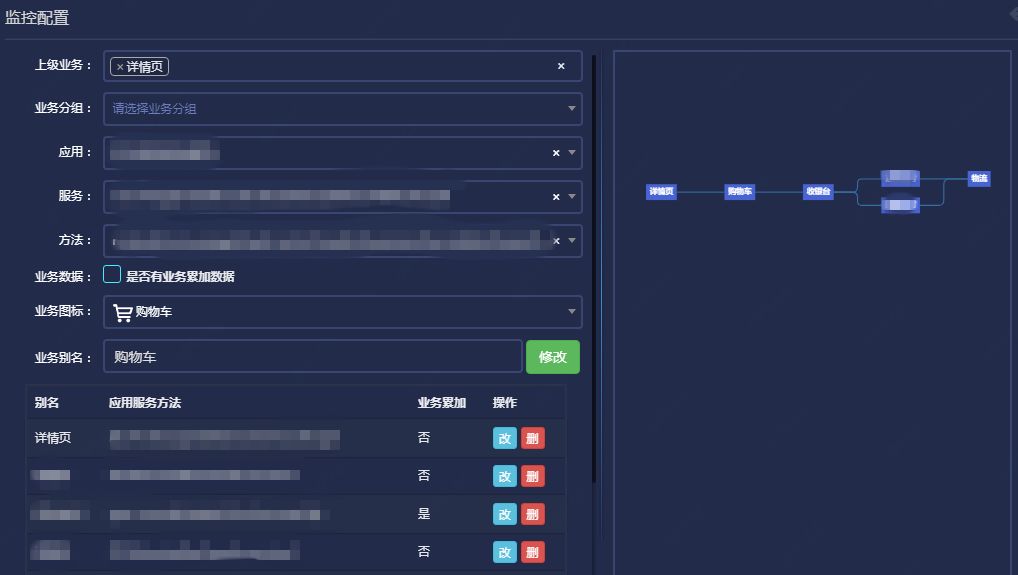
▲图13 流程监控配置
通过关联多个方法,组建一个具有业务含义的流程如下:
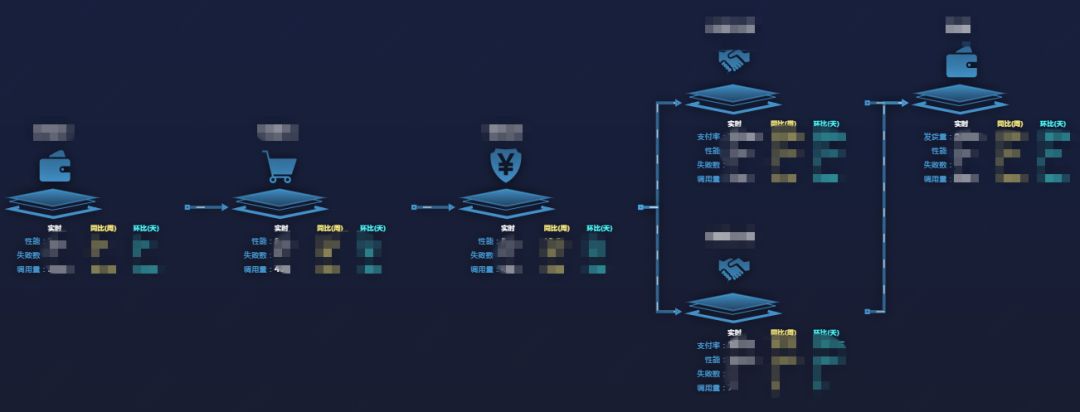
▲图14 XX流程监控
4)自定义监控大屏
为了满足各类用户的定制监控需求,比如将多个不同的方法的监控指标以不同的展示方式聚合到一个大屏上,或者脱离 SGM 其他功能,仅提供数据源将多个数据源展示在一个大屏进行监控等等,从而衍生了自定义监控大屏功能。「自定义」包含模板、图表类型、是否提供数据源等的自由选择,这些因素定义好之后,SGM 就将系统内部所提供的监控数据或者用户自定义提供的数据源以用户要求的方式展示在监控大屏上。
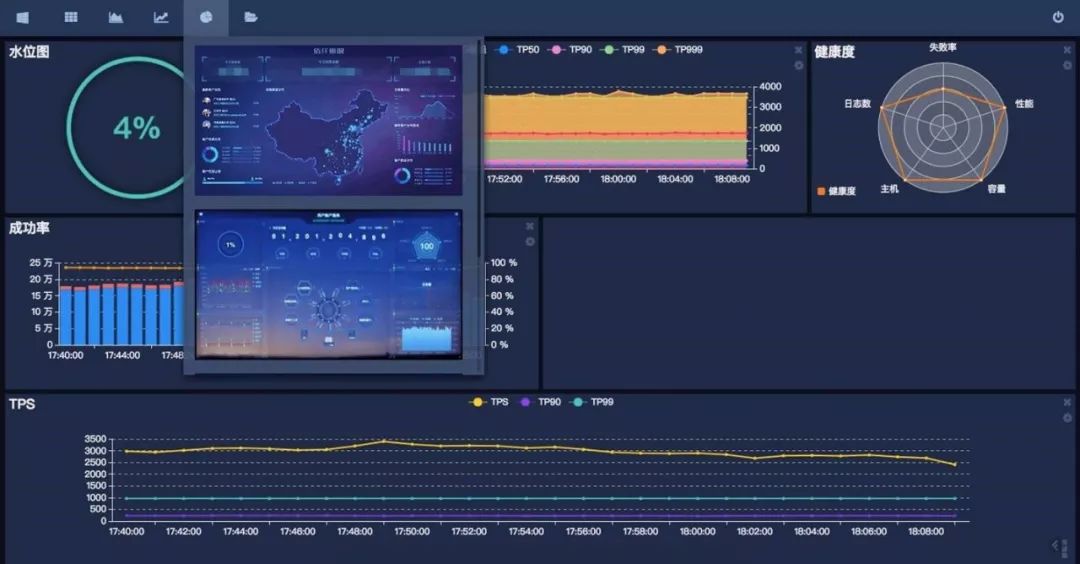
▲图15 自定义监控大屏
5)监控定制
用户可根据不同场景、不同业务进行公共定制、组内定制和个人定制,定制作为一个快捷入口,迅速切入所需监控图表。
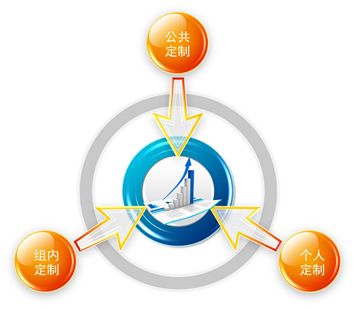
▲图16 监控定制
SGM的特性分析
SGM 默认采用异步批量准实时的方式将调用日志发送到服务端,可以实现亚秒级的监控能力,并对应用的性能影响极小。
SGM 提供机房网段配置,提供分机房、分 IP 展示能力。另外 SGM 采用了分层结构设计,即:应用->服务->方法,可以查看任意维度的监控信息。通过具有层级关系的曲线一层一层的往下查看详细情况。如下:
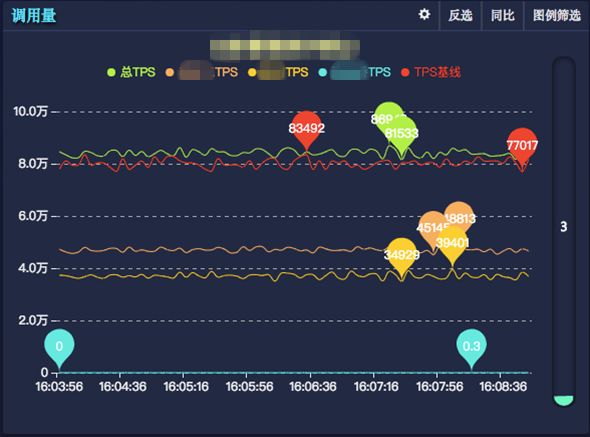
▲图17 应用维度监控
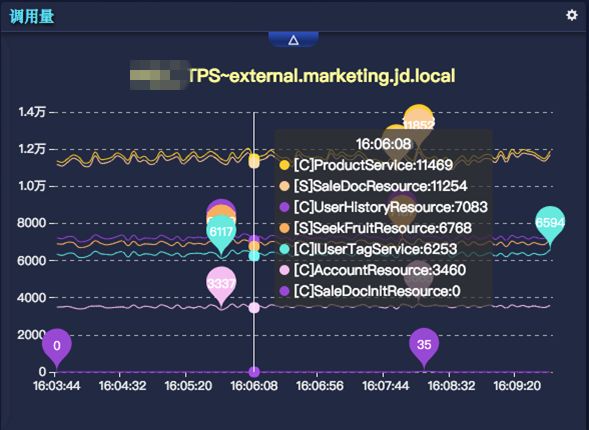
▲图18 服务维度监控
▲图19 方法维度监控

▲图20 IP维度监控

▲图21 机房配置维护
字段提取是指在程序运行期动态抽取指定方法中参数或返回值中的指定字段值。字段提取是实现业务监控的基础。
▲图22 字段提取示意图
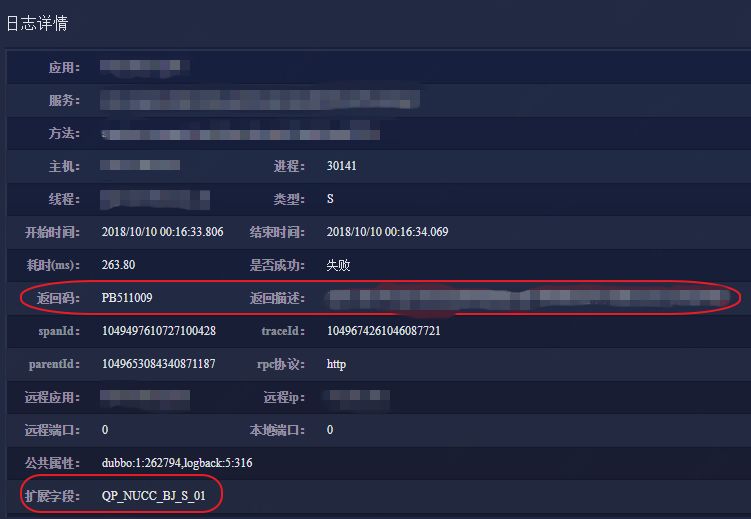
被 SGM 监控的方法并非简单的认为不抛出异常即调用成功,SGM 采用自动寻找返回码及返回描述的方式智能判断业务是否成功。例如银行扣款方法返回用户余额不足,一般不抛出异常,但是很显然这笔业务没有成功,设计优良的接口一定会在返回对象中存在返回码及返回描述字段,如responseCode=1000,responseDesc=用户余额不足。
SGM 采用约定+自主学习的方式来不断提高判断的准确率。我们约定成功用一个或多个「0」表示,但是如果某接口长期返回某一个返回码占据90%以上,并且无关联故障发生时,则会被认为这个返回码表示成功。
SGM 提供了强大的告警功能和灵活多样的配置方式。如下图:

▲图23 SGM 提供了强大的告警功能和灵活多样的配置方式
1)告警类别
SGM 提供性能报警、失败率报警、返回码报警、调用量报警、JVM 报警、应用存活报警、慢 SQL 报警、TCP 连接报警等多种报警类型。
2)配置灵活
SGM 告警除了支持传统的固定阈值方式外还支持基线。

▲图24 固定阈值告警

▲图25 基于基线告警
3)告警收敛
SGM 支持按时间维度和告警频度收敛,将大量重复的告警事件压缩为一条有真正意义的告警。而后通过属性关联、 机器学习等算法把相关的告警合并起来,为运维人员提供分析、甄选之后的最重要的告警。
4)故障范围诊断
SGM 针对调用链海量数据进行分析处理,梳理应用间、服务间、方法间依赖强度(强依赖、弱依赖)、依赖频度(高频依赖、低频依赖)关系,并据此进行故障范围的诊断,提高线上问题定位处理速度。
5)ROOT 告警
ROOT 告警(也称根源告警)是基于网络拓扑,结合调用链,通过时间相关性、面积权重等算法,将监控告警进行分类筛选,发掘有业务价值的告警,并直接分析出告警根源。
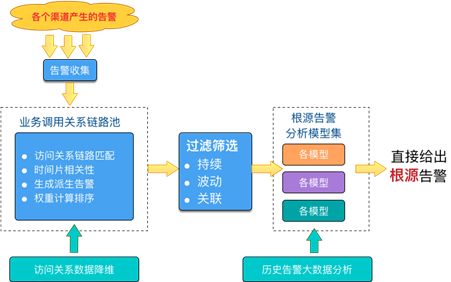
▲图26 ROOT 告警原理图
6)智能容量规划
业务规模的不断扩大,使得成本和质量之间的矛盾越发突出,这种矛盾在大促和业务大规模扩展的情况下变得尤为尖锐。
传统的容量规划主要是依靠定期的线上压测或者线下压测换算的方式进行。SGM 在此基础上还综合调用链、性能、成功率、CPU、远程(RPC、数据库、缓存)等实际数据进行拟合分析,通过与水位线的比对给出扩容缩容建议。
▲图27 智能容量规划示意图
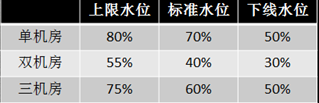
▲图28 智能容量规划水位标准图示意
SGM应用案例
某日收到告警某应用特定 ip 的 avg 超过阈值。
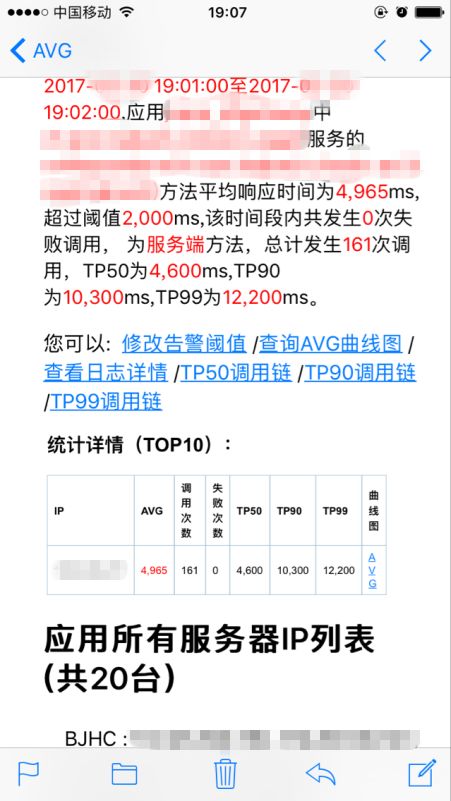
▲图29 告警详情
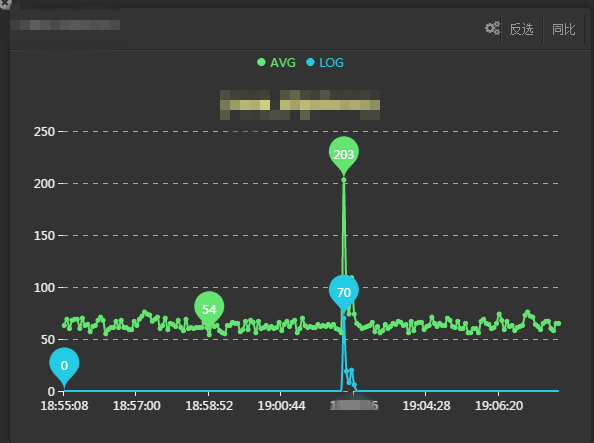
分析报警服务器的性能曲线,在19:02分左右该服务器出现时延突增情况,随后恢复正常,可排除服务器异常所致。

▲图30 问题 IP 性能曲线
进一步查看耗时分析,发现该突增时延是由于写日志所致,需进一步核查问题时段日志记录的内容。
▲图31 耗时分析
某日收到大量报警,通过故障范围针对,快速定位根本原因为某数据库服务器异常所致。
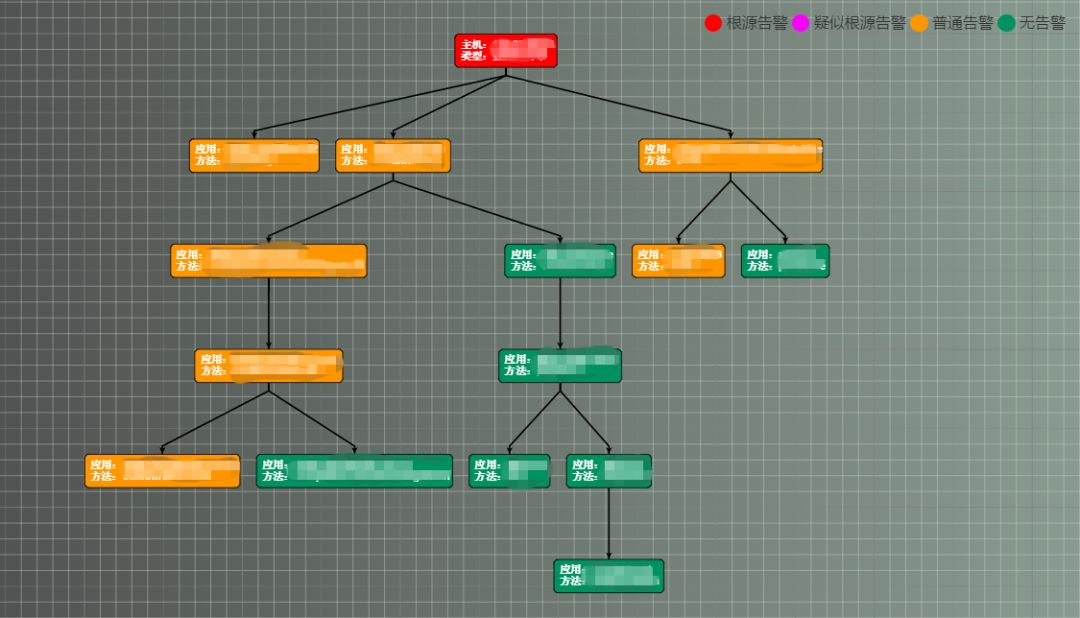
▲图32 故障范围诊断
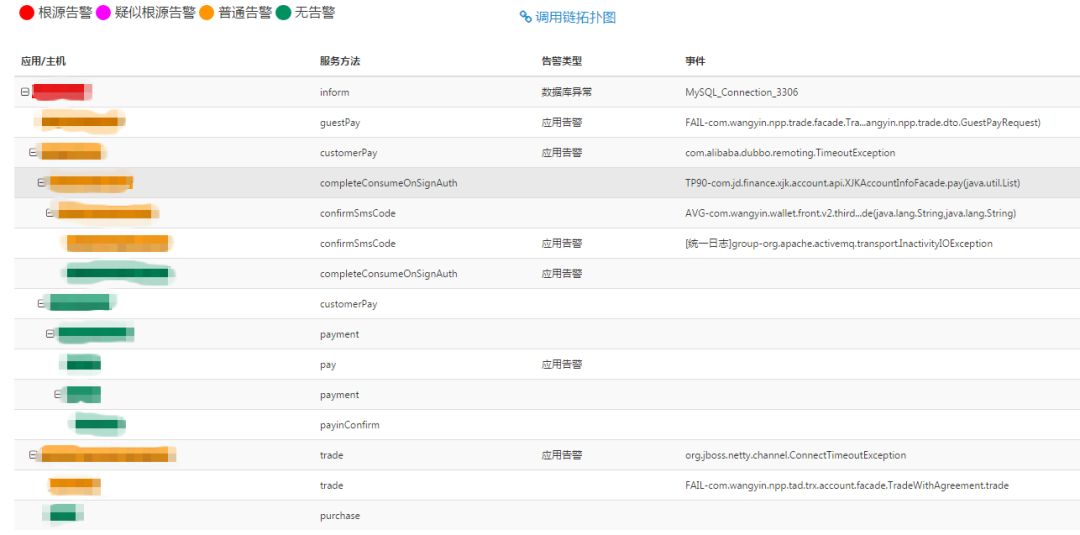
▲图33 故障范围明细表
SGM系统的未来之路
监控系统的建设就像攀登一座高山,而这座山上除了有陡峭的山坡之外,还存在着沼泽和很多的未知。我们正在不断探索新的方法去攀登征服这座高山。
---------------END----------------
后续的内容同样精彩
长按关注“IT实战联盟”哦

注意:本文归作者所有,未经作者允许,不得转载

