内存作为计算机程序运行最重要的资源之一,需要运行过程中做到合理的资源分配与回收,不合理的内存占用轻则使得用户应用程序运行卡顿、ANR、黑屏,重则导致用户应用程序发生 OOM(out of memory)崩溃。抖音作为一款用户使用广泛的产品,需要在各种机器资源上保持优秀的流畅性和稳定性,内存优化是必须要重视的环节。
本文从抖音 Java OOM 内存优化的治理实践出发,尝试给大家分享一下抖音团队关于 Java 内存优化中的一些思考,包括工具建设、优化方法论。
抖音 Java OOM 背景
在未对抖音内存进行专项治理之前我们梳理了一下整体内存指标的绝对值和相对崩溃,发现占比都很高。另外,内存相关指标在去年春节活动时又再次激增达到历史新高,所以整体来看内存问题相当严峻,必须要对其进行专项治理。抖音这边通过前期归因、工具建设以及投入一个双月的内存专项治理将整体 Java OOM 优化了百分之 80。
Java OOM Top 堆栈归因
在对抖音的 Java 内存优化治理之前我们先根据平台上报的堆栈异常对当前的 OOM 进行归因,主要分为下面几类:
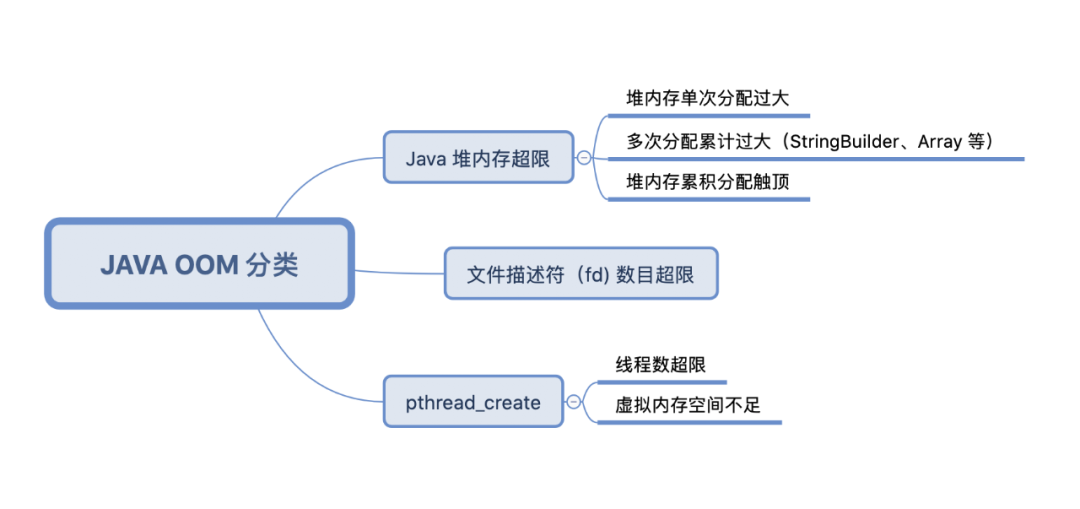
图 1. OOM 分类
其中 pthread_create 问题占到了总比例大约在百分之 50,Java 堆内存超限为百分之 40 多,剩下是少量的 fd 数量超限。其中 pthread_create 和 fd 数量不足均为 native 内存限制导致的 Java 层崩溃,我们对这部分的内存问题也做了针对性优化,主要包括:
- 线程收敛、监控
- 线程栈泄漏自动修复
- FD 泄漏监控
- 虚拟内存监控、优化
- 抖音 64 位专项
治理之后 pthread_create 问题降低到了 0.02‰以下,这方面的治理实践会在下一篇抖音 Native 内存治理实践中详细介绍,大家敬请期待。本文重点介绍 Java 堆内存治理。
堆内存治理思路
从 Java 堆内存超限的分类来看,主要有两类问题:
1. 堆内存单次分配过大/多次分配累计过大。
触发这类问题的原因有数据异常导致单次内存分配过大超限,也有一些是 StringBuilder 拼接累计大小过大导致等等。这类问题的解决思路比较简单,问题就在当前的堆栈。
2. 堆内存累积分配触顶。
这类问题的问题堆栈会比较分散,在任何内存分配的场景上都有可能会被触发,那些高频的内存分配节点发生的概率会更高,比如 Bitmap 分配内存。这类 OOM 的根本原因是内存累积占用过多,而当前的堆栈只是压死骆驼的最后一根稻草,并不是问题的根本所在。所以这类问题我们需要分析整体的内存分配情况,从中找到不合理的内存使用(比如内存泄露、大对象、过多小对象、大图等)。
工具建设
工具思路
工欲善其事,必先利其器。从上面的内存治理思路看,工具需要主要解决的问题是分析整体的内存分配情况,发现不合理的内存使用(比如内存泄露、大对象、过多小对象等)。
我们从线下和线上两个维度来建设工具:
线下
线下工具是最先考虑的,在研发和测试的时候能够提前发现内存泄漏问题。业界的主流工具也是这个思路,比如 Android Studio Memory Profiler、LeakCanary、Memory Analyzer (MAT)。
我们基于 LeakCanary 核心库在线下设计了一套自动分析上报内存泄露的工具,主要流程如下:
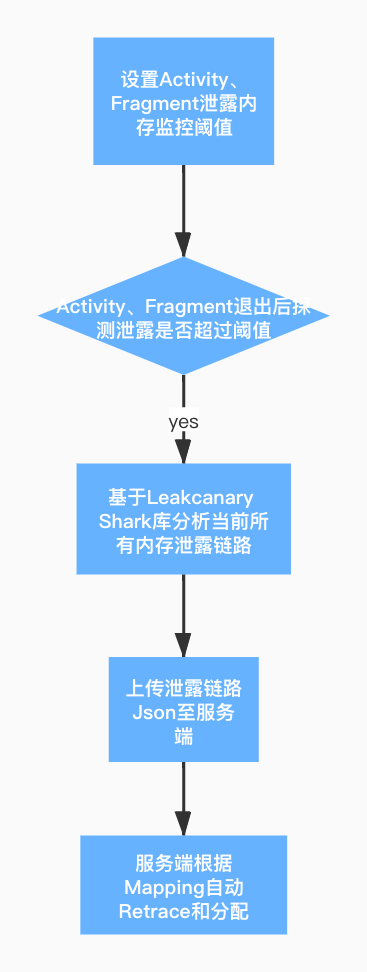
图 2.线下自动分析流程
抖音在运行了一段线下的内存泄漏工具之后,发现了线下工具的各种弊端:
- 检测出来的内存泄漏过多,并且也没有比较好的优先级排序,研发消费不过来,历史问题就一直堆积。另外也很难和业务研发沟通问题解决的收益,大家针对解决线下的内存泄漏问题的 ROI(投入产出比)比较难对齐。
- 线下场景能跑到的场景有限,很难把所有用户场景穷尽。抖音用户基数很大,我们经常遇到一些线上的 OOM 激增问题,因为缺少线上数据而无从查起。
- Android 端的 HPORF 的获取依赖原生的 Debug.dumpHporf,dump 过程会挂起主线程导致明显卡顿,线下使用体验较差,经常会有研发反馈影响测试。
- LeakCanary 基于 Shark 分析引擎分析,分析速度较慢,通常在 5 分钟以上才能分析完成,分析过程会影响进程内存占用。
- 分析结果较为单一,仅仅只能分析出 Fragment、Activity 内存泄露,像大对象、过多小对象问题导致的内存 OOM 无法分析。
线上
正是由于上述一些弊端,抖音最早的线下工具和治理流程并没有起到什么太大作用,我们不得不重新审视一下,工具建设的重心从线下转成了线上。线上工具的核心思路是:在发生 OOM 或者内存触顶等触发条件下,dump 内存的 HPROF 文件,对 HPROF 文件进行分析,分析出内存泄漏、大对象、小对象、图片问题并按照泄露链路自动归因,将大数据问题按照用户发生次数、泄露大小、总大小等纬度排序,推进业务研发按照优先级顺序来建立消费流程。为此我们研发了一套基于 HPORF 分析的线下、线上闭环的自动化分析工具 Liko(寓意 ko 内存 Leak 问题)。
Liko 介绍
Liko 整体架构
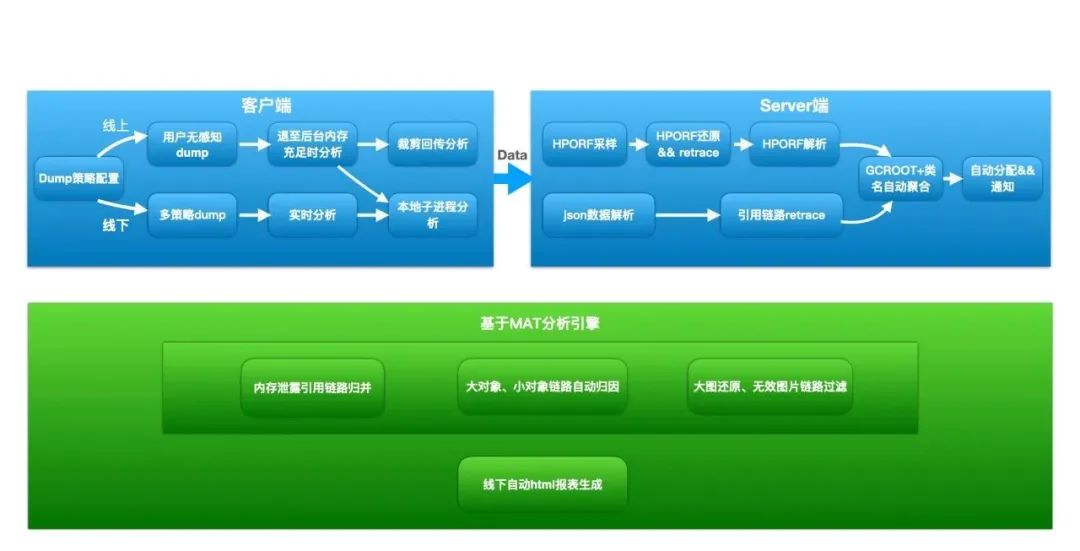
图 3. Liko 架构图
整体架构由客户端、Server 端和核心分析引擎三部分构成。
- 客户端
在客户端完成 HPROF 数据采集和分析(针对端上分析模式),这里线上和线下策略不同。
线上:主要在 OOM 和内存触顶时通过用户无感知 dump 来获取 HPROF 文件,当 App 退出到后台且内存充足的情况进行分析,为了尽量减少对 App 运行时影响,主要通过裁剪 HPROF 回传进行分析,减轻服务器压力,对部分比例用户采用端上分析作为 Backup。
线下:dump 策略配置较为激进,在 OOM、内存触顶、内存激增、监测 Activity、Fragment 泄漏数量达到一定阈值多种场景下触发 dump,并实时在端上分析上传至后台并在本地自动生成 html 报表,帮助研发提前发现可能存在的内存问题。
- Server 端
Server 端根据线上回传的大数据完成链路聚合、还原、分配,并根据用户发生次数、泄露大小、总大小等纬度促进研发测消费,对于回传分析模式则会另外进行 HPORF 分析。
- 分析引擎
基于 MAT 分析引擎完成内存泄露、大对象、小对象、图片等自动归因,同时支持在线下自动生成 Html 报表。
Liko 流程图
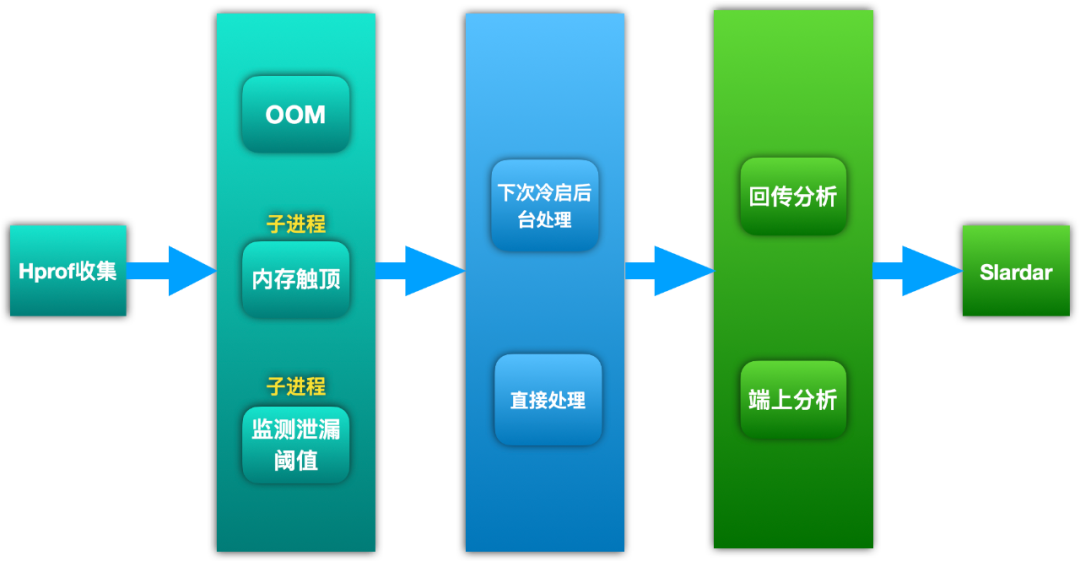
图 4. Liko 流程图
整体流程分为:
- Hprof 收集
- 分析时机
- 分析策略
Hprof 收集
收集过程我们设置了多种策略可以自由组合,主要有 OOM、内存触顶、内存激增、监测 Activity、Fragment 泄漏数量达到一定阈值时触发,线下线上策略配置不同。
为了解决 dump 挂起进程问题,我们采用了子进程 dump+fileObsever 的方式完成 dump 采集和监听。
在 fork 子进程之前先 Suspend 获取主进程中的线程拷贝,通过 fork 系统调用创建子进程让子进程拥有父进程的拷贝,然后 fork 出的子进程中调用 Hprof 的 DumpHeap 函数即可完成把耗时的 dump 操作在放在子进程。由于 suspend 和 resume 是系统函数,我们这里通过自研的 native hook 工具对 libart.so hook 获取系统调用。由于写入是在子进程完成的,我们通过 Android 提供的 fileObsever 文件写入进行监控获取 dump 完成时机。
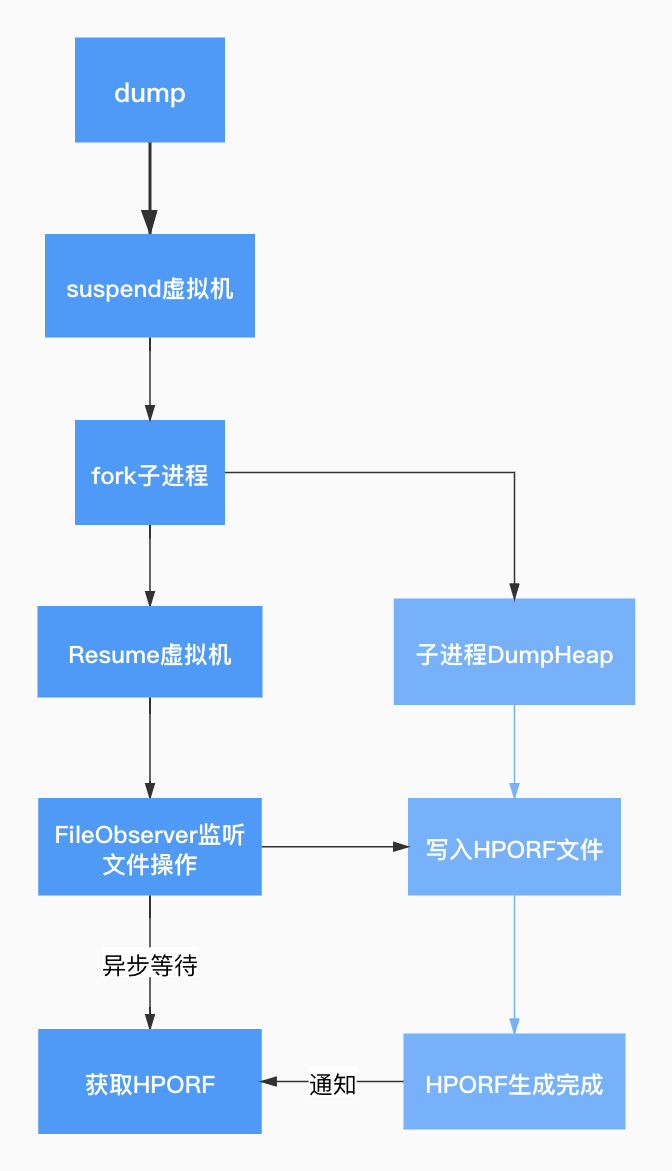
图 5.子进程 dump 流程图
Hprof 分析时机
为了达到分析过程对于用户无感,我们在线上、线下配置了不同的分析时机策略,线下在 dump 分析完成后根据内存状态主动触发分析,线上当用户下次冷启退出应用后台且内存充足的情况下触发分析。
分析策略
分析策略我们提供了两种,一种在 Android 客户端分析,一种回传至 Server 端分析,均通过 MAT 分析引擎进行分析。
端上分析
分析引擎
端上分析引擎的性能很重要,这里我们主要对比了 LeakCanary 的分析引擎 Shark 和 Haha 库的 MAT。
图 6. Shark VS MAT
我们在相同客户端环境对 160M 的 HPROF 多次分析对比发现 MAT 分析速度明显优于 Shark,另外针对 MAT 分析后仍持有统治者树占用内存我们也做了主动释放,对比性能收益后采用基于 MAT 库的分析引擎进行分析,对内存泄漏引用链路自动归并、大对象小对象引用链自动分析、大图线下自动还原线上过滤无用链路,分析结果如下:
内存泄漏
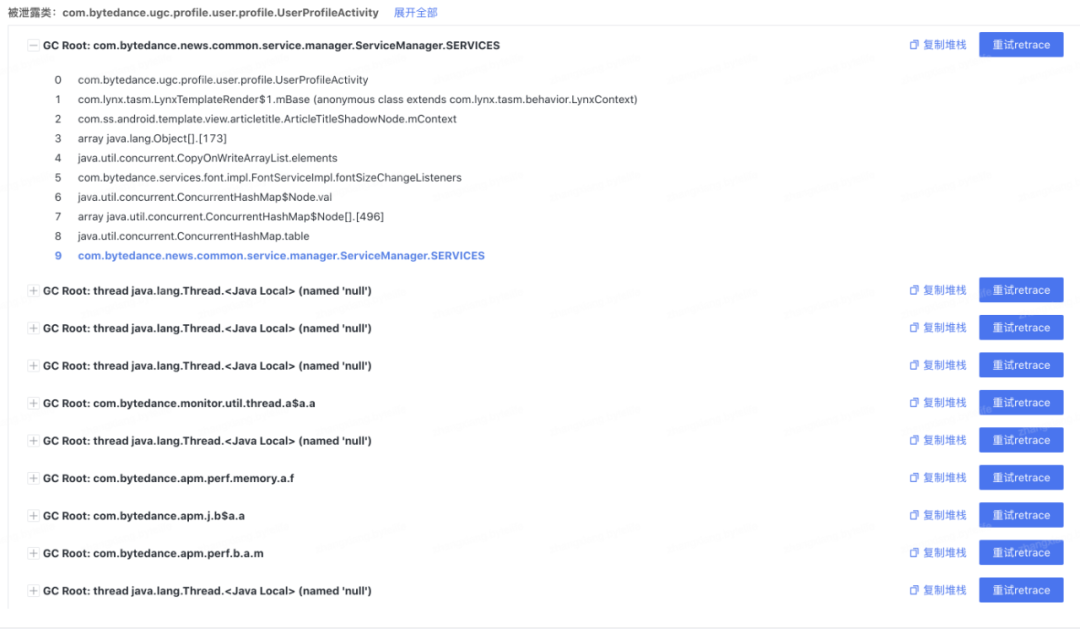
图 7. 内存泄漏链路
对泄漏的 Activity 的引用链进行了聚合分析,方便一次性解决该 Activity 的泄漏链释放内存。
大对象
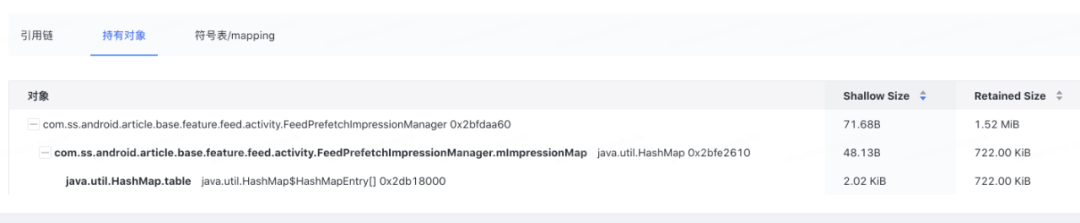
图 8. 大对象链路
大对象不止分析了引用链路,还递归分析了内部 top 持有对象(InRefrenrece)的 RetainedSize。
小对象
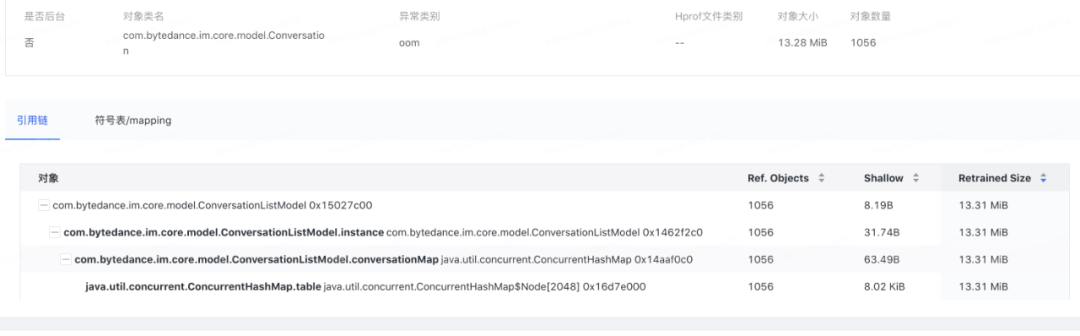
图 9. 小对象链路
小对象我们对 top 的外部持有对象(OutRefrenrece)进行聚合得到占有小对象最多的链路。
图片
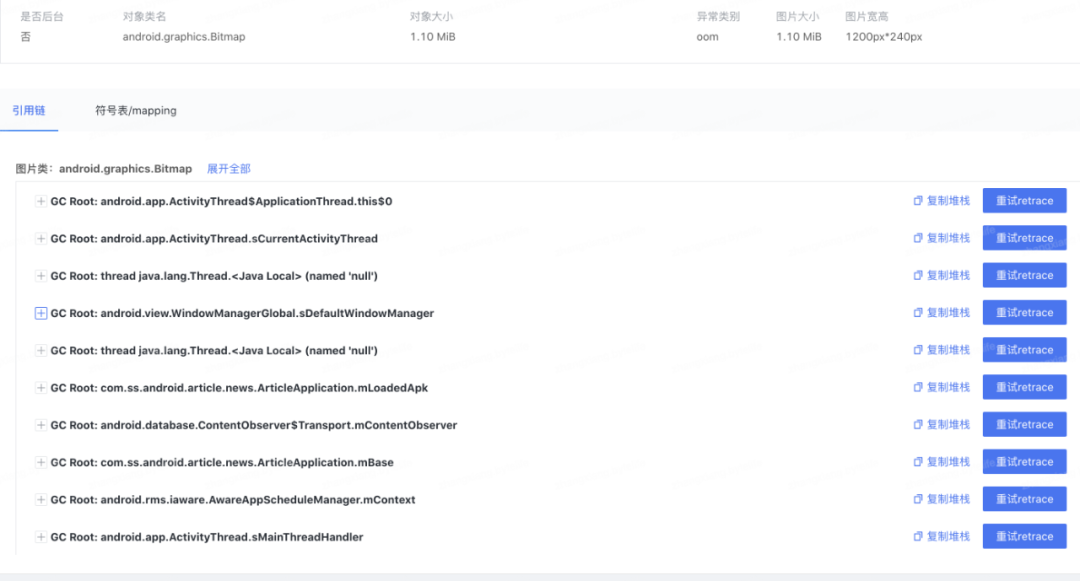
图 10. 图片链路
图片我们过滤了图片库等无效引用且对 Android 8.0 以下的大图在线下进行了还原。
回传分析
为了最大限度的节省用户流量且规避隐私风险,我们通过自研 HPROF 裁剪工具 Tailor 在 dump 过程对 HPROF 进行了裁剪。
裁剪过程
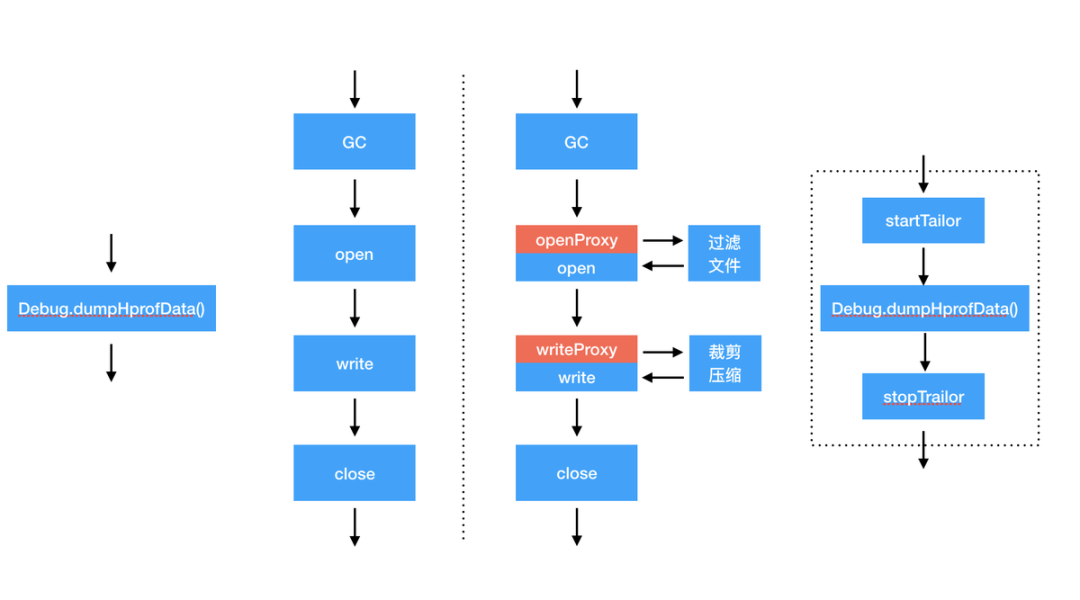
图 11. Tailor 裁剪流程
去除了无用信息
- 跳过 header
- 分 tag 裁剪
- 裁剪无用信息:char[]; byte[]; timestamp; stack trace serial number; class serial number;
- 压缩数据信息
同时对数据进行 zlib 压缩,在 server 端数据还原,整体裁剪效果:180M--->50M---->13M
优化实践
内存泄漏
除了通过后台根据 GCROOT+ 引用链自动分配研发跟进解决我们常见的内存泄漏外,我们还对系统导致一些内存泄漏进行了分析和修复。
系统异步 UI 泄漏
根据上传聚合的引用链我们发现在 Android 6.0 以下有一个 HandlerThread 作为 GCROOT 持有大量 Activity 导致内存泄漏,根据引用发现这些泄漏的 Activity 都被一个 Runnable(这里是 Runnable 是一个系统事件 SendViewStateChangedAccessibilityEvent)持有,这些 Runnable 被添加到一个 RunQueuel 中,这个队列本身被 TheadLocal 持有。

图 12. HandlerThread 泄露链路
我们从 SendViewStateChangedAccessibilityEvent 入手对源码进行了分析发现它在 notifyViewAccessibilityStateChangedIfNeeded 中被抛出,系统的大量 view 都会在自身的一些 UI 方法(eg: setChecked)中触发该函数。
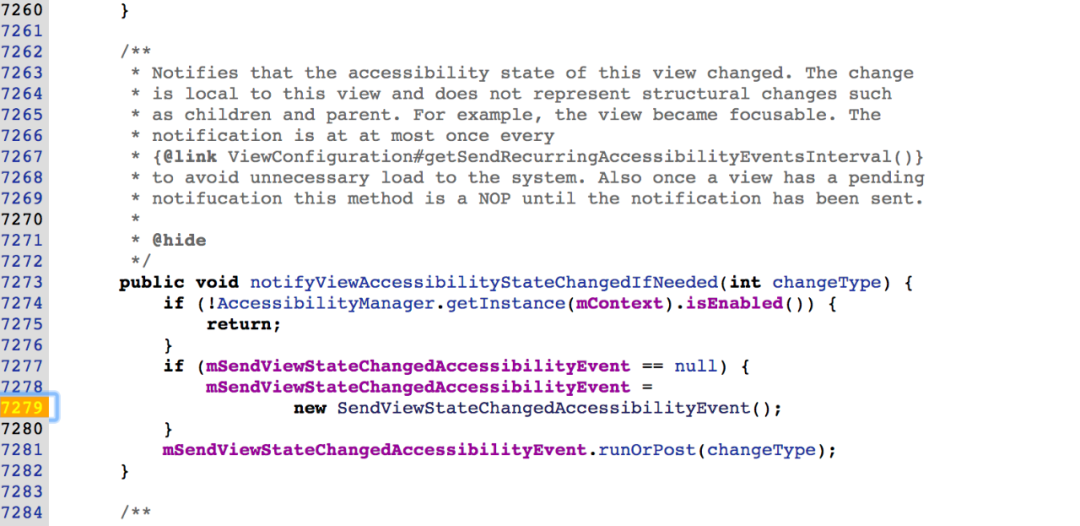
SendViewStateChangedAccessibilityEvent 的 runOrPost 方法会走到我们常用的 View 的 postDelay 方法中,这个方法在当 view 还未被 attched 到根 view 的时候会加入到一个 runQueue 中。

这个 runQueue 会在主线程下一次的 performTraversals() 中消费掉。

如果这个 runQueue 不在主线程那就没有消费的机会。
根据上面的分析发现造成这种内存泄漏需要满足一些条件:
- view 调用了 postDelay 方法 (这里是 notifyViewAccessisbilityStateChangeIfNeeded 触发)
- view 处于 detached 状态
- 上述过程是在非主线程里面操作的,ThreadLocal 非 UIThread,持有的 runQueue 不会走 performTraversals 消费掉。
抖音这边大量使用了异步 UI 框架来优化渲染性能,框架内部由一个 HandlerThread 驱动,完全符合上述条件。针对该问题,我们通过反射获取非主线程的 ThreadLocal,在每次异步渲染完主动清理内部的 RunQueue。
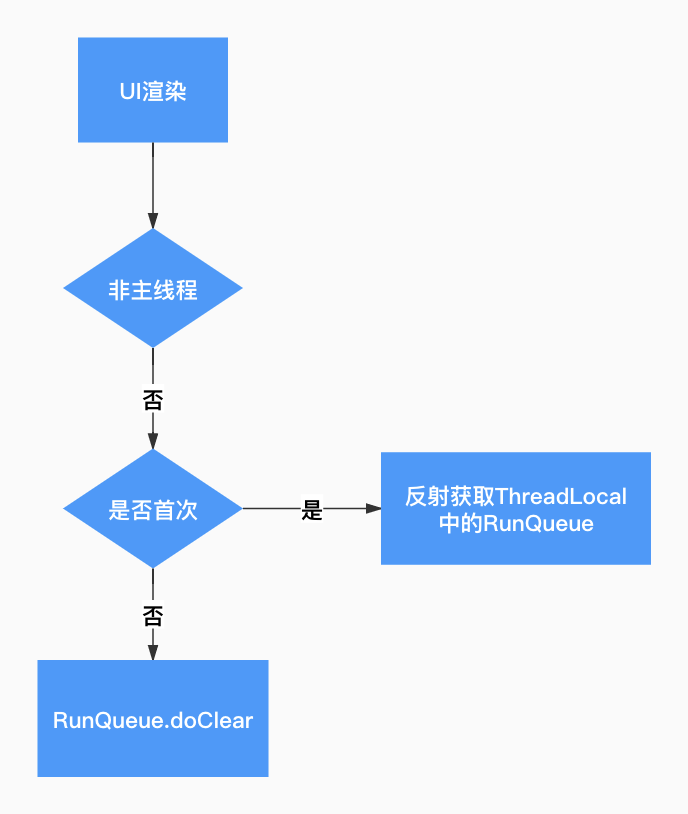
图 13. 反射清理流程
另外,Google 在 6.0 上也修复了 notifyViewAccessisbilityStateChangeIfNeeded 的判断不严谨问题。

内存泄漏兜底
大量的内存泄漏,如果我们都靠推进研发解决,经常会出现生产大于消费的情况,针对这些未被消费的内存泄漏我们在客户端做了监控和止损,将 onDestory 的 Activity 添加到 WeakRerefrence 中,延迟 60s 监控是否回收,未回收则主动释放泄漏的 Activity 持有的 ViewTree 的背景图和 ImageView 图片。
大对象
主要对三种类型的大对象进行优化
- 全局缓存:针对全局缓存我们按需释放和降级了不需要的缓存,尽量使用弱引用代替强引用关系,比如针对频繁泄漏的 EventBus 我们将内部的订阅者关系改为弱引用解决了大量的 EventBus 泄漏。
- 系统大对象:系统大对象如 PreloadDrawable、JarFile 我们通过源码分析确定主动释放并不干扰原有逻辑,在启动完成或在内存触顶时主动反射释放。
- 动画:用原生动画代替了内存占用较大的帧动画,并对 Lottie 动画泄漏做了手动释放。
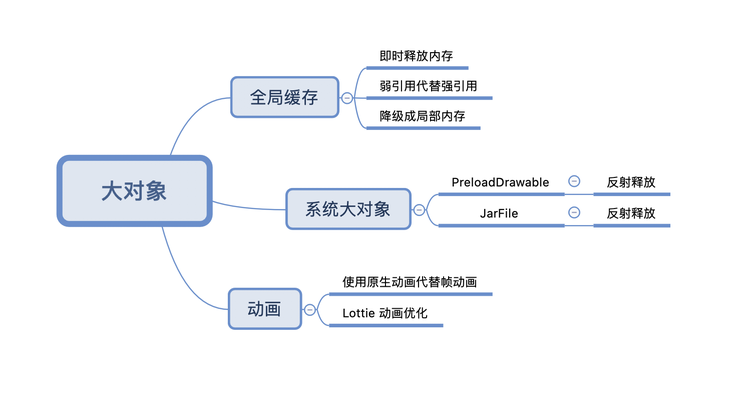
图 14. 大对象优化点
小对象
小对象优化我们集中在字段优化、业务优化、缓存优化三个纬度,不同的纬度有不同的优化策略。
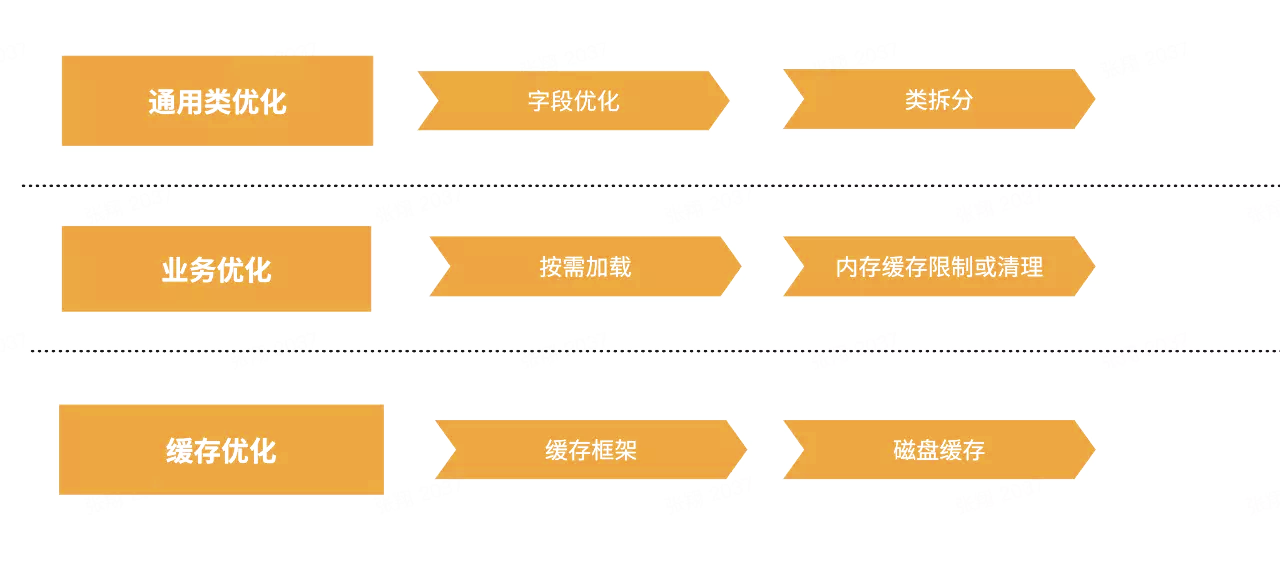
图 15. 小对象优化思路
通用类优化
在抖音的业务中,视频是最核心且通用的 Model,抖音业务层的数据存储分散在各个业务维护了各自视频的 Model,Model 本身由于聚合了各个业务需要的属性很多导致单个实例内存占用就不低,随着用户使用过程实例增长内存占用越来越大。对 Model 本身我们可以从属性优化和拆分这两种思路来优化。
- 字段优化:针对一次性的属性字段,在使用完之后及时清理掉缓存,比如在视频 Model 内部存在一个 Json 对象,在反序列完成之后 Json 对象就没有使用价值了,可以及时清理。
- 类拆分:针对通用 Model 冗杂过多的业务属性,尝试对 Model 本身进行治理,将各个业务线需要用到的属性进行梳理,将 Model 拆分成多个业务 Model 和一个通用 Model,采用组合的方式让各个业务线最小化依赖自己的业务 Model,减少大杂烩 Model 不必要的内存浪费。
业务优化
- 按需加载:抖音这边 IM 会全局保存会话,App 启动时会一次性 Load 所有会话,当用户的会话过多时相应全局占用的内存就会较大,为了解决该问题,会话列表分两次加载,首次只加载一定数量到内存,需要时再加载全部。
- 内存缓存限制或清理:首页推荐列表的每一次 Loadmore 操作,都不会清理之前缓存起来的视频对象,导致用户长时间停留在推荐 Feed 时,缓存起来的视频对象过多会导致内存方面的压力。在通过实验验证不会对业务产生负面影响情况下对首页的缓存进行了一定数量的限制来减小内存压力。
缓存优化
上面提到的视频 Model,抖音最早使用 Manager 来管理通用的视频实例。Manager 使用 HashMap 存储了所有的视频对象,最初的方案里面没有对内存大小进行限制且没有清除逻辑,随着使用时间的增加而不断膨胀,最终出现 OOM 异常。为了解决视频 Model 无限膨胀的问题设计了一套缓存框架主要流程如下:
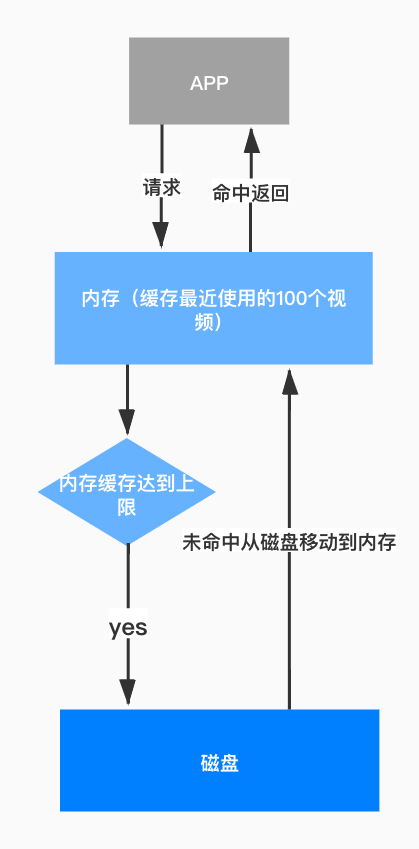
图 16. 视频缓存框架
使用 LRU 缓存机制来缓存视频对象。在内存中缓存最近使用的 100 个视频对象,当视频对象从内存缓存中移除时,将其缓存至磁盘中。在获取视频对象时,首先从内存中获取,若内存中没有缓存该对象,则从磁盘缓存中获取。在退出 App 时,清除 Manager 的磁盘缓存,避免磁盘空间占用不断增长。
图片
关于图片优化,我们主要从图片库的管理和图片本身优化两个方面思考。同时对不合理的图片使用也做了兜底和监控。
图片库
针对应用内图片的使用状况对图片库设置了合理的缓存,同时在应用 or 系统内存吃紧的情况下主动释放图片缓存。
图片自身优化
我们知道图片内存大小公式 = 图片分辨率 * 每个像素点的大小。
图片分辨率我们通过设置合理的采样来减少不必要的像素浪费。
//开启采样
ImagePipelineConfig config = ImagePipelineConfig.newBuilder(context)
.setDownsampleEnabled(true)
.build();
Fresco.initialize(context, config);
//请求图片时,传入resize的大小,一般直接取View的宽高
ImageRequest request = ImageRequestBuilder.newBuilderWithSource(uri)
.setResizeOptions(new ResizeOptions(50, 50))
.build();mSimpleDraweeView.setController(
Fresco.newDraweeControllerBuilder()
.setOldController(mSimpleDraweeView.getController())
.setImageRequest(request)
.build());
而单个像素大小,我们通过替换系统 drawable 默认色彩通道,将部分没有透明通道的图片格式由 ARGB_8888 替换为 RGB565,在图片质量上的损失几乎肉眼不可见,而在内存上可以直接节省一半。
图片兜底
针对因 activity、fragment 泄漏导致的图片泄漏,我们在 onDetachedFromWindow 时机进行了监控和兜底,具体流程如下:
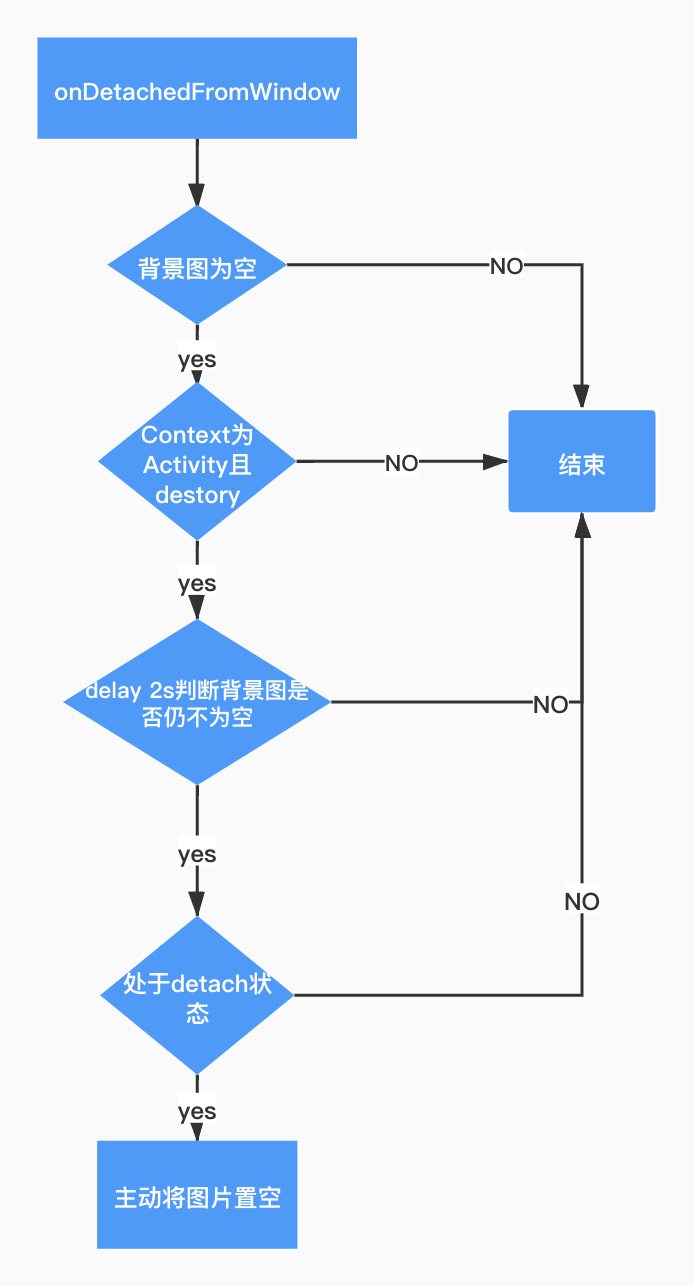
图 17. 图片兜底流程
图片监控
关于对不合理的大图 or 图片使用我们在字节码层面进行了拦截和监控,在原生 Bitmap or 图片库创建时机记录图片信息,对不合理的大图进行上报;另外在 ImageView 的设置过程中针对 Bitmap 远超过 view 本身超过大小的场景也进行了记录和上报。
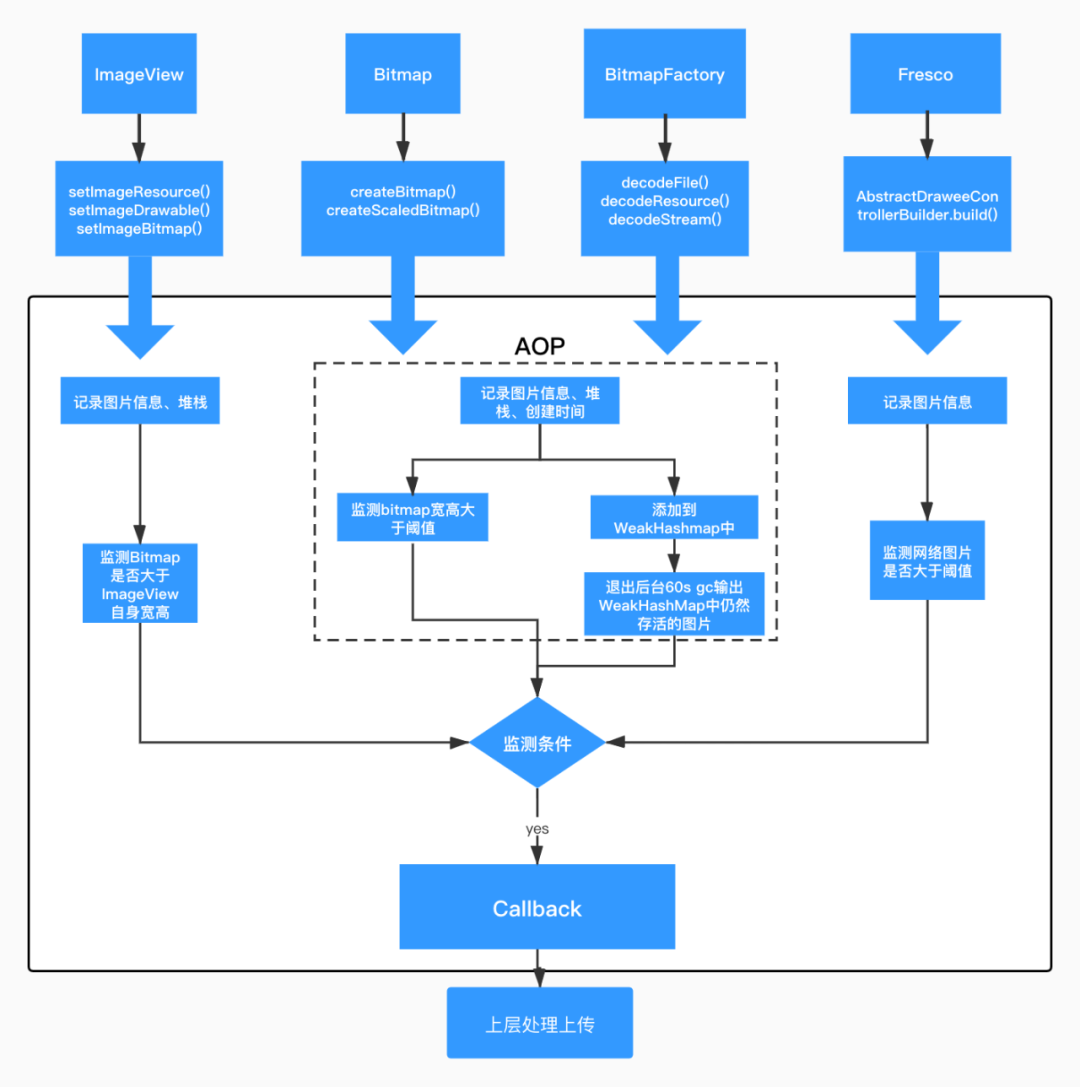
图 18. 图片字节码监控方案
更多思考
是不是解决了 OOM 内存问题就告一段落了呢?作为一只追求极致的团队,我们除了解决静态的内存占用外也自研了 Kenzo(Memory Insight)工具尝试解决动态内存分配造成的 GC 卡顿。
Kenzo 原理
Kenzo 采用 JVMTI 完成对内存监控工作,JVMTI(JVM Tool Interface)是 Java 虚拟机所提供的 native 编程接口。JVMTI 开发时,应用建立一个 Agent 使用 JVMTI,可以使用 JVMTI 函数,设置回调函数,并从 Java 虚拟机中得到当前的运行态信息,并作出自己的业务判断。
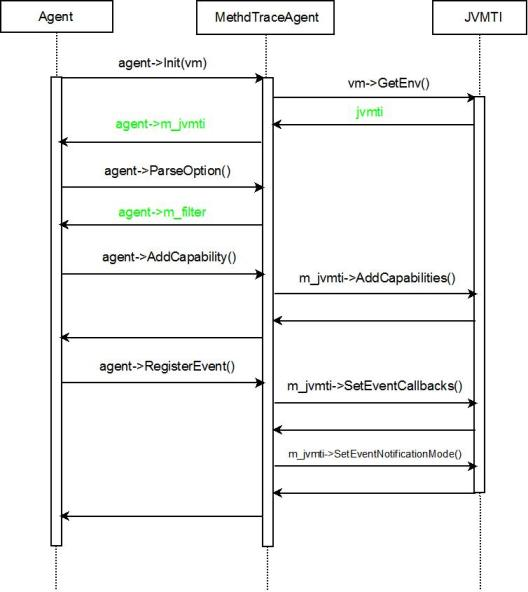
图 19. Agent 时序图
Jvmti SetEventCallbacks 方法可以设置目标虚拟机内部事件回调,可以根据 jvmtiCapabilities 支持的能力和我们关注的事件来定义需要 hook 的事件。
Kenzo 采用 Jvmti 完成如下事件回调:
- 类加载准备事件 -> 监控类加载
- ClassPrepare:某个类的准备阶段完成。
- GC -> 监控 GC 事件与时间
- GarbageCollectionStart:GC 启动时。
- GarbageCollectionFinish:GC 结束后。
- 对象事件 -> 监控内存分配
- ObjectFree:GC 释放一个对象时。
- VMObjectAlloc:虚拟机分配一个对象的时候。
框架设计
Kenzo 整体分为两个部分:
生产端
- 采集内存数据
- 以 sdk 形式集成到宿主 App
消费端
- 处理生产端的数据
- 输入 Kenzo 监控的内存数据
- 输出可视化报表
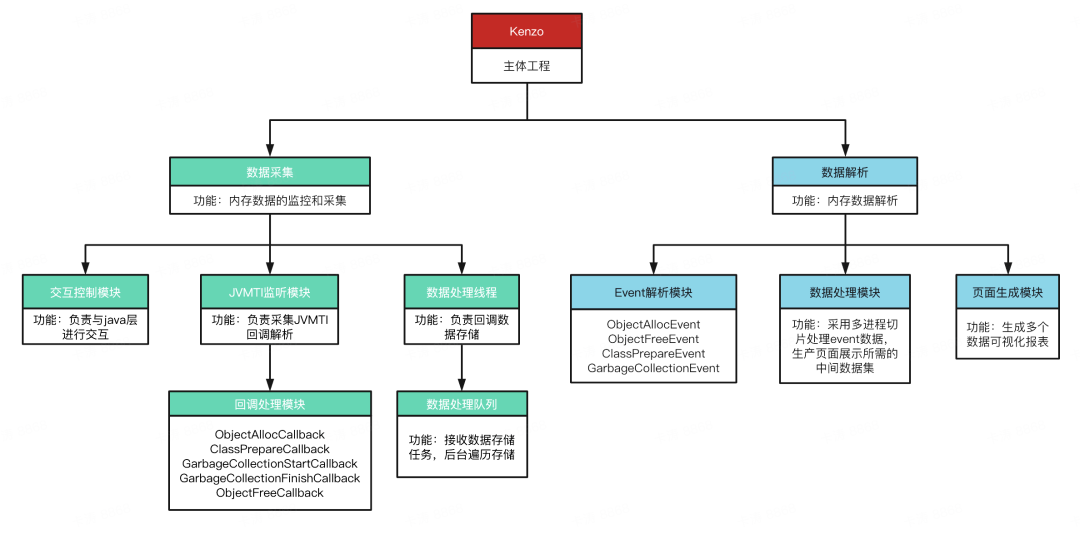
图 20. kenzo 框架
生产端主要以 Java 进行 API 调用,C++完成底层检测逻辑,通过 JNI 完成底层逻辑控制。
消费端主要以 Python 完成数据的解析、视图合成,以 HTML 完成页面内容展示。
工作流
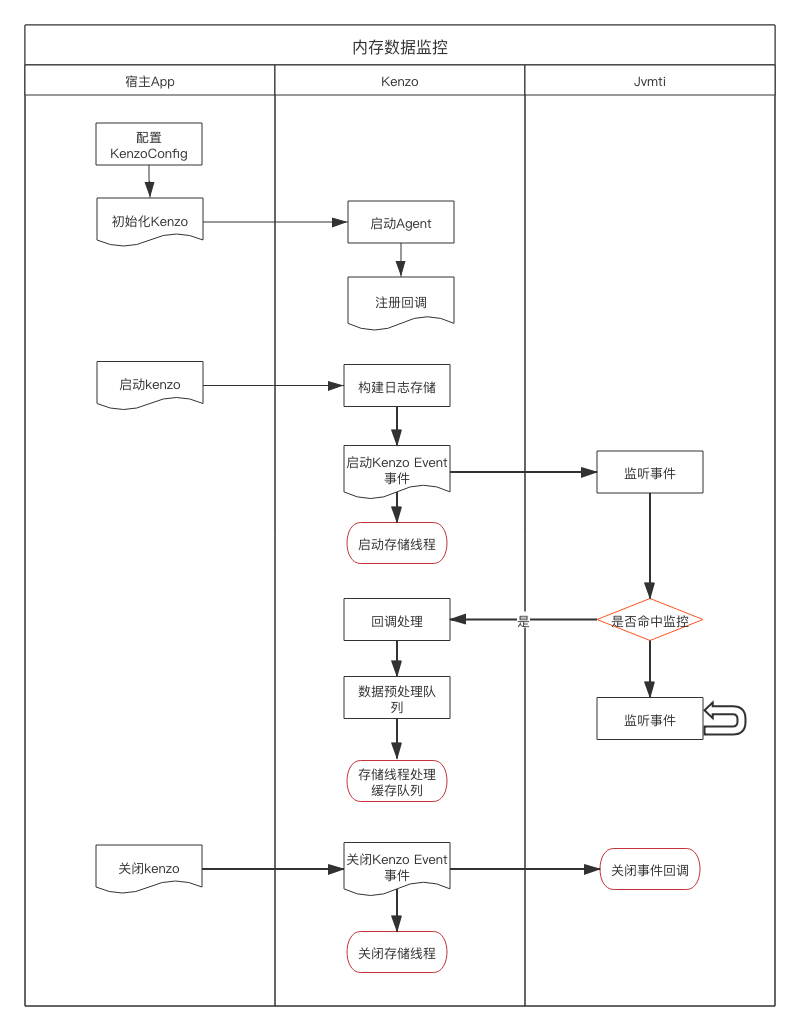
图 21. kenzo 框架
可视化展示
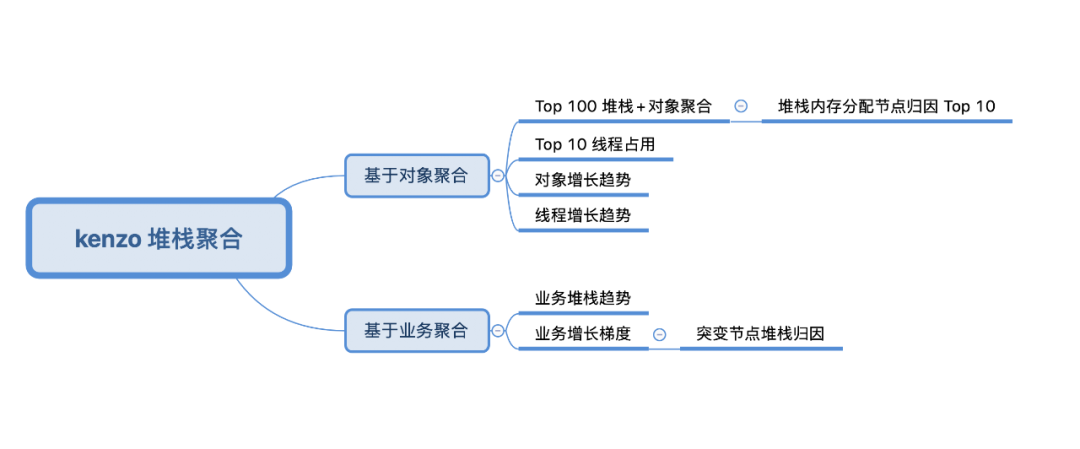
图 22. kenzo 聚合展示
启动阶段内存归因
基于动态内存监控我们对最为核心的启动场景的内存分配进行了归因分析,优化了一些头部的内存节点分配:

图 23.启动阶段内存节点归因
另外我们也发现启动阶段存在大量的字符串拼接操作,虽然编译器已经优化成了 StringBuider append,但是深入 StringBuider 源码分析仍在存在大量的动态扩容动作(System.copy),为了优化高频场景触发动态扩容的性能损耗,在 StringBuilder 在 append的时候,不直接往 char[] 里塞东西,而是先拿一个 String[] 把它们都存起来,到了最后才把所有 String 的 length 加起来,构造一个合理长度的 StringBuilder。通过使用编译时字节码替换的方式,替换所有 StringBuilder 的 append 方法使用自定义实现,优化后首次安装首页 Feed 滑动 1min 的 FPS 提升 1 帧/S,非首次安装启动,滑动 1min 的 FPS 提升 0.6 帧/S。
注意:本文归作者所有,未经作者允许,不得转载

