来自:https://www.toutiao.com/a6609515667714474503
作者:codeMyWorld

netty
关于netty的学习和介绍,可以去github看官方文档,这里良心推荐《netty实战》和《netty权威指南》两本书,前者对于新手更友好,原理和应用都有讲到,多读读会发现很多高性能的优化点。
netty高性能优化点
最近参加了阿里中间价性能比赛,为了提升netty写的servive mesh的网络通信的性能,最近几天查了书、博客(这里强力推荐netty作者的博客,干货真的很多),自己总结了如下一下优化点。如果有错误希望能指正。
注:这里所讨论的对应的netty版本为netty4
首先要明确要netty优化的几个主要的关注点。
减少线程切换的开销。
复用channel,可以选择池化channel
zero copy的应用
减少并发下的竞态情况
接下来将细数一下总结的优化点
1. 尽可能的复用EventLoopGroup。
这里就要涉及netty的线程模型了。netty实战的第七章里有很细致的阐释。简单说EventLoopGroup包含了指定数量(如果没有指定,默认是cpu核数的两倍,可以从源码中看到)的EvenetLoop,Eve netLoop和channel的关系是一对多,一个channel被分配给一个EventLoop,它生命周期中都会使用这个EventLoop,而EventLoop背后就是线程。见下图。
因此如果需要使用ThreadLocal保存上下文,那么许多channel就会共享同一个上下文。

因此不需要每次都new出一个EventLoopGroup,其本质上是线程分配,可以复用同一个EventLoopGroup,减少资源的使用和线程的切换。特别是在服务端引导一个客户端连接的时候。如下:
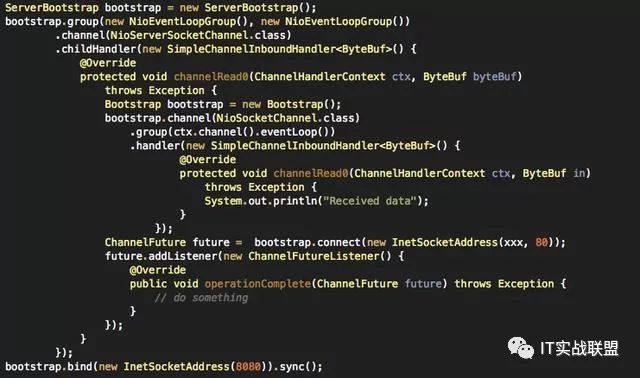
2. 使用EventLoop的任务调度
在EventLoop的支持线程外使用channel,用

而不是直接使用channel.writeAndFlush(data);
前者会直接放入channel所对应的EventLoop的执行队列,而后者会导致线程的切换。
3. 减少ChannelPipline的调用长度
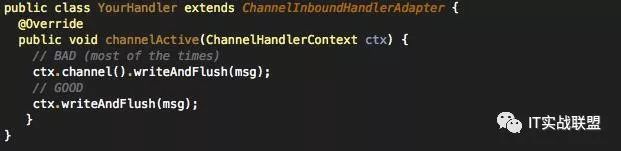
前者是将msg从整个ChannelPipline中走一遍,所有的handler都要经过,而后者是从当前handler一直到pipline的尾部,调用更短。
同样,为了减少pipline的长度,如果一个handler只需要使用一次,那么可以在使用过之后,将其从pipline中remove。
4. 减少ChannelHandler的创建
如果channelhandler是无状态的(即不需要保存任何状态参数),那么使用Sharable注解,并在bootstrap时只创建一个实例,减少GC。否则每次连接都会new出handler对象。
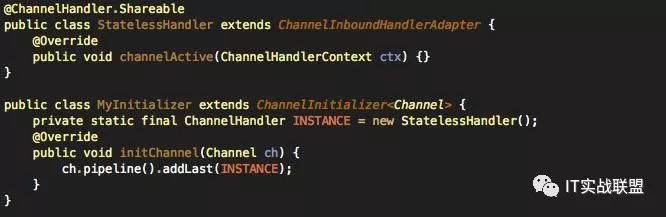
同时需要注意ByteToMessageDecoder之类的编解码器是有状态的,不能使用Sharable注解。
5. 减少系统调用(Flush)的调用
flush操作是将消息发送出去,会引起系统调用,应该尽量减少flush操作,减少系统调用的开销。
同时也要减少write的操作, 因为这样消息会流过整个ChannelPipline。
6. 使用单链接
对于两个指定的端点可以使用单一的channel,在第一次创建之后保存channel,然后下次对于同一个IP地址可以复用该channel而不需要重新建立。
你可能需要一个map来保存对于不同ip的channel,但是在初始化时这可能会有一些线程并发的问题。在这篇微信推文(https://mp.weixin.qq.com/s/JRsbK1Un2av9GKmJ8DK7IQ)中有提到对于这个的解决方案,在蚂蚁金服的sofa-bolt项目中有类似情形,不过不太理解。

7. 利用netty零拷贝,在IO操作时使用池化的DirectBuffer
在bootstrap配置参数的时候,使用.option(ChannelOption.ALLOCATOR, PooledByteBufAllocator.DEFAULT)来指定一个池化的Allocator,并且使用ByteBuf buf = allocator.directBuffer();来获取Bytebuf。
PooledByteBufAllocator,netty会帮你复用(无需release,除非你后面还需要用到同一个bytebuf)而不是每次都重新分配ByteBuf。在IO操作中,分配直接内存而不是JVM的堆空间,就避免了在发送数据时,从JVM到直接内存的拷贝过程,这也就是zero copy的含义。
8. 一些配置参数的设置
ServerBootstrap启动时,通常 bossGroup 只需要设置为 1 即可,因为 ServerSocketChannel 在初始化阶段,只会注册到某一个 eventLoop 上,而这个 eventLoop 只会有一个线程在运行,所以没有必要设置为多线程。而 IO 线程,为了充分利用 CPU,同时考虑减少线上下文切换的开销,通常设置为 CPU 核数的两倍,这也是 Netty 提供的默认值。
在对于响应时间有高要求的场景,使用.childOption(ChannelOption.TCP_NODELAY, true)和.option(ChannelOption.TCP_NODELAY, true)来禁用nagle算法,不等待,立即发送。
9. 小心的使用并发编程技巧
千万不要阻塞EventLoop!包括了Thead.sleep() CountDownLatch 和一些耗时的操作等等,尽量使用netty中的各种future。如果必须尽量减少重量级的锁的的使用。
在使用volatile时,
坏的:

好的:先将volatile变量保存到方法栈中,jdk源码中大量的使用了这种技巧。

使用Atomic*FieldUpdater替换Atomic*。关于这个可以参考http://normanmaurer.me/blog/2013/10/28/Lesser-known-concurrent-classes-Part-1/。简单说,如果使用Atomic*,对于每个连接都会创建一个对象,而如果使用Atomic*FieldUpdater则会省去这部分的开销,只有一个static final变量。

10. 响应顺序的处理
当使用了单链接,就有一个必须要解决的问题,将请求和响应顺序对应起来。因为所有的操作都是异步的,TCP是基于字节流的,所以channel接收到的数据无法保证和发送顺序一致。这个的解决方案就是,对于每个请求指定一个id,对于响应也携带该id。如果后发的请求的响应先到,则将其缓存起来(可以使用一个并发的队列),然后等待该id之前的所有响应全部接收到,再按序返回。
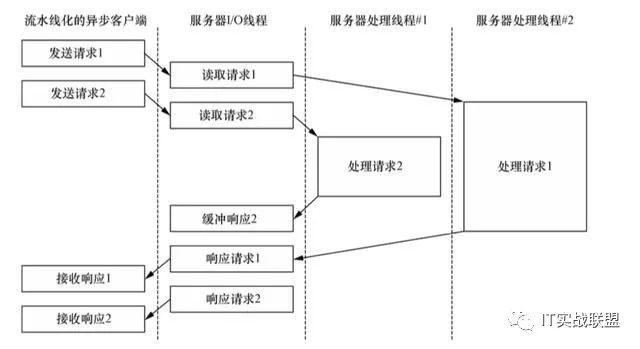
具体实现可以参见nifty中的NiftyDispatcher类。
---------------END----------------
后续的内容同样精彩
长按关注“IT实战联盟”哦

注意:本文归作者所有,未经作者允许,不得转载

