 来这里找志同道合的小伙伴!
来这里找志同道合的小伙伴!
JMQ是京东中间件团队自研的消息中间件,诞生于2014年,服务京东近万个应用,2018年11.11大促期间的峰值流量超过5000亿条消息。
2018年,JMQ完成第四次大版本的迭代,在性能上有极大的提升,单个Broker节点的写入性能超过100万TPS。
在相同的硬件环境下,选取2个典型的场景,分别对JMQ4、JMQ2和Kafka进行消息生产对比性能测试,测试结果如下图:
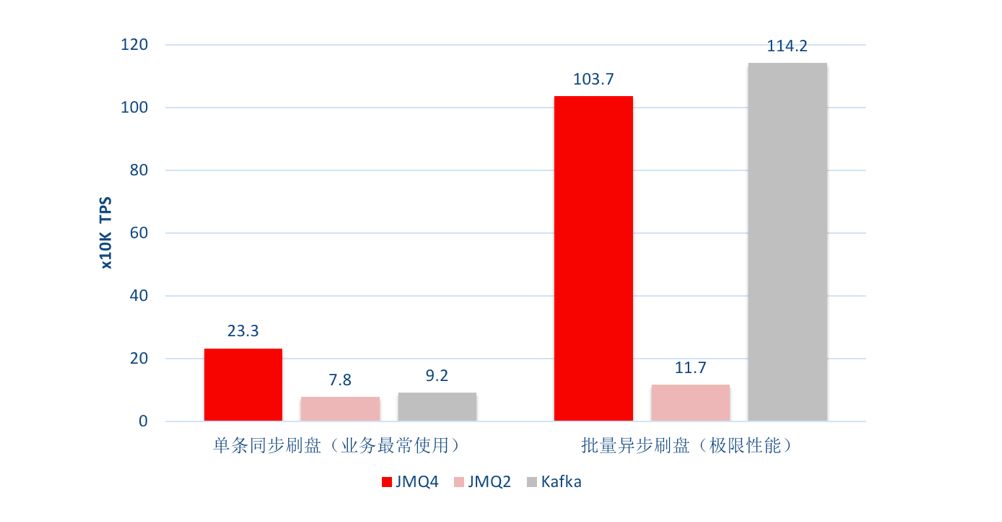
单条同步刷盘场景
单条同步刷盘是业务最长使用的场景:一个微服务由多个节点提供相同的服务组成微服务集群,每个微服务节点接收一个请求,然后进行业务处理,再发送一条消息,确认消息成功发送后,返回响应。
设置如下:
Broker设置为数据写入磁盘后返回发送成功确认
Producer每次发送一条消息,收到发送成功确认后再发送下一条消息
在这种场景下,JMQ4的写入速度约为每秒23万条,相比上一代JMQ性能提升了约2倍;Kafka在相同场景下测得的写入速度大约为每秒9.2万条,JMQ4的性能更好。
批量异步刷盘场景
批量异步刷盘场景,主要测试消息中间件的极限写入性能。
设置如下:
Broker设置为消息批量异步写入磁盘,无需返回发送成功确认
Producer设置为批量异步发送
批量异步场景下,JMQ的写入速度达到了每秒103.7万条,性能是上一代JMQ的10倍;Kafka在相同场景下测得的写入速度大约为每秒114万条,性能最好。
JMQ4在存储结构设计继承自上一代JMQ,参考Kafka,并做了一些改进。
JMQ2
先来看一看JMQ2的存储结构:
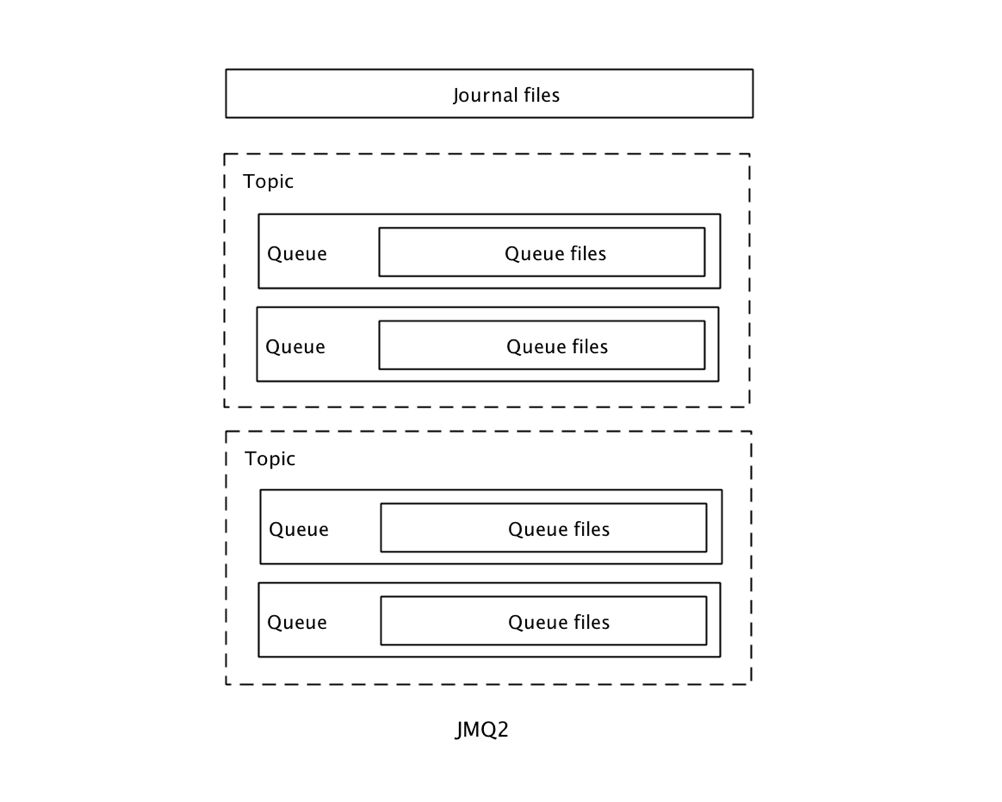
JMQ2的存储包括一组消息文件(Journal Files)用于存放消息,每个Topic包含多个队列文件(Queue Files),存放消息的索引。
消息写入时,所有Topic的消息按照收到消息的自然顺序依次追加写入消息文件中,然后异步创建索引并写入对应的队列文件中。
这种所有Topic共享一个消息文件的设计,最大限度的利用了"磁盘在批量顺序写入时具有最佳性能"的特性。并且单个Broker上可以支持大量的Topic和Parition/Queue,随着Topic增多没有明显的性能下降。在京东,JMQ2的单个节点支撑了超过1000个Topic。
局限性是灵活性欠佳,很难做到以Topic维度进行数据的复制、迁移和删除。
Kafka
下图是Kafka的存储设计:
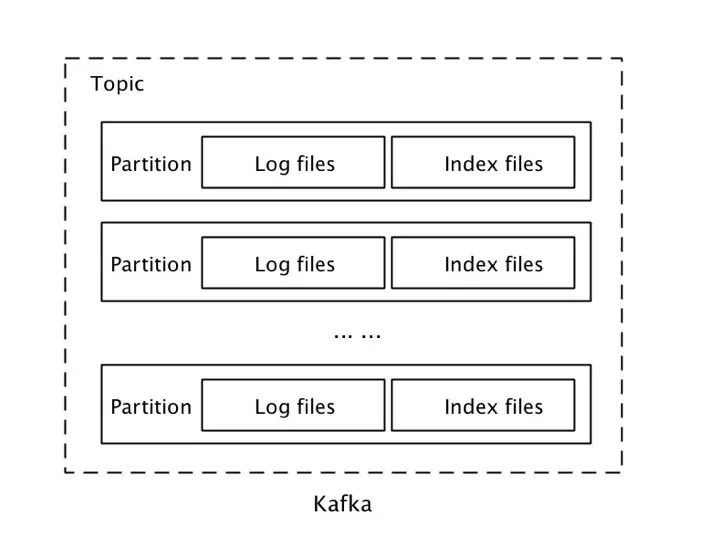
Kafka的存储以Partition为单位,每个Partition包含一组消息文件(Log Files)和一组索引文件(Index Files),并且消息文件和索引文件一一对应。
这种设计的优势是在批量写入时具备较好的性能,默认配置下,Kafka收到消息并不立即写入磁盘,而是满足一定条件后再批量刷盘。以分区为存储单元,在数据复制、迁移上更加灵活。
这种设计的问题是,在大规模微服务集群和IoT场景下,单个Topic需要支持海量的Producer和Consumer并发读写,势必要有和Consumer数量相当的Parition。随着Partition的数量增多,写入时需要频繁的在多个消息文件之间切换,性能会显著下降。
JMQ4
JMQ4采用相对折中的存储设计,兼顾了性能和灵活性。
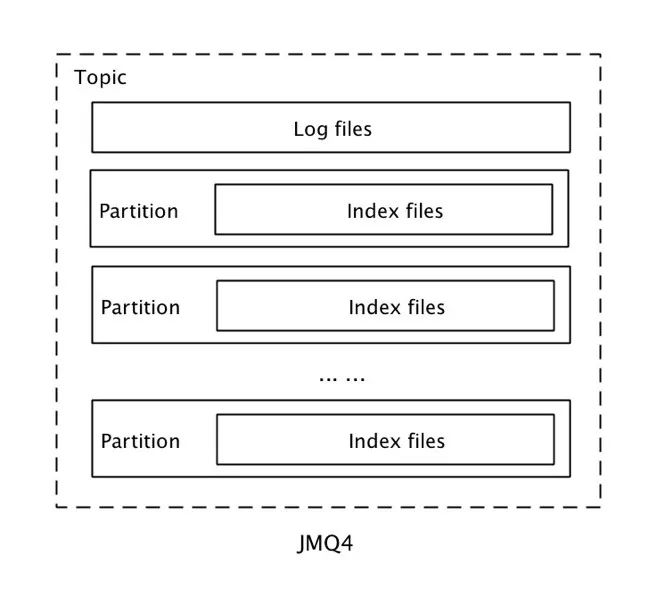
JMQ4存储的基本单元是Topic。在同一个Broker上,每个Topic对应一组消息文件(Log Files),顺序存放这个Topic的消息。与Kafka类似,每个Topic包含若干Partition,每个Partition对应一组索引文件(Index Files),索引中存放消息在消息文件中的位置和消息长度。
消息写入时,收到的消息按照对应的Topic写入依次追加写入消息文件中,然后异步创建索引并写入对应Partition的索引文件中。
以Topic为基本存储单元的设计,在兼顾灵活性的同时,具有较好的性能,并且单个Topic可以支持更多的并发。
索引设计
在索引的设计上,Kafka采用稀疏索引。查找消息时,首先根据文件名找到所在的索引文件,然后二分法遍历索引文件里找到离目标消息最近的索引,再顺序遍历消息文件找到目标消息。一次寻址的时间复杂度为O(log2n)+O(m),其中n为索引文件中的索引个数,m为索引的稀疏程度。
可以看到,寻址过程还是需要一定时间。一旦找到消息后位置后,就可以批量顺序读取,不必每条消息都要进行一次寻址。
JMQ采用定长稠密索引设计,每个索引固定长度。定长设计的好处是,直接根据索引序号就可以计算出索引在文件中的位置:
索引位置 = 索引序号 * 索引长度
这样,消息的查找过程就比较简单了,首先计算出索引所在的位置,直接读取索引,然后根据索引中记录的消息位置读取消息。
这两种设计各自擅长的场景不同,无所谓优劣。Kafka更加适合批量消费,JMQ更适合单条数据的消费。
JMQ使用Java作为开发语言。Java提供了非常丰富的IO API和数据读写方法,不同的API在不同的场景的性能差异非常大,选择适合JMQ数据读写方法就显得非常重要。通常来说,使用内存映射文件(MappedByteBuffer/ Memory Mapped File)是读写大文件性能最佳的方案。上一代JMQ使用的就是这种方法。
JMQ4的存储写入数据采用了一种更直接的方法:使用DirectBuffer作为缓存,数据先写入DirectBuffer,再异步通过FileChannel写入到文件中。这种方式对于大文件的追加写入的性能要明显优于内存映射文件。Stack Overflow上的一个帖子:Performance of MappedByteBuffer vs ByteBuffer给出的性能对比性能测试如下图:
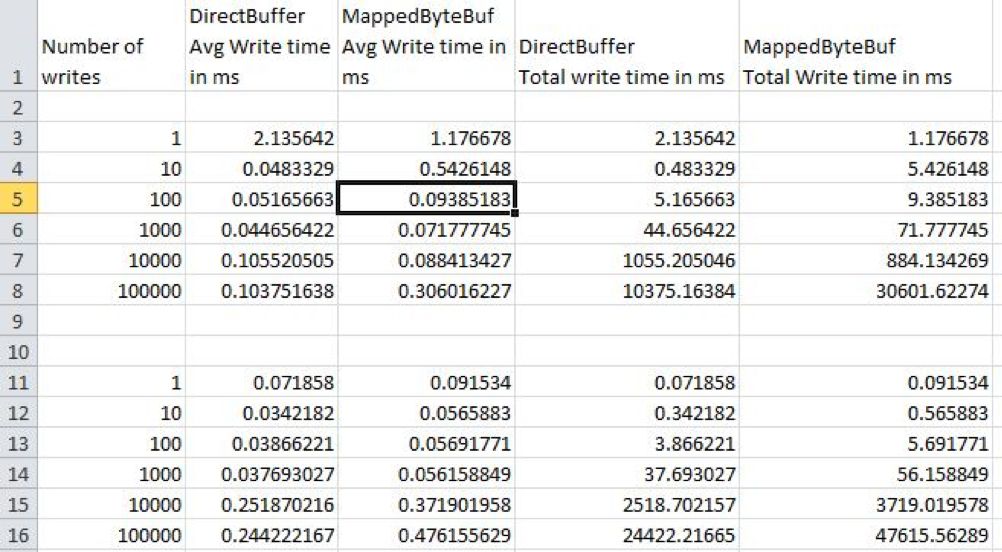
可以看出DirectBuffer的性能优势非常明显,实测结果也验证了这个结论。
为什么使用DirectBuffer的性能更快?分析这两种方法的写入过程的底层实现:
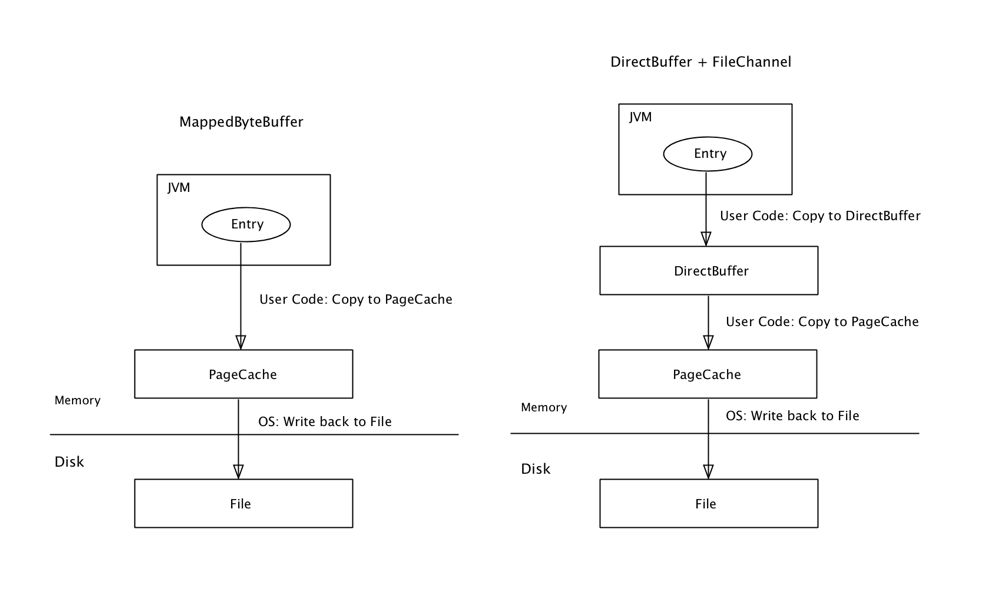
MappedByteBuffer方式写入过程是,首先将数据拷贝到OS的PageCache中,然后OS再将数据写入文件中。除非用户调用MappedByteBuffer.force()方法强制刷盘,否则OS自己决定什么时候将PageCache中的数据Write back回磁盘文件。写入过程包含一次内存数据拷贝和一次磁盘写入。
DirectBuffer方式写入的过程是,首先将数据拷贝到堆外的DirectBuffer中,然后再将数据批量写入文件中,但是OS处理写入文件的过程是先将数据拷贝到PageCache中,然后再Write back到文件中。写入过程包含二次内存数据拷贝和一次磁盘写入。
可以看到,实际上DirectBuffer方式相比MappedByteBuffer方式多了一次内存拷贝,为什么反而性能更好呢?
分析几点可能的原因:
1、并发写入缓解了DirectBuffer内存拷贝的性能损耗
首先需要注意到,写入的过程并不是串行执行的。MappedByteBuffer方式中,写入PageCache过程在JVM的线程中执行,PageCache写入文件的过程在OS的pdflush线程中执行。
类似的,DirectBuffer方式中,三次拷贝分别在JVM的write线程、flush线程和OS的pdflush线程中执行。
总体的写入性能取决于速度最慢的那个线程,考虑到磁盘与内存的读写性能的巨大差距,OS Write Back刷盘的过程是整个流程的性能瓶颈。因此,多一次并发的内存拷贝对总体性能不一定有影响。
2、MappedByteBuffer的内存映射开销
在写入每个文件的开始阶段,MappedByteBuffer多出一个无法并行的内存映射过程:在调用FileChannel.map()方法创建MappedByteBuffer时,实际上是调用了OS内核的mmap()系统调用,OS会在PageCache的页表中查找对应的Page,如果不存在则创建Page并加入到页表中。每个Page的大小是4K,映射一段较大的内存时,需要进行多个页的查找或创建过程,这一过程需要消耗一定的时间。
而DirectBuffer方式中,对应的过程就是在内存中申请一块DirectBuffer,并且在连续写入多个文件时,这个DirectBuffer是可以反复重用的,同样的过程几乎没有耗时。
3、MappedByteBuffer的Page Fault开销
MappedByteBuffer在创建时,只是做了文件内块的地址和内存地址的映射,并没有真正将文件的数据拷贝到内存中。当程序第一次访问(注意:读和写都是“访问”)内存中的Page时,会产生产生Page Fault中断,OS在中断中将该页对应磁盘中的数据拷贝到内存中。在对文件进行追加写入的情况下,这一无法避免的过程是完全没有必要,反而增加了写入的耗时。
4、批量大小
另外一个影响写入性能的因素是每批写入数据的大小。DirectBuffer方式由于多了一层可以自行控制的缓存层,应用程序可以自行控制选择合适的批量大小,以达到最佳的性能。相比之下,使用MappedByteBuffer方式并不太容易控制进行批量控制,实测下来OS的批量控制策略并不能达到相对满意的批量性能。一个可能的方式是调整OS相关的内核参数以达到满意性能,但面对大规模集群和容器化的趋势,显然这种方式并不可取。
JMQ4缓存的设计思路是尽可能的充分利用操作系统内存,减少磁盘的IO,以提升总体读写性能。
JMQ4的缓存页以文件为单位映射,每个消息文件对应内存中的一个缓存页。
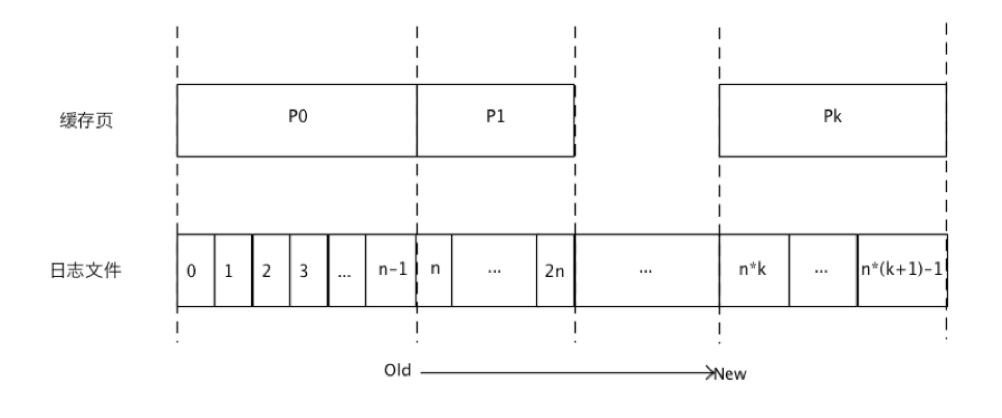
考虑到消息的文件读写的一些特性:
追加写入和不可变性:消息只在尾部追加写入,已写入的消息具有不可变性
顺序读取:绝大部分对消息文件的读访问都是顺序读取
热尾效应:大部分的消息生产后立即就会被消费,因此绝大部分的读访问都发生在存储的尾部。
JMQ4在缓存设计上针对这些特性的做了一些优化。
页的读写转换
上一章提到过,在写入消息的时候,会先将消息写入用于数据缓冲的DirectBuffer中。这个DirectBuffer不仅被用于写入的数据缓冲,本身也是作为缓存页加入到了缓存列表中,用于消息读取。这种设计方式,不仅减少了一次文件从磁盘到到缓存的数据拷贝,并且减少了整个生产-消费流程的时延:消息不必等到写入磁盘才能被消费。
缓存清理策略
缓存清理策略决定当缓存即将溢出时,哪些页将被优先从缓存中移出。JMQ4采用冷热分区和尾部距离二个维度综合决策被移出缓存的页。
以当前时间为截止时间,将之前的时间划分为冷热二个区间,距离当前时间教近的为热区,较远的为冷区。例如,将热区的时间范围设为10秒,那么最后一次访问时间距离当前时间小于10秒的页属于热区,其它页属于冷区。
缓存清理的策略如下:
优先移出冷区缓存页,如果冷区为空,再清理热区中缓存页
区内按照缓存页所在位置与尾部的距离选择被移出的页:优先移出距离最远的缓存页
上述缓存清理策略不仅对频繁需要访问的热数据保持较高的命中率,而且有效的解决了偶发批量访问导致的缓存污染问题。
例如,正常情况下,对缓存的请求集中在消息文件的尾部,缓存内的大部分缓存页的位置也都靠近消息文件的尾部。当某个用户从消息文件的中间某个位置开始向后连续访问消息数据时:如果使用LRU等缓存策略,随着用户访问,大量中间位置的缓存页会把大量尾部的缓存页置换出缓存,导致其他用户正常访问尾部消息缓存命中率下降。
使用JMQ4的缓存清理策略,由于中间位置的缓存页相对尾部的缓存页距离更远,刚刚被访问过的中间位置缓存页将被优先清理出缓存,有效的避免了缓存污染问题。
缓存预加载
大多数情况下,消息数据具有连续的读写的特性,即从某个位置开始向后连续进行读写。基于这一特性,可以预测即将被访问的位置,提前异步加载缓存页,进一步提升缓存的命中率。
当请求缓存时判断是否满足如全部条件,如果满足则进行异步加载缓存页Pn+1:
命中缓存,将命中的缓存页记为Pn
Pn位于热区
请求的消息位置位于Pn的尾部
---------------END----------------
后续的内容同样精彩
长按关注“IT实战联盟”哦

注意:本文归作者所有,未经作者允许,不得转载

