 来这里找志同道合的小伙伴!
来这里找志同道合的小伙伴!
分布式锁,是用来控制分布式系统中互斥访问共享资源的一种手段,从而避免并行导致的结果不可控。基本的实现原理和单进程锁是一致的,通过一个共享标识来确定唯一性,对共享标识进行修改时能够保证原子性和和对锁服务调用方的可见性。由于分布式环境需要考虑各种异常因素,为实现一个靠谱的分布式锁服务引入了一定的复杂度。
分布式锁服务一般需要能够保证以下几点:
同一时刻只能有一个线程持有锁
锁能够可重入
不会发生死锁
具备阻塞锁特性,且能够及时从阻塞状态被唤醒
锁服务保证高性能和高可用
当前使用较多的分布式锁方案主要基于 Redis、ZooKeeper 提供的功能特性加以封装来实现的,下面我们会简要分析下这两种锁方案的处理流程以及它们各自的问题。
>>>> 一、基于 Redis 实现的锁服务
加锁流程
SET resource_name my_random_value NX PX max-lock-time
注:资源不存在时才能够成功执行 set 操作,用于保证锁持有者的唯一性;同时设置过期时间用于防止死锁;记录锁的持有者,用于防止解锁时解掉了不符合预期的锁。
解锁流程
if redis.get("resource_name") == " my_random_value" return redis.del("resource_name") else return 0
注:使用 Lua 脚本保证获取锁的所有者、对比解锁者是否所有者、解锁是一个原子操作。
该方案的问题在于:
通过过期时间来避免死锁,过期时间设置多长对业务来说往往比较头疼,时间短了可能会造成:持有锁的线程 A 任务还未处理完成,锁过期了,线程 B 获得了锁,导致同一个资源被 A、B 两个线程并发访问;时间长了会造成:持有锁的进程宕机,造成其他等待获取锁的进程长时间的无效等待。
Redis 的主从异步复制机制可能丢失数据,会出现如下场景:A 线程获得了锁,但锁数据还未同步到 slave 上,master 挂了,slave 顶成主,线程 B 尝试加锁,仍然能够成功,造成 A、B 两个线程并发访问同一个资源。
>>>> 二、基于 ZooKeeper 实现的锁服务
加锁流程:
在 /resource_name 节点下创建临时有序节点
获取当前线程创建的节点及 /resource_name 目录下的所有子节点,确定当前节点序号是否最小,是则加锁成功。否则监听序号较小的前一个节点。
注:ZAB 一致性协议保证了锁数据的安全性,不会因为数据丢失造成多个锁持有者;心跳保活机制解决死锁问题,防止由于进程挂掉或者僵死导致的锁长时间被无效占用。具备阻塞锁特性,并通过 Watch 机制能够及时从阻塞状态被唤醒。
解锁流程是删除当前线程创建的临时接点。
该方案的问题在于通过心跳保活机制解决死锁会造成锁的不安全性,可能会出现如下场景:
持有锁的线程 A 僵死或网络故障,导致服务端长时间收不到来自客户端的保活心跳,服务端认为客户端进程不存活主动释放锁,线程 B 抢到锁,线程 A 恢复,同时有两个线程访问共享资源。
基于上诉对现有锁方案的讨论,我们能看到,一个理想的锁设计目标主要应该解决如下问题:
锁数据本身的安全性
不发生死锁
不会有多个线程同时持有相同的锁
而为了实现不发生死锁的目标,又需要引入一种机制,当持有锁的进程因为宕机、GC 活者网络故障等各种原因无法主动过释放锁时,能够有其他手段释放掉锁,主流的做法有两种:
锁设置过期时间,过期之后 Server 端自动释放锁
对锁的持有进程进行探活,发现持锁进程不存活时 Server 端自动释放
实际上不管采用哪种方式,都可能造成锁的安全性被破坏,导致多个线程同时持有同一把锁的情况出现。因此我们认为锁设计方案应在预防死锁和锁的安全性上取得平衡,没有一种方案能够绝对意义上保证不发生死锁并且是安全的。
而锁一般的用途又可以分为两种,实际应用场景下,需要根据具体需求出发,权衡各种因素,选择合适的锁服务实现模型。无论选择哪一种模型,需要我们清楚地知道它在安全性上有哪些不足,以及它会带来什么后果:
为了效率,主要是避免一件事被重复的做多次,用于节省 IT 成本,即使锁偶然失效,也不会造成数据错误,该种情况首要考虑的是如何防止死锁。
为了正确性,在任何情况下都要保证共享资源的互斥访问,一旦发生就意味着数据可能不一致,造成严重的后果,该种情况首要考虑的是如何保证锁的安全。
>>>> 三、SharkLock 的设计选择
锁信息设计如下:
lockBy:Client 唯一标识
condition:Client 在加锁时传给 Server,用于定义 Client 期望 Server 的行为方式
lockTime:加锁时间
txID:全局自增 ID
lease:租约
>>>> 如何保证锁数据的可靠性
SharkLock 底层存储使用的是 SharkStore,SharkStore 是一个分布式的持久化 Key-Value 存储系统。采用多副本来保证数据安全,同时使用 raft 来保证各个副本之间的数据一致性。
>>>> 如何预防死锁
Client 定时向 Server 发送心跳包,Server 收到心跳包之后,维护 Server 端 Session 并立即回复,Client 收到心跳包响应后,维护 Client 端 Session。心跳包同时承担了延长 Session 租约的功能
当锁持有方发生故障时,Server 会在 Session 租约到期后,自动删除该 Client 持有的锁,以避免锁长时间无法释放而导致死锁。Client 会在 Session 租约到期后,进行回调,可选择性的决策是否要结束对当前持有资源的访问
对于未设置过期的锁,也就意味着无法通过租约自动释放故障 Client 持有的锁。因此额外提供了一种协商机制,在加锁的时候传递一些 condition 到服务端,用于约定 Client 端期望 Server 端对异常情况的处理,包括什么情况下能够释放锁。譬如可以通过这种机制实现 Server 端在未收到十个心跳请求后自动释放锁,Client 端在未收到五个心跳响应后主动结束对共享资源的访问
尽最大程度保证锁被加锁进程主动释放:
进程正常关闭时调用钩子来尝试释放锁
未释放的锁信息写文件,进程重启后读取锁信息,并尝试释放锁
>>>> 如何确保锁的安全性
1. 尽量不打破谁加锁谁解锁的约束,尽最大程度保证锁被加锁进程主动释放:
a)进程正常关闭时调用钩子来尝试释放锁
b)未释放的锁信息写文件,进程重启后读取锁信息,并尝试释放锁
2. 依靠自动续约来维持锁的持有状态,在正常情况下,客户端可以持有锁任意长的时间,这可以确保它做完所有需要的资源访问操作之后再释放锁。一定程度上防止如下情况发生:
a)线程 A 获取锁,进行资源访问
b)锁已经过期,但 A 线程未执行完成
c)线程 B 获得了锁,导致同时有两个线程在访问共享资源
3. 提供一种安全检测机制,用于对安全性要求极高的业务场景:
a)对于同一把锁,每一次获取锁操作,都会得到一个全局增长的版本号
b)对外暴露检测 API checkVersion(lock_name,version),用于检测持锁进程的锁是不是已经被其他进程抢占(锁已经有了更新的版本号)
c)加锁成功的客户端与后端资源服务器通信的时候可带上版本号,后端资源服务器处理请求前,调用 checkVersion 去检查锁是否依然有效。有效则认为此客户端依旧是锁的持有者,可以为其提供服务
d)该机制能在一定程度上解决持锁 A 线程发生故障,Server 主动释放锁,线程 B 获取锁成功,A 恢复了认为自己仍旧持有锁而发起修改资源的请求,会因为锁的版本号已经过期而失败,从而保障了锁的安全性
下面对 SharkLock 依赖的 SharkStore 做一个简单的介绍。
>>>> SharkStore 基本模块
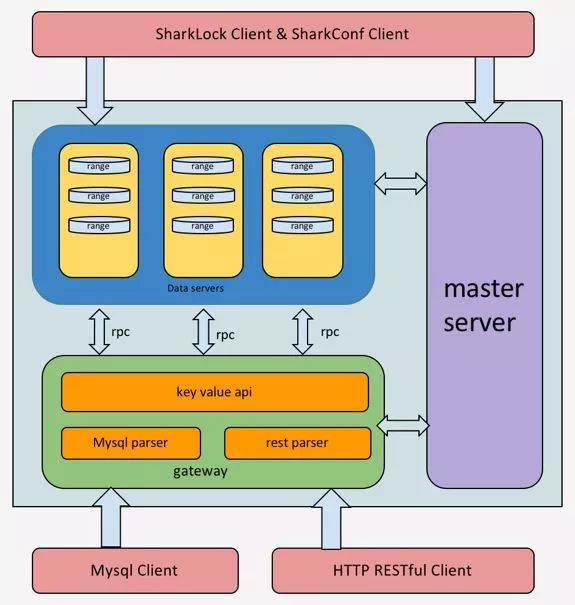
Master Server 集群分片路由等元数据管理、扩容和 Failover 调度等。
Data Server 数据存储节点,提供 RPC 服务访问其上的 KV 数据。
Gateway Server 网关节点,负责用户接入。
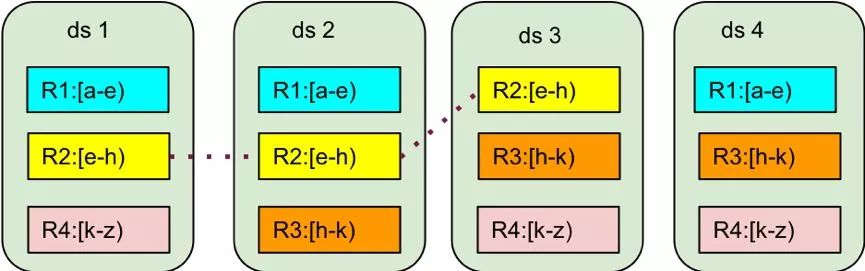
>>>> Sharding
SharkStore 采用多副本的形式来保证数据的可靠性和高可用。同一份数据会存储多份,少于一半的副本宕机仍然可以正常服务。 SharkStore 的数据分布如下图所示:
>>>> 扩容方案
当某个分片的大小到达一定阈值,就会触发分裂操作,由一个分片变成两个,以达到扩容的目的。
Dataserver 上 range 的 leader 自己触发。leader 维持写入操作字节计数,每到达 check size 大小,就异步遍历其负责范围内的数据,计算大小并同时找出分裂时的中间 key 如果大小到达 split size,向 master 发起 AskSplit 请求,同意后提交一个分裂命令。分裂命令也会通过 raft 复制到其他副本。
本地分裂。分裂是一个本地操作,在本地新建一个 range,把原始 range 的部分数据划拨给新 range,原始 range 仍然保留,只是负责的范围减半。分裂是一个轻量级的操作。
>>>> Failover 方案
failover 以 range 的级别进行。range 的 leader 定时向其他副本发送心跳,一段时间内收不到副本的心跳回应,就判断副本宕机,通过 range 心跳上报给 master。由 master 发起 failover 调度。 Master 会先删除宕机的副本然后选择一个合适的新节点,添加到 range 组内之后通过 raft 复制协议来完成新节点的数据同步。
>>>> Balance 方案
dataserver 上的 range leader 会通过 range 心跳上报一些信息,每个 dataserver 还会有一个节点级别的 Node 心跳。 Master 收集这些信息来执行 balance 操作。Balance 通过在流量低的节点上增加副本,流量高的节点上减少副本促使整个集群比较均衡,维护集群的稳定和性能。
>>>> Raft 实践 -MultiRaft
心跳合并
以目标 dataserver 为维度,合并 dataserver 上所有 Raft 心跳 心跳只携带 range ids,心跳只用来维护 leader 的权威和副本健康检测 range ids 的压缩,比如差量 + 整型变长 Leader 类似跟踪复制进度,跟踪 follower commit 位置。
快照管理控制
建立 ACK 机制,在对端处理能力之内发送快照 ; 控制发送和应用快照的并发度,以及限速 ; 减少对正常业务的冲击。Raft 实践 -PreVote。
Raft 算法中,leader 收到来自其他成员 term 比较高的投票请求会退位变成 follower因此,在节点分区后重加入、网络闪断等异常情况下,日志进度落后的副本发起选举,但其本身并无法被选举为 leader,导致集群在若干个心跳内丢失 leader,造成性能波动 ;针对这种情况,在 raft 作者的博士论文中,提出了 prevote 算法: 在发起选举前,先进行一次预选举 Pre-Candidate, 如果预选举时能得到大多数的投票,再增加 term,进行正常的选举。 prevote 会导致选举时间变长 (多了一轮 RPC),然而这个影响在实践中是非常小的, 可以有利于集群的稳定,是非常值得的实践。
>>>> Raft 实践 -NonVoter
一个新的 raft 成员加入后,其日志进度为空;新成员的加入可能会导致 quorum 增加,并且同时引入了一个进度异常的副本;新成员在跟上 leader 日志进度之前,新写入的日志都无法复制给它;如果此时再有原集群内一个成员宕机,很有可能导致集群内可写副本数到不到 quorum,使得集群变得不可写。很多 raft 的实现中,都会引入了一种特殊身份的 raft 成员 (non-voting 或者 learner) Learner 在计算 quorum 时不计入其内,只被动接收日志复制,选举超时不发起选举;在计算写入操作是否复制给大多数 (commit 位置) 时,也忽略 learner。Sharkstore raft 会在 leader 端监测 learner 的日志进度, 当 learner 的进度跟 leader 的差距小于一定百分比 (适用于日志总量比较大) 或者小于一定条数时 (适用于日志总量比较小), 由 leader 自动发起一次 raft 成员变更,提升 leaner 成员为正常成员。
SharkStore 目前已经开源,有兴趣的同学可详细了解,期待能跟大家能够一块儿沟通交流。
https://github.com/tiglabs/sharkstore
---------------END----------------
后续的内容同样精彩
长按关注“IT实战联盟”哦

注意:本文归作者所有,未经作者允许,不得转载

