靠文章生存的大厂们
简书/小红书/CSDN(PS:好吧你们仨记得给我广告费),对优秀的文章进行大数据分析的工作必不可以少了,本系列文章将会从关于文章的各个维度进行实战分析,这系列文章新手可借着踏入大数据研发的大门,至于大数据的大佬们可以一起来相互伤害,至少为什么取名为 ''亿级流量分析实战'' 看完后整个系列的文章你就知道了,相信大家都是会举一反三的孩子们。


网名:大猪大猪
姓名:不祥
年龄:不祥
身高:不祥
性别:不祥

日志存储结构设计如下,肯定很多小伙伴要问为什么设计成JSON形式?多占空间?多...
统一回复:可读、易排查
{"time": 1553269361115,"data": {"type": "read","aid": "10000","uid": "4229d691b07b13341da53f17ab9f2416","tid": "49f68a5c8493ec2c0bf489821c21fc3b","ip": "22.22.22.22"}}
参数
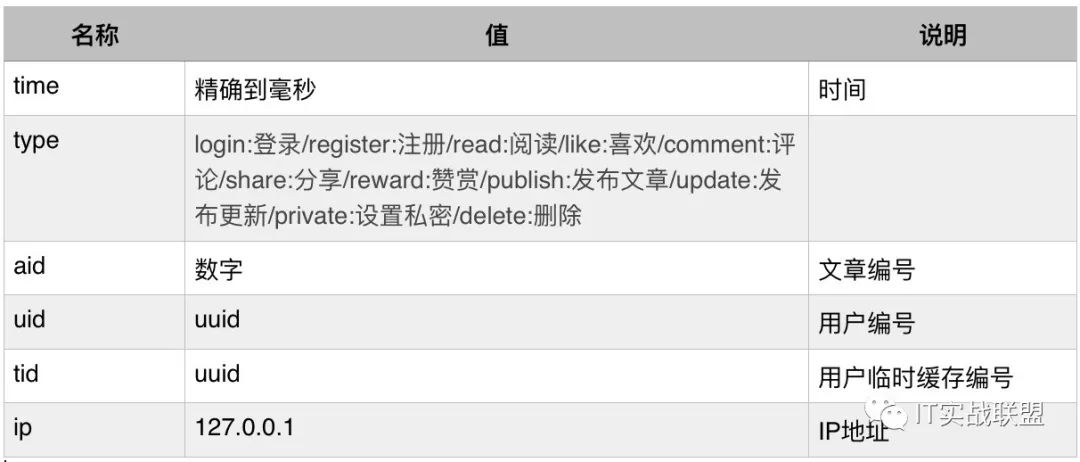

日志表
create 'LOG_TABLE',{NAME => 'info',TTL => '30 DAYS',CONFIGURATION => {'SPLIT_POLICY' => 'org.apache.hadoop.hbase.regionserver.KeyPrefixRegionSplitPolicy','KeyPrefixRegionSplitPolicy.prefix_length'=>'2'},COMPRESSION=>'SNAPPY'},SPLITS => ['20', '40', '60', '80', 'a0', 'c0', 'e0']
rowkey -------->
49|20190101000000000|f68a5c(时间+用户ID)
设计原则:能按时间维度查询,而且还能打散数据。过期时间 30天 --------> 够长的了,反正日志源文件还在
设计原则:其实就是为了不占用那么多的存储资源。预分区 -------->使用
rowkey前两位,00~ff=256 个region,表示现在的业务已经可以满足要求。
设计原则:是为了能尽量打散数据到各台Region Server。
用户表
create 'USER_TABLE',{NAME => 'info',CONFIGURATION => {'SPLIT_POLICY' => 'org.apache.hadoop.hbase.regionserver.KeyPrefixRegionSplitPolicy','KeyPrefixRegionSplitPolicy.prefix_length'=>'2'},COMPRESSION=>'SNAPPY'},SPLITS => ['20', '40', '60', '80', 'a0', 'c0', 'e0']
rowkey --------> 49f68a5c8493ec2c0bf489821c21fc3b (用户ID,前8位)
设计原则:唯一性,通过ID能直接找到用户信息。
现在还没涉及到程序设计与实现篇章,后续将会在 "亿级流量分析实战" 系列文章中逐一实现。
心明眼亮的你、从此刻开始。


作者:大猪大猪
链接:https://www.jianshu.com/p/24a6daf93746
注意:本文归作者所有,未经作者允许,不得转载

