简介
Databricks 上周发布了 Apache Spark 3.0,并将此作为新版 Databricks Runtime 7.0 的一部分。3.0.0 版本包含 3400 多个补丁,为 Python 和 SQL 功能带来了重大进展。
Spark 是用于大数据处理,数据科学,机器学习和数据分析等领域的统一引擎。
Spark 3.0 重要变化:
与 Spark 2.4 相比,TPC-DS 的性能提升了2倍,主要通过自适应查询执行、动态分区修剪和其他优化实现
兼容 ANSI SQL
针对 pandas API 的重大改进,包括 Python 类型提示和额外的 pandas UDF
改进 Python 错误处理,简化 PySpark 异常提醒
为结构化流(structured streaming)提供新 UI
调用 R 语言自用户定义函数(User-Defined Function)的速度可提高 40 倍
解决了 Jira 上 3400 多个 issue,这些 issue 的分布情况如下图所示
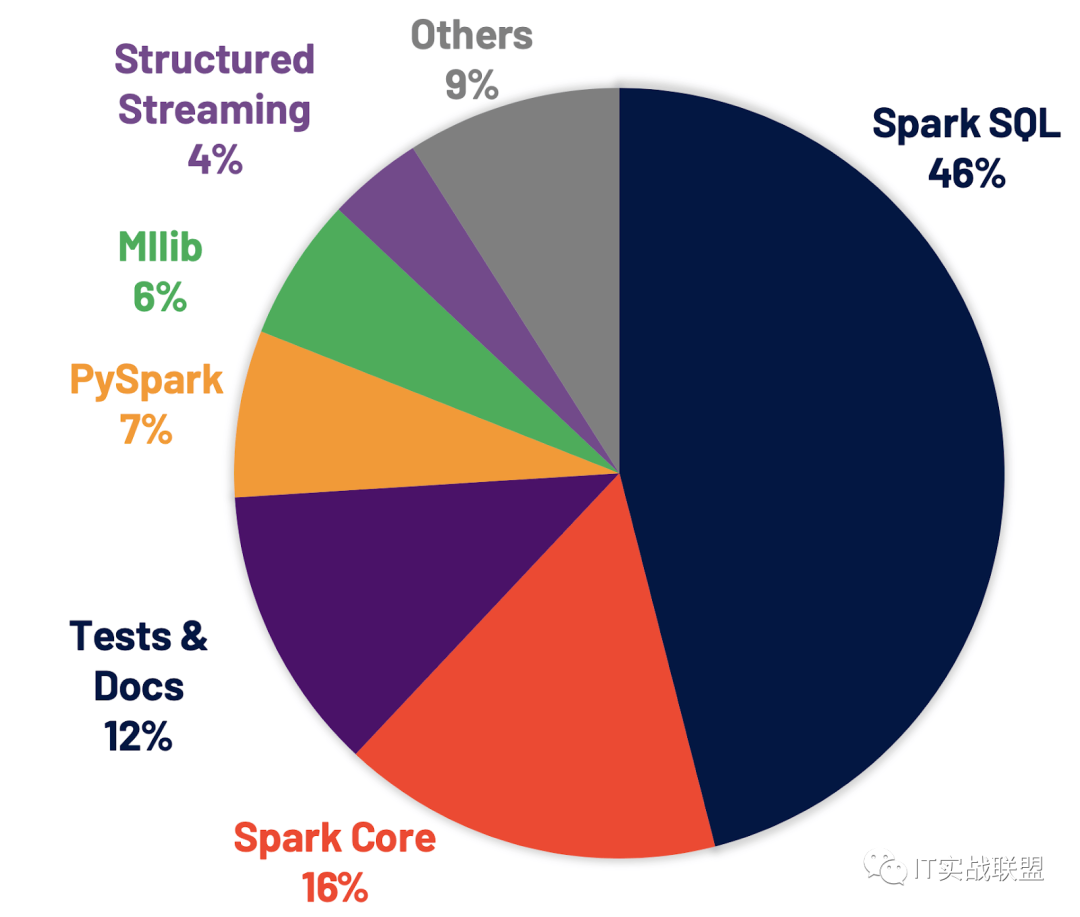
改进 Spark SQL 引擎
Spark SQL 是支持大多数 Spark 应用程序的引擎。在 Spark 3.0 中,46% 的补丁被应用于 SQL,提升了性能和 ANSI 兼容性。如下图所示,Spark 3.0 的性能大约是 Spark 2.4 的 2 倍。
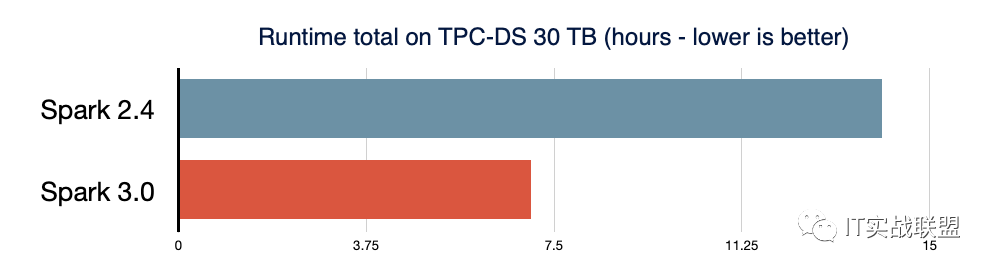
Spark SQL 引擎中的主要新功能
新的自适应查询执行(AQE) 框架通过在运行时生成更好的执行计划来提高性能并简化调整,即使由于缺少或使用不正确的数据统计信息和错误估计的成本而致使初始计划不理想时,也是如此。此版本引入了三个主要的自适应优化:动态合并 shuffle 分区可简化甚至避免调整 shuffle 分区的数量、动态切换连接策略部分避免了由于缺少统计信息或错误估计大小而导致执行次计划的情况,以及动态优化倾斜连接(optimizing skew joins )。
动态分区修剪 (Dynamic Partition Pruning)
当优化器无法在编译时识别其可以跳过的分区,将会应用“动态分区修剪”功能。这在星型模式中很常见,星型模式由一个或多个事实表组成,这些事实表引用了任意数量的维度表。在执行这种联接操作中,我们可以通过识别维度表过滤之后的分区来修剪联接从事实表中读取的分区。在 TPC-DS 基准测试中,102 个查询中有 60 个查询获得 2 到 18 倍的显着加速。
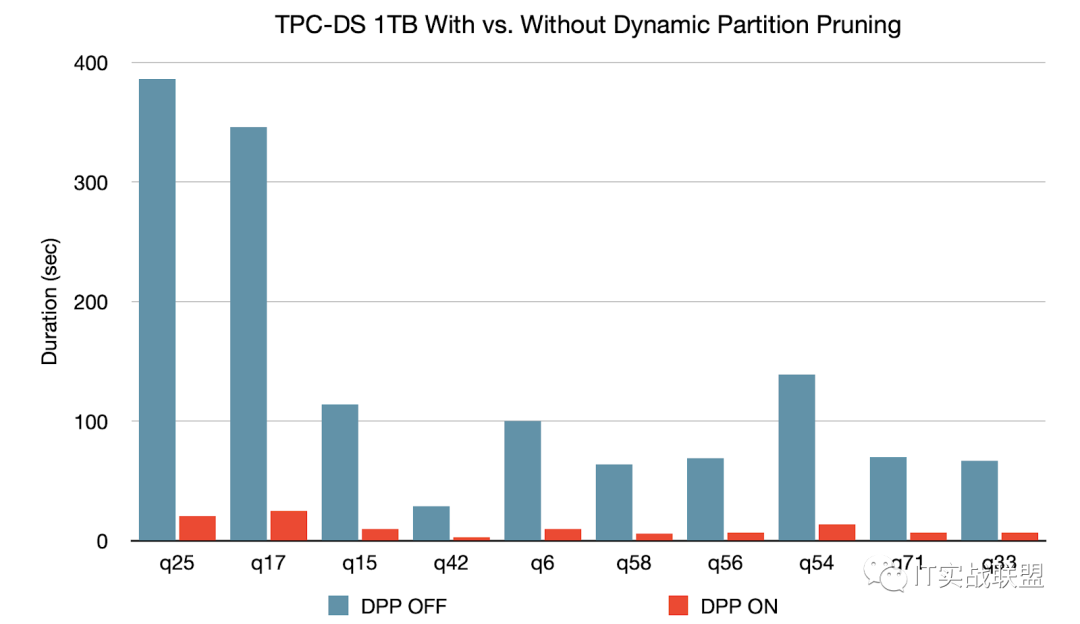
Spark 3.0 中的其他更新
Spark 3.0 除了在 SQL,Python 和流技术方面包含部分关键改进,还提供了许多其他的新功能。详情查看发布说明,发现对 Spark 的所有其他改进,包括数据源、生态系统和监视等。

注意:本文归作者所有,未经作者允许,不得转载

