小编又来啦~本周要推荐给大家的是一篇跟中间件上云相关的技术文章,这里面详细的记录了,蘑菇街自研消息系统上云的全过程,也是市面上开放出来为数不多的企业自研组件上云实践。有相关需求的同学可以好好学习下。
背景
从当下的情况来看,如果一个公司需要一个消息队列中间件,那么大致有以下两个个选择:
1.首先考虑的应该是各云厂商提供的消息队列服务,目前阿里云,腾讯云,华为云都有丰富且成熟的消息队列解决方案供选择
2.如果使用规模够大,可能选择云厂商的消息队列服务成本会高于自建,那么可以选择自己搭建并维护kafka、rabbitmq或其它优秀的开源项目
由于作者并没有参与当时方案的调研和评审工作,所以针对以上两个选择,当时选择自研的原因可能如下:
1.在15年那个阶段,国内云厂商阿里云一家独大,腾讯云和华为云都还未起势,业界也一般只有创业公司才会选择云厂商,大部分有一定规模的互联网公司选择的还是自建机房,自己部署、维护服务。但由于蘑菇街电商公司的特性,所以从数据安全的考虑,不适合选择阿里云提供的消息队列服务,那么就只能选择自己搭建消息队列
2.事实上也是如此,蘑菇街之前有一套自己搭建,运维的kafka集群,但主要用在大数据相关业务上,也就是说公司在离线数据处理这块选择的kafka。而对于实时业务的消息队列使用需求,kafka从消息生产到被消费的总体延时大致在100ms~200ms量级,如果采用云服务,加上云厂商机房到自建机房的网络延迟,会导致延迟骤增。并且由于kafka的底层数据存储模型,在一个kafka集群中创建大量的topic及partition,会导致kafka读写性能的骤降,而蘑菇街的业务模型在某种程度上是需要创建较多的topic及partition的。
综上所述,考虑到电商、支付业务的实时性,公司的发展速度及当时整体互联网公司的技术选择氛围等综合原因,当时的中间件团队选择了自研一套消息队列系统并取名为————Corgi(柯基:下文都使用Corgi来代称蘑菇街自研的消息队列)。但研发并不是从零开始,而是在设计原理上借鉴了很多RocketMQ的设计理念,并且最终所提供的功能、API等都和RocketMQ有非常多的相似点。
然而,随着各大云厂商的崛起,其提供的消息队列解决方案愈来愈成熟,价格方面也越来越有优势,到了2020年这个时间点,维护一套自研的消息队列和直接使用云厂商提供的解决方案来对比,就有如下几个劣势了:
1.运维上的痛点:
首先,Corgi采用的是主从结构,但没有主从的自动切换功能,每次Master节点挂掉后,需要手动进行一系列的操作然后将原来的Slave替换为新的Master,并为其挂载一个新的Slave节点。其次,扩容的时候挂载的新节点无法自动同步topic及partition信息到新节点上,需要很多手工的操作才可以完成初始化节点工作。
2.成本高:
M-S架构下为了保证线上服务的稳定性,针对每个集群至少同时有3组M-S节点,并且Corgi对CPU核数的要求也较高,这样就导致Corgi集群的服务器成本很高
如果迁移到云厂商的消息队列服务,那么上述两个问题就都不存在了。
1.蘑菇街在2018年的时候已经全站迁移腾讯云,上云后,所有的网络交互都是走腾讯云内网,之前所顾虑的延迟问题也会有很大的改善,即使无法达到10ms级别,也基本可以满足业务需求。
2.成本上,Corgi集群的总成本大约是使用腾讯云CKafka的3倍
总之,基于以上几点原因,我们选择放弃自研的消息队列,将其迁移至腾讯云Ckafka。迁移中需要保证的特性:
1.Corgi提供的消费语义是AtLeastOnce,即最少消费一次。也就是说在特殊场景下,业务方消费到重复消息是被允许的,所以需要业务同学自己保证幂等性,我们只需保证不丢消息即可。
2.局部顺序性:生产者在生产的时候,消息落入每个分区是顺序的。在消费者端,用户可以选择是否顺序消费消息,如果开启了这个开关,那么在AtLeastOnce的基础上,消费者客户端能保障消息被第一次消费的顺序性
3.迁移过程可回滚,不能停服,不能影响线上业务。
根据以上特性,整个迁移过程就像是对一辆正在高速行驶中的汽车进行换轮胎工作。
迁移方案
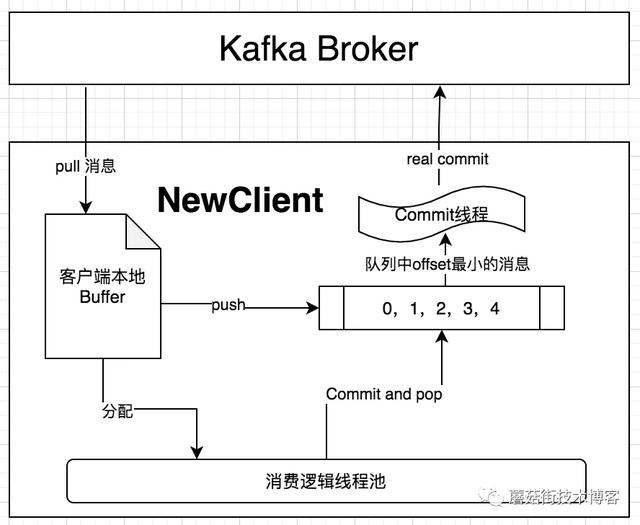
我们在Kafka的Java客户端之上封装了一个兼容原来Corgi客户端所有主要使用姿势的新客户端,下文中我将其称为NewClient。业务同学只需将pom.xml中的依赖修改为NewClient,就可以在Kafka中生产和消费了,新客户端的大致技术架构如图:
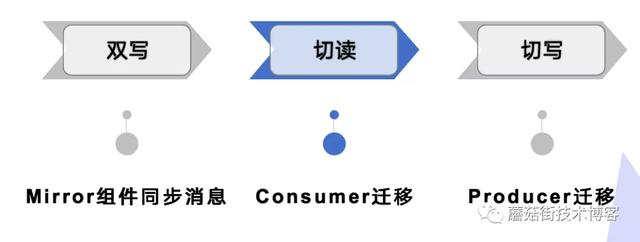
对于任何存储型的技术组件来说,其迁移莫过于3个过程:双写,切读,切写
双写阶段
总体来说,双写可以采用两种方案:
1.修改Producer客户端的实现,使其能够同时写Corgi和Kafka,并通过一个开关来控制其写行为,可以同时写两侧,也可以只写一侧。
2.在两个消息队列组件之间搭建一个MirrorMaker,将其中一个组件的所有消息同步到另一个组件中。
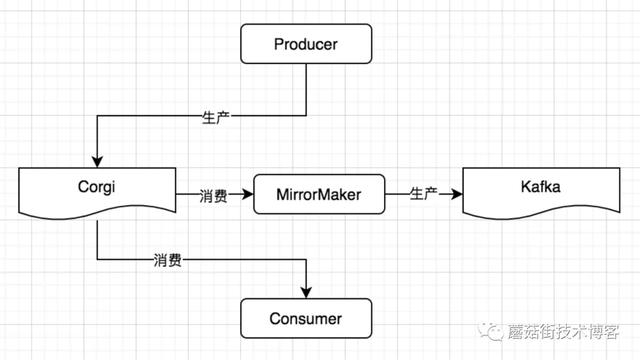
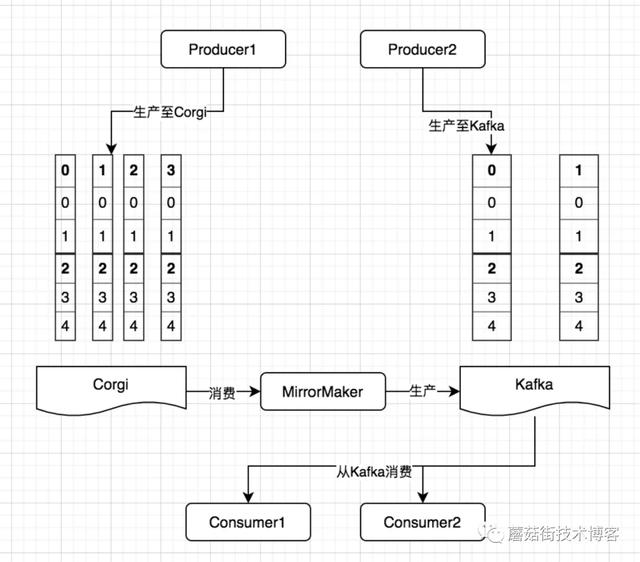
我们采用的是方案2,总体架构如下图:
首先,由于Corgi的使用方很多,无法全部找出所有使用方,采用方案1总会有漏掉的生产者。其次,由于原来只需写一个消息队列,现在要两边都写,采用方案一会导致生产者的延迟增高,另外,一旦迁移过程中其中一个消息队列出现故障,一边写成功了,另一边没写成功,会导致两侧数据不一致,会产生丢消息的问题。
所以我们采用了MirrorMaker的方案,其功能就是将自己当做一个消费者从Corgi中消费消息,并在保证顺序的前提下将消息生产至Kafka。并且,在消费的过程中保证原子性,即只有消息成功生产至Kafka了,才会向Corgi提交这条消息的commit信息。这样,即使迁移过程中Kafka故障了,那么也可以保证恢复后可以接着Corgi中上次的消费位点继续同步消息,丢消息的问题和顺序性的问题都得到了保障。
另外,我们在设计实现MirrorMaker的过程中采用M-S结构保障了MirrorMaker的高可用性及无感水平扩缩容,相当于将本来一个有状态的过程简化成了无状态的过程。
切读阶段
消费者的迁移可以分为非顺序消费和顺序消费两种,迁移过程如下图:
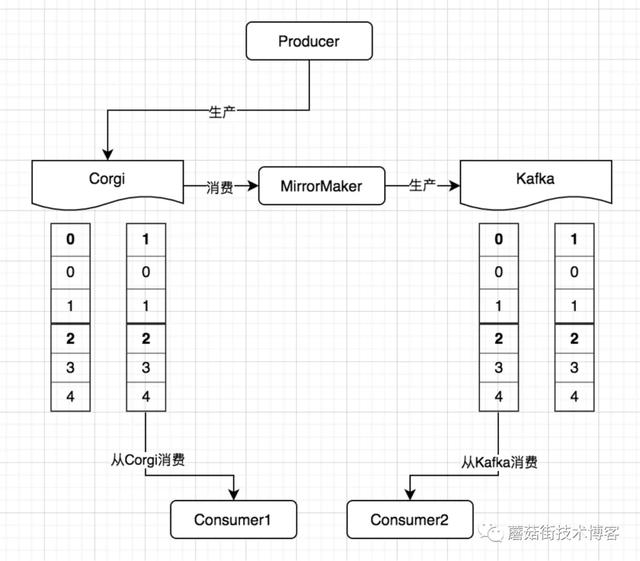
消费者业务同学修改代码,使用NewClient之后,在发布的过程中,会有一段时间整个系统处于一个即消费Corgi,又消费Kafka的过程。此过程中,在消费Corgi没有堆积消息的前提下,即两边消费的都是实时生产的数据,那么会有以下两个影响:
1.发布过程中的产生的消息都会被消费两次
2.由于整体链路的原因,在无任何控制的前提下,Kafka消费的进度可能略快于Corgi中的消费速度(例如Corgi中由于某一条消息消费很慢而阻塞了消费进度),这样就会导致顺序错乱的问题
所以,鉴于以上两个影响,对顺序消费和非顺序消费分别采用了不同的切换方案
非顺序消费:无需做任何控制,直接修改代码发布即可,业务逻辑自己保证消息的幂等性。
顺序消费:首先,由于Kafka第一次消费默认是从队列尾部开始的,所以需要在Kafka中生成一个略早时间点的消费位点,时间点在第一台机器发布开始前即可。其次,在NewClient中有一个开关,可以控制消费行为的开始,当开关关闭的时候,消费者及时启动了,也不会从Kafka拉取消息,相当于此时客户端处于消费暂停的状态。待所有机器全部发布完成,再打开NewClient的消费开关,此时消费者会从之前设定好的位点开始消费,这样做虽然会有更多的数据重复,但是消费的顺序性被保证了。
切写阶段
在所有消费者迁移完成,并确定Corgi除了MirrorMaker没有消费请求者之后,才开始生产者的迁移工作,迁移过程如下图所示:
在NewClient中,消息分区选择器模拟了和MirrorMaker一样的生产逻辑,这样就可以保证在Corgi中的一个分区里的所有消息,无论是经过MirrorMaker同步至Kafka,还是用NewClient直接生产至Kafka,都会落到Kafka的同一个分区,这样就保证了生产过程中消息的顺序性。
至此,消费者和生产者就全部迁移完成了,只要在Corgi部署的机器上通过tcp链接来确定再无生产者之后即可下线Corgi的Broker了,Corgi也完成了自己的历史使命。
另外介绍下Corgi客户端相对于Kafka客户端所具有的新特性:
在线回溯:
业务在使用消息队列时经常会有回溯消息的需求,目前Kafka只支持离线回溯,即只有当ConsumerGroup状态为Empty或Dead时,才允许发起回溯请求。这样的逻辑对于在线业务来说是不可接受的,不可能让业务进程全部停掉再消费。所以我们结合业务需求实现了在线回溯功能,方案如下:
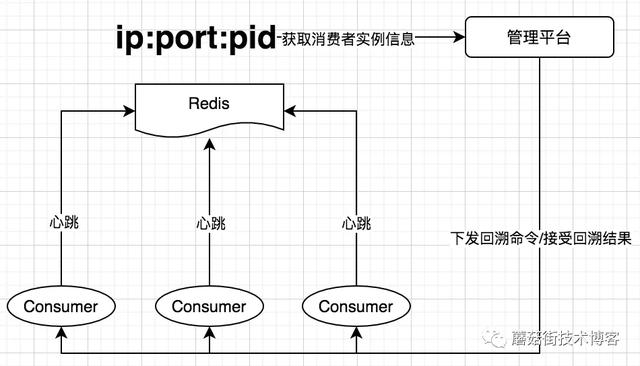
每个Consumer会在本地监听一个端口,并将自己的IP、Port、PID信息上报至Redis中,当业务同学在管理平台发起一个回溯请求之后,管理平台从Redis中获取到消费者的信息,主要是IP和端口,将回溯命令分发给消费者客户端,消费者客户端就会暂停消费,并调用Kafka的seek()方法来完成回溯请求
监控上报:
在NewClient中植入了监控上报的逻辑,监控的维度包含:生产时延及成功率,消费业务逻辑的时延、整体时延(即从消息生产出来到被消费完)及生产成功率
总结
1.在迁移前对相关工作作出充分的调查,了解两种系统之间的差别,底层实现原理,明确好迁移时需要保障的边界条件,那么在选择方案时就会有更明确的理由,和业务同学合作时也会给出更清晰地解答。
2.迁移的决定当初是下了比较大的决心,毕竟有很大的历史包袱在里面,初期的时候也很迷茫。但是如果惧怕一时的不良影响,就要以长期的不良影响做代价,判断一个事情要不要做还是要从长远收益的角度来考虑,畏难的情况是需要避免的。
注意:本文归作者所有,未经作者允许,不得转载

