1 概述
Kafka是最初由Linkedin公司开发,是一个分布式、分区的、多副本的、多订阅者,基于zookeeper协调的分布式消息系统,Linkedin于2010年贡献给了Apache基金会并成为顶级开源项目。
2 消息系统介绍
一个消息系统负责将数据从一个应用传递到另外一个应用,应用只需关注于数据,无需关注数据在两个或多个应用间是如何传递的。分布式消息传递基于可靠的消息队列,在客户端应用和消息系统之间异步传递消息。有两种主要的消息传递模式:点对点传递模式、发布-订阅模式。大部分的消息系统选用发布-订阅模式。Kafka就是一种发布-订阅模式。
2.1 点对点传递模式
生产者发送一条消息到queue,只有一个消费者能收到 ,这种架构描述示意图如下:
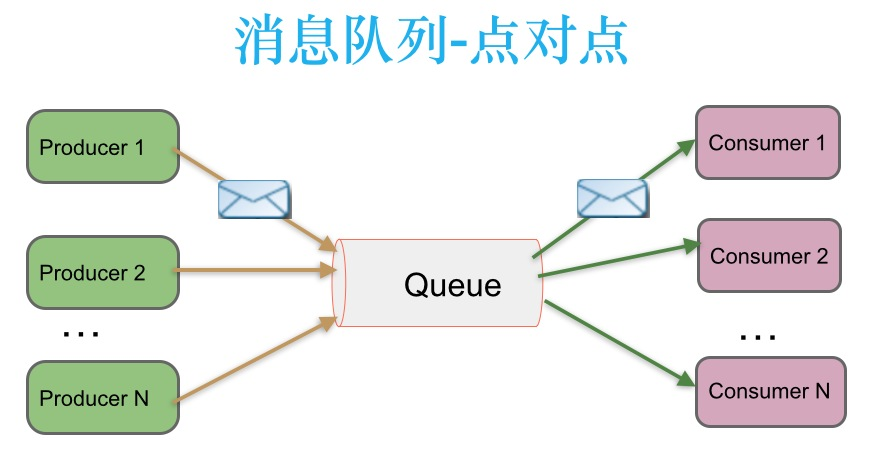
2.2 发布-订阅消息传递模式
发布者发送到topic的消息,只有订阅了topic的订阅者才会收到消息,这种架构描述示意图如下:
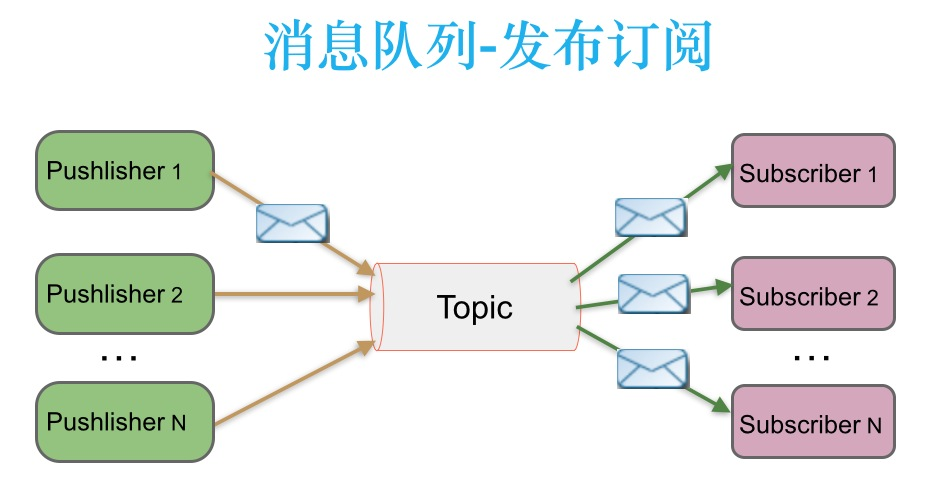
3 Kafka HA设计解析
3.1 如何将所有Replica均匀分布到整个集群
为了更好的做负载均衡,Kafka尽量将所有的Partition均匀分配到整个集群上。一个典型的部署方式是一个Topic的Partition数量大于Broker的数量。同时为了提高Kafka的容错能力,也需要将同一个Partition的Replica尽量分散到不同的机器。实际上,如果所有的Replica都在同一个Broker上,那一旦该Broker宕机,该Partition的所有Replica都无法工作,也就达不到HA的效果。同时,如果某个Broker宕机了,需要保证它上面的负载可以被均匀的分配到其它幸存的所有Broker上。
Kafka分配Replica的算法如下:
1.将所有Broker(假设共n个Broker)和待分配的Partition排序
2.将第i个Partition分配到第(i mod n)个Broker上
3.将第i个Partition的第j个Replica分配到第((i + j) mode n)个Broker上
3.2 消息传递同步策略
Producer在发布消息到某个Partition时,先通过ZooKeeper找到该Partition的Leader,然后无论该Topic的Replication 数量为多少,Producer只将该消息发送到该Partition的Leader。Leader会将该消息写入其本地Log。每个Follower都从Leader pull数据。这种方式上,Follower存储的数据顺序与Leader保持一致。Follower在收到该消息并写入其Log后,向Leader发送ACK。一旦Leader收到了ISR中的所有Replica的ACK,该消息就被认为已经commit了,Leader向Producer发送ACK(前提消息生产者send消息是设置ack=all或-1)。
为了提高性能,每个Follower在接收到数据后就立马向Leader发送ACK,而非等到数据写入Log中。因此,对于已经commit的消息,Kafka只能保证它被存于多个Replica的内存中,而不能保证它们被持久化到磁盘中,也就不能完全保证异常发生后该条消息一定能被Consumer消费。
Consumer读消息也是从Leader读取,只有被commit过的消息才会暴露给Consumer。
Kafka Replication的数据流如下图所示:
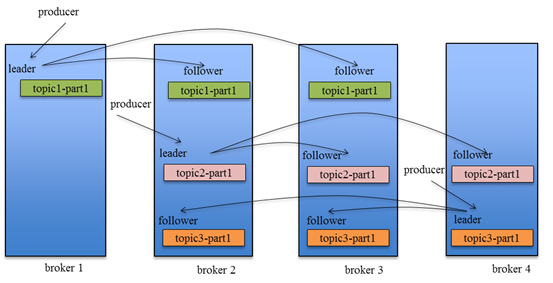
4 高可用机制
4.1 kafka副本
分区中的所有副本统称为AR(Assigned Repllicas)存储在zk中,所有与leader副本保持一定程度同步的副本(包括Leader)组成ISR(In-Sync Replicas),ISR集合是AR集合中的一个子集
1、leader副本:响应客户端的读写请求
2、follow副本:备份leader的数据,不进行读写操作
3、ISR集合表:leader副本和所有能够与leader副本保持基本同步的follow副本,如 果follow副本和leader副本数据同步速度过慢(消息差值超过replica.lag.max.messages阈值 )或者卡住的节点( 心跳丢失超过replica.lag.time.max.ms阈值 ),该follow将会被T出ISR集合表
ISR集合表中的副本必须满足的条件
-
副本所在的节点与zk相连
-
副本的最后一条消息和leader副本的最后一条消息的差值不能超过阈值replica.lag.time.max.ms如果该follower在此时间间隔之内没有追上leader,则该follower将会被T出ISR
4.2 kafka通过两个手段容错
-
数据备份:以partition为单位备份,副本数可设置。当副本数为N时,代表1个leader,N-1个followers,followers可以视为leader的consumer,拉取leader的消息,append到自己的系统中
-
failover:
-
当leader处于非同步中时,系统从followers中选举新leader( kakfa采用一种轻量级的方式:从broker集群中选出一个作为controller,这个controller监控挂掉的broker,为该broker上面的leader分区重新选主 )
-
当某个follower状态变为非同步中时,leader会将此follower剔除ISR,当此follower恢复并完成数据同步之后再次进入 ISR
5 kafka高吞吐机制
5.1、零拷贝——Page Cache 结合 sendfile 方法,Kafka消费端的性能也大幅提升
当Kafka客户端从服务器读取数据时,如果不使用零拷贝技术,那么大致需要经历这样的一个过程:
1.操作系统将数据从磁盘上读入到内核空间的读缓冲区中。
2.应用程序(也就是Kafka)从内核空间的读缓冲区将数据拷贝到用户空间的缓冲区中。
3.应用程序将数据从用户空间的缓冲区再写回到内核空间的socket缓冲区中。
4.操作系统将socket缓冲区中的数据拷贝到NIC缓冲区中,然后通过网络发送给客户端。

非零拷贝
从图中可以看到,数据在内核空间和用户空间之间穿梭了两次,那么能否避免这个多余的过程呢?当然可以,Kafka使用了零拷贝技术,也就是直接将数据从内核空间的读缓冲区直接拷贝到内核空间的socket缓冲区,然后再写入到NIC缓冲区,避免了在内核空间和用户空间之间穿梭。

零拷贝
可见,这里的零拷贝并非指一次拷贝都没有,而是避免了在内核空间和用户空间之间的拷贝。如果真是一次拷贝都没有,那么数据发给客户端就没了不是?不过,光是省下了这一步就可以带来性能上的极大提升。
5.2、分区分段+索引
Kafka的message是按topic分类存储的,topic中的数据又是按照一个一个的partition即分区存储到不同broker节点。每个partition对应了操作系统上的一个文件夹,partition实际上又是按照segment分段存储的,通过这种分区分段的设计,Kafka的message消息实际上是分布式存储在一个一个小的segment中的,每次文件操作也是直接操作的segment。为了进一步的查询优化,Kafka又默认为分段后的数据文件建立了索引文件,就是文件系统上的.index文件。这种分区分段+索引的设计,不仅提升了数据读取的效率,同时也提高了数据操作的并行操作的能力
5.3、批量发送
kafka允许进行批量发送消息,producter发送消息的时候,可以将消息缓存在本地,等到了固定条件发送到kafka
-
等消息条数到固定条数
-
一段时间发送一次
5.4、数据压缩
Kafka还支持对消息集合进行压缩,Producer可以通过GZIP或Snappy格式对消息集合进行压缩 压缩的好处就是减少传输的数据量,减轻对网络传输的压力
6 kafka防止消息丢失和重复
6.1 ack简介
Kafka的ack机制,指的是producer的消息发送确认机制,这直接影响到Kafka集群的吞吐量和消息可靠性。
ack有3个可选值,分别是1,0,-1,ack的默认值就是1
ack=1,简单来说就是,producer只要收到一个leader成功写入的通知就认为推送消息成功了——至少一次(at least once): 消息不会丢失,但可能被处理多次。
ack=0,简单来说就是,producer发送一次就不再发送了,不管是否发送成功——最多一次(at most once): 消息可能丢失也可能被处理,但最多只会被处理一次
ack=-1,简单来说就是,producer只有收到分区内所有副本的成功写入的通知才认为推送消息成功了
6.2 生产者丢失和重复
6.2.1 数据丢失的情况
当ack=0时,如果有一台broker挂掉,那么那台broker就会接收不到这条消息
当ack=1时,如果有一台follower挂掉,那么这台follower也会丢失这条消息,
或者follower还未同步leader的数据,leader挂了,也会丢失消息
6.2.2 数据重复的情况
当ack=-1时,只要有一台follower没有与leader同步,生产者就会重新发送消息,这就照成了消息的重复
6.2.3 避免方法
开启精确一次性,也就是幂等性, 再引入producer事务 ,即客户端传入一个全局唯一的Transaction ID,这样即使本次会话挂掉也能根据这个id找到原来的事务状态
enable.idempotence=true
开启后,kafka首先会让producer自动将 acks=-1,再将producer端的retry次数设置为Long.MaxValue,再在集群上对每条消息进行标记去重!
6.2.4 去重原理
每个生产者线程生成的每条数据,都会添加由生产者id,分区号,随机的序列号组成的标识符: (producerid,partition,SequenceId),通过标识符对数据进行去重!
但是只能当次会话有效,如果重启了就没有效果,所以需要开启事务的支持,由客户端传入一个全局唯一的Transaction ID,这样即使本次会话挂掉也能根据这个id找到原来的事务状态。
6.3 消费者重复消费
6.3.1 重复消费直接原因
消费者是以维护offset的方式来消费数据的,所以如果在提交offset的过程中出问题,就会造成数据的问题,即已经消费了数据,但是offset没提交
6.3.2 解决办法
1.手动维护offset
2.加大这个参数kafka.consumer.session.timeout,以避免被错误关闭的情况
3.加大消费能力
4.在下游对数据进行去重
7 kafka消息如何确定发送到Partition分区
7.1 生产者在发送消息时指定一个partition
|
1
2
3
4
5
6
7
8
9
10
11
12
|
ProducerRecord(String topic, Integer partition, K key, V value)Creates a record to be sent to a specified topic and partitionProducerRecord(String topic, Integer partition, K key, V value, Iterable<Header> headers)Creates a record to be sent to a specified topic and partitionProducerRecord(String topic, Integer partition, Long timestamp, K key, V value)Creates a record with a specified timestamp to be sent to a specified topic and partitionProducerRecord(String topic, Integer partition, Long timestamp, K key, V value, Iterable<Header> headers)Creates a record with a specified timestamp to be sent to a specified topic and partitionProducerRecord(String topic, K key, V value)Create a record to be sent to KafkaProducerRecord(String topic, V value)Create a record with no key |
7.2 kafka的消息内容包含了key-value键值对,key的作用之一就是确定消息的分区所在。默认情况下, kafka 采用的是 hash 取模的分区算法即 hash(key) % partitions.size
7.3 既没指定partition也没有key 则”metadata.max.age.ms”的时间范围内轮询算法选择一个
8 kafka消息如何确定Partition分区到Consumer
如果所有的消费者实例在同一消费组中,消息记录会负载平衡到每一个消费者实例。
如果所有的消费者实例在不同的消费组中,每条消息记录会广播到消费组中所有的消费者进程。
如图,这个 Kafka 集群有两台 server 的,四个分区(p0-p3)和两个消费者组。消费组A有两个消费者,消费组B有四个消费者。
c1、c2在一个group A中消费不同的P,同样group B也是这样,保证消费中某个节点丢失可以正常消费
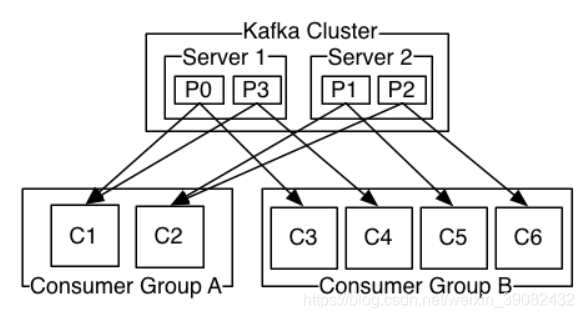
9 kafka强依赖于ZooKeeper的工作原理
10 kafka如何保证数据的顺序消费——案例
10.1 关于顺序消费的几点说明:
①、kafka的顺序消息仅仅是通过partitionKey,将某类消息写入同一个partition,一个partition只能对应一个消费线程,以保证数据有序。
②、除了发送消息需要指定partitionKey外,producer和consumer实例化无区别。
③、kafka broker宕机,kafka会有自选择,所以宕机不会减少partition数量,也就不会影响partitionKey的sharding。
10.2 问题:在1个topic中,有3个partition,那么如何保证数据的消费?
1、如顺序消费中的第①点说明,生产者在写的时候,可以指定一个 key, 比如说我们指定了某个订单 id 作为 key,那么这个订单相关的数据,一定会被分发到同一个 partition 中去,而且这个 partition 中的数据一定是有顺序的。
2、消费者从 partition 中取出来数据的时候,也一定是有顺序的。到这里,顺序还是 ok 的,没有错乱。
3、但是消费者里可能会有多个线程来并发来处理消息。因为如果消费者是单线程消费数据,那么这个吞吐量太低了。而多个线程并发的话,顺序可能就乱掉了。
10.3 解决方案
写N个queue,将具有相同key%的数据都存储在同一个queue,然后对于N个线程,每个线程分别消费一个queue即可。
注:在单线程中,一个 topic,一个 partition,一个 consumer,内部单线程消费,这样的状态数据消费是有序的。但由于单线程吞吐量太低,在数据庞大的实际场景很少采用。
原文:https://my.oschina.net/u/4938149/blog/4939207
注意:本文归作者所有,未经作者允许,不得转载

