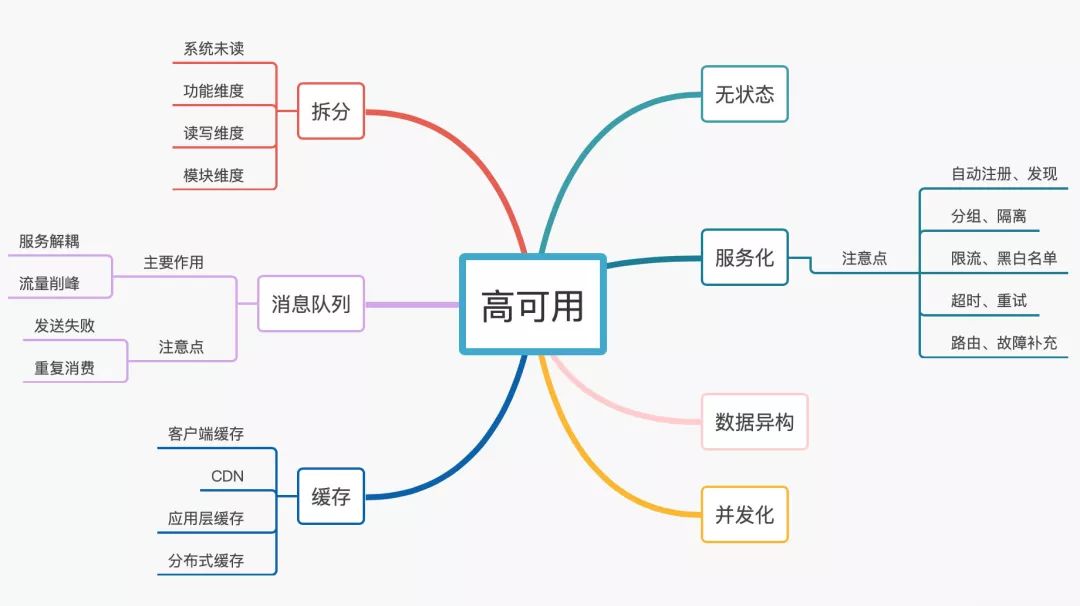
高并发设计可以从以下几方面考虑:
无状态
拆分
服务化
消息队列
数据异构
缓存
并发化
1. 无状态
无状态的应用容易进行水平扩展。
实际常用:应用无状态,配置文件有状态,例如,不同的机房读取不同的配置文件,通过配置中心指定。
2. 拆分
拆分维度:
系统维度:根据业务功能拆分,例如商品系统、购物车、结算、订单系统。
功能维度:对一个系统进行功能再拆分,比如,优惠券系统可以拆分为创建系统、领券系统、用券系统。
读写维度:根据读写比例进行拆分,例如,商品系统中读的量大于写,可以拆分为商品写服务、商品读服务;写的量大时,可以分库分表。
模块维度:按照基础或者代码维护特征进行拆分,例如基础模块分库分表、数据库连接池等;代码结构按照三层结构划分。
3. 服务化
服务化需要考虑自动服务注册,和服务发现,还有服务的分组/隔离,例如,有的系统访问量,导致把整个服务打挂,因此,需要为不同的调用方提供不同的服务分组,隔离访问。
后期随着调用量的增加还要考虑限流、黑白名单等。
还有一些其他的注意点,例如超时时间、重试机制、服务路由、故障补偿等。
4. 消息队列
消息队列用来解耦一些不需要同步调用的服务,或者订阅一些自己系统关心的变化。
消息队列可以实现服务解耦、异步处理、流量销峰等,例如,订单产生系统、定期推送系统、订单风控系统等等。
使用消息队列,需要考虑如何处理消息发送失败,以及重复消费的情况。
有的消息队列有自动重试功能,如果重试多次还未成功,就通知发送失败,这时,就要做好后续的数据处理工作,例如持久化数据要同时增加日志、报警等。
对于消息重复消费问题,需要在业务层面进行防重处理。
应用示例:电商促销时,流量会比平时高出几倍甚至几十倍,这就需要特殊的设计来保证系统平稳,一般是牺牲强一致性,保证最终一致性,如扣减库存,直接在 redis 中扣减,记录下日志,通过 worker 同步到数据库。
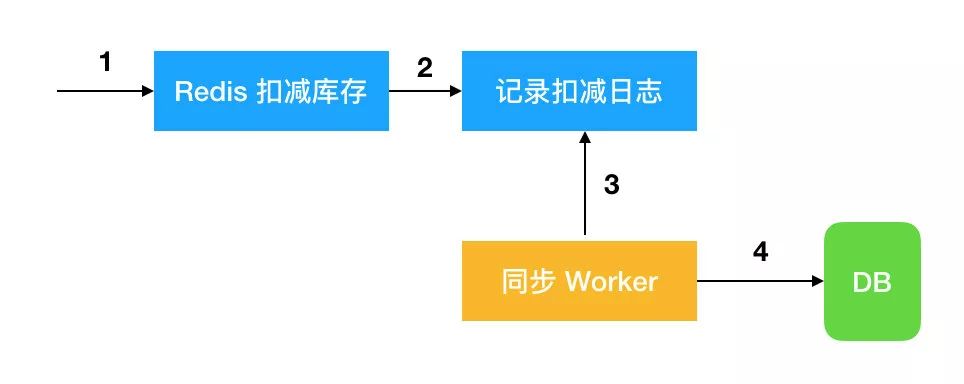
再比如订单系统,可以这样设计:
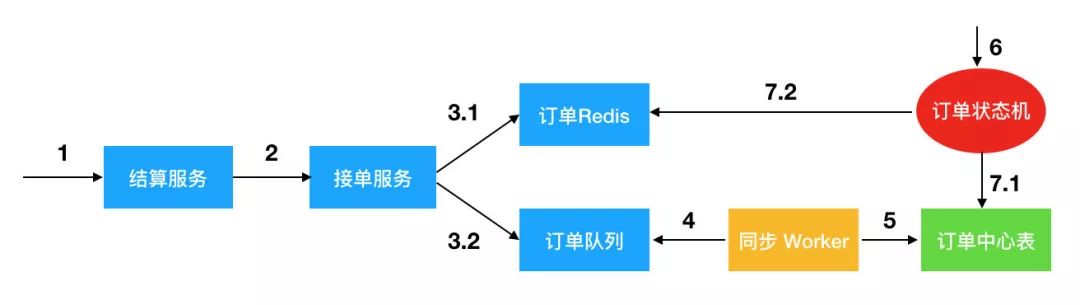
结算服务调用订单接单服务,将订单存储到 redis 和订单队列中。订单redis用于用户查看订单详情,通过队列提升接单能力。
然后通过同步Worker把队列中的订单同步到数据库。
当订单状态发生变化,例如用户支付了,订单状态机负责驱动状态的变更,更新数据库和redis。
5. 数据异构
数据量大了以后,通常会分库分表,例如订单表,拆分时通常根据订单ID进行划分,但如果查询某个用户的订单时,就比较麻烦了,需要聚合多个表,这种情况一般都会生成一个“用户ID”维度的数据,供业务直接调用。或者有跨库join查询时,将需要join的多个表按照某个维度又聚合在一个库中。这类做法就叫做“数据异构”。
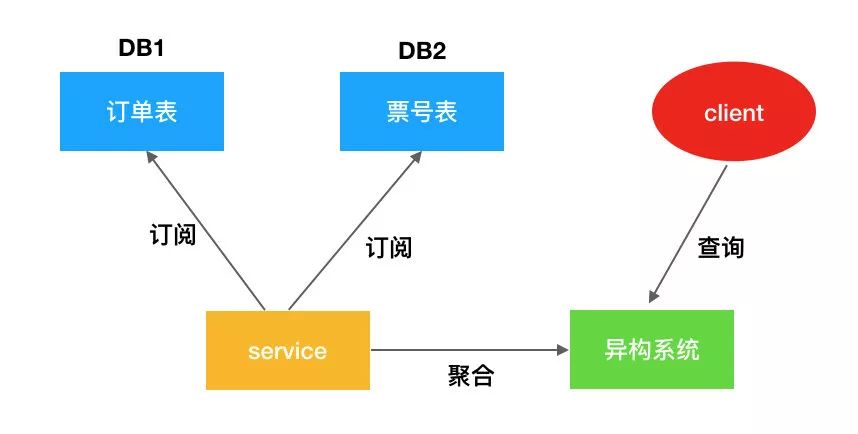
6. 缓存
(1)浏览器、APP客户端缓存
(2)CDN 缓存
(3)应用层缓存
(4)分布式缓存,应用示例:

7. 并发化
例如一个读服务需要如下数据:
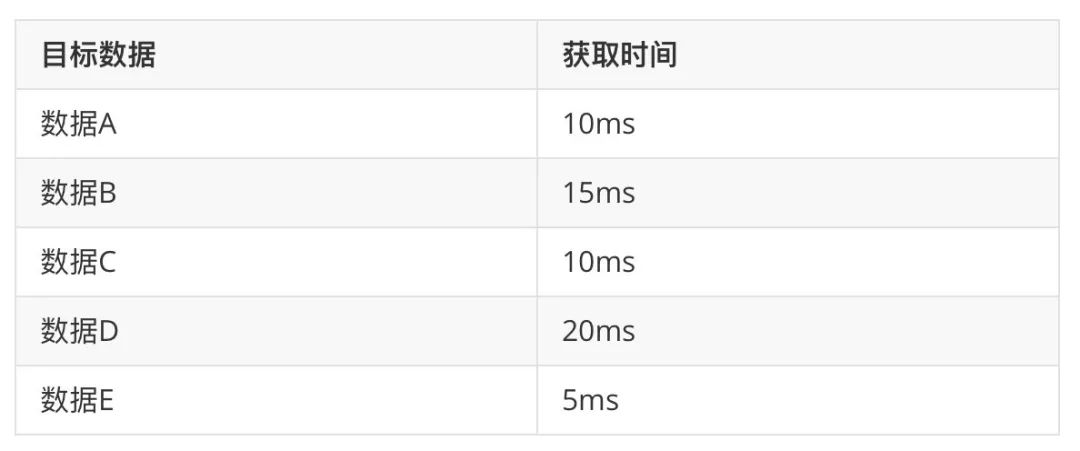
如果串行,共需要60ms。
如果 C 依赖 A 和 B,D 没有任何依赖,E 依赖 C,那么就可以并行获取数据:
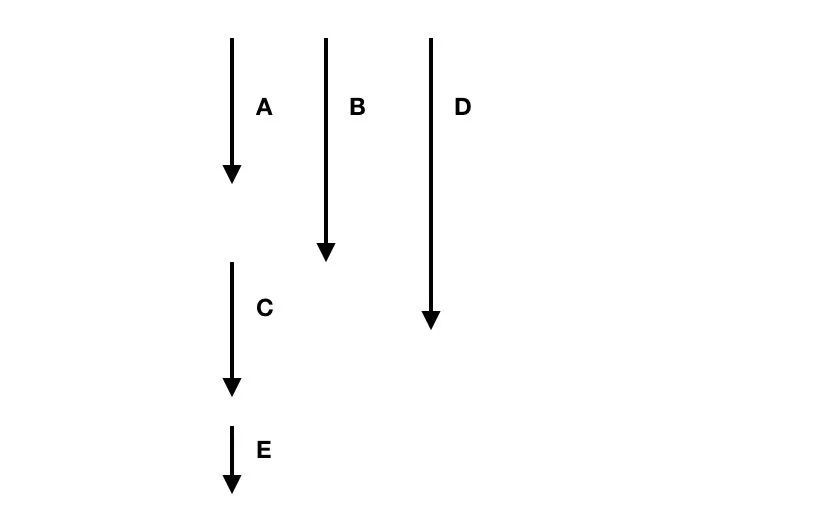
并发化处理,共需要30ms,性能提升了一倍。
总结
内容整理自张开涛的《亿级流量网站架构核心技术》,推荐详读。
---------------END----------------
后续的内容同样精彩
长按关注“IT实战联盟”哦

注意:本文归作者所有,未经作者允许,不得转载

