1. 库存超发的原因是什么?
在执行商品购买操作时,有一个基本流程:
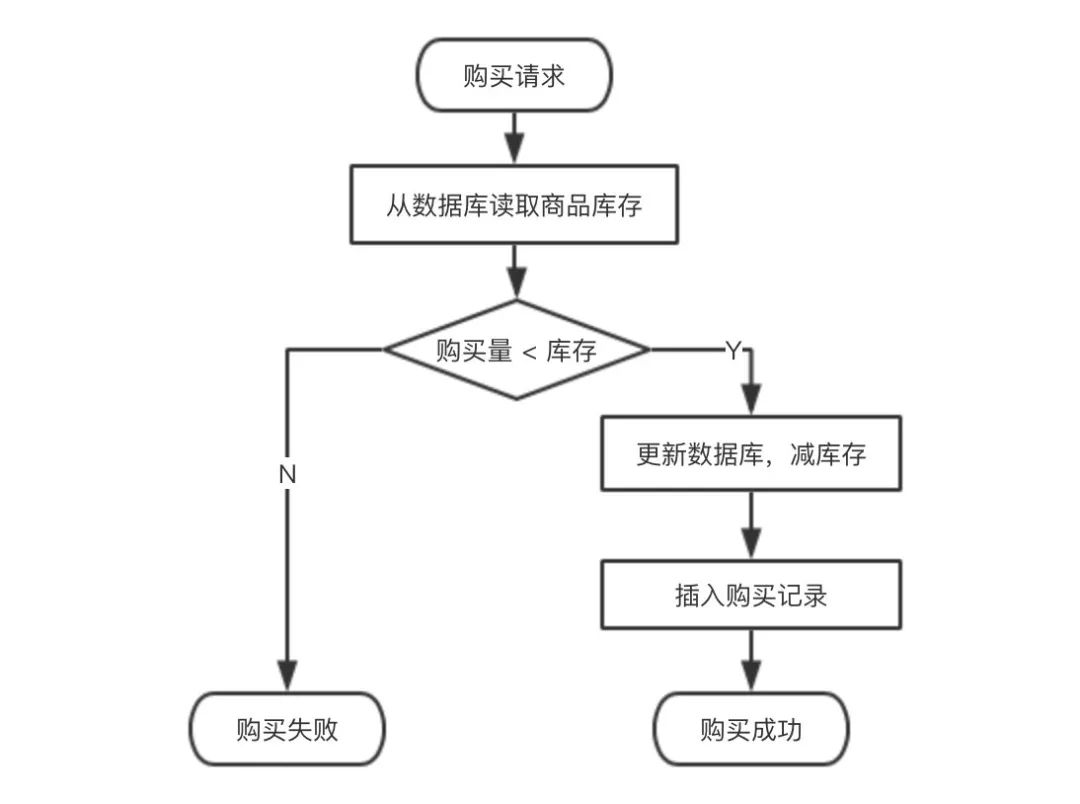
例如初始库存有3个。
第一个购买请求来了,想买2个,从数据库中读取到库存有3个,数量够,可以买,减库存后,更新库存为1个。
接下来第二个购买请求来了,想买2个,发现库存为1,不够,不可以买了。
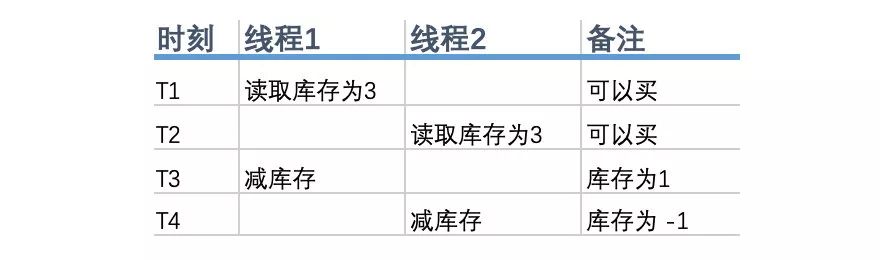
这样是没问题的,但在高并发情况下,这2个购买请求很可能是一起来的,他们都读到库存是3,都可以买,就都去减库存,这时超发就发生了,结果库存变成 -1了。
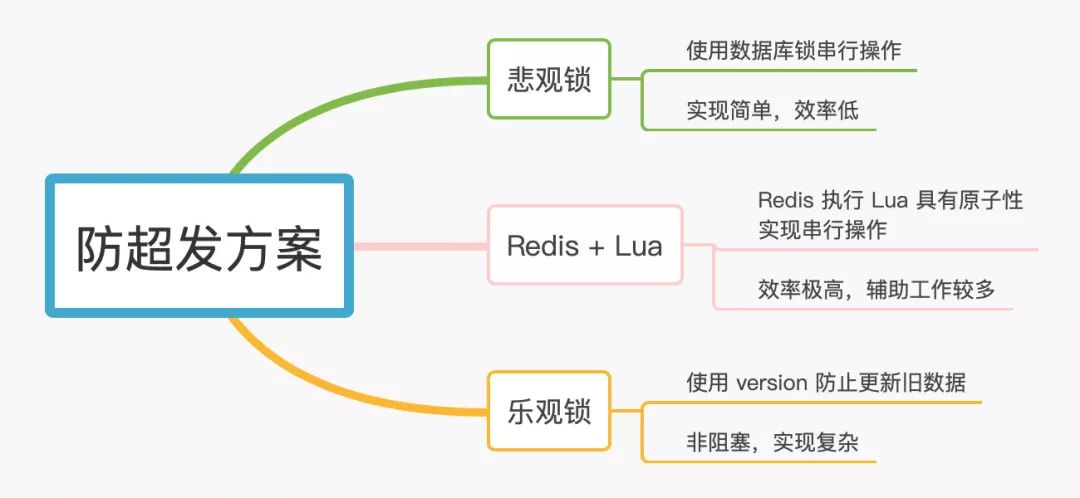
有多种方案来解决这个问题,我们主要看3种方案:
悲观锁
乐观锁
Redis + Lua
下面分别看一下各个方案的实现思路,和优缺点。
2. 解决方案
2.1 悲观锁
出现超发现象的根本在于共享的数据被多个线程所修改,多个线程交织在一起。
如果一个线程读库存时就将数据锁定,不允许别的线程进行读写操作,直到库存修改完成才释放锁,那么就不会出现超发问题了。
例如:
// 事务开始
select id, product_name, stock, ...
from t_product
where id=#{id} for update
update t_product
set stock = stock - #{quantity}
where id = #{id}
// 事务结束
在查询库存时使用了 for update,这样在事务执行的过程中,就会锁定查询出来的数据,其他事务不能对其进行读写(注意,读也不行),这就避免了数据的不一致,直至事务完成释放锁。
优点
思路简单,代码实现也非常简单,从数据库层面解决了超发问题。
缺点
这种独占锁的方式对性能的影响是比较大的。
2.2 乐观锁
悲观锁有效但不高效,为了提高性能,出现了乐观锁方案,不使用数据库锁,不阻塞线程并发。
思路:
给商品记录添加一个 version 字段,读取库存时拿到这个 version 版本,更新库存时要对比这个 version 值,如果版本相同,说明库存没被别人改过,可以更新,同时把 version 值加1,如果版本不同,说明被别人改过了,则取消库存修改操作,购买失败。

update t_product
set stock = stock - #{quantity},
version = version +1
where id = #{id} and version = #{version}
通过 version 版本号,就可以知道自己读取的数据在更新时是不是旧的,如果是旧数据,就不能更新了。
这种方式有点像碰运气,运气好,没人和我一起更新,那么就成功;如果运气不好,被别人抢先修改了,那么就失败。
从而可以知道,在并发量很大的时候,失败的概率会比较高。
为了提升成功率,可以引入重试机制,当更新失败后,再走一遍流程(读取、更新),具体重走几遍比较好呢?可以规定一个次数,例如3次,如果重试了3次还是失败,就放弃;还可以规定一个时间段,比如在 100ms 内循环操作,期间如果某次成功了就退出,否则一直重试到时间到为止。
优点
没有阻塞,性能优于悲观锁。
缺点
实现思路较悲观锁复杂,增加了 version 的控制,还需要添加重试机制。
2.3 Redis + Lua
在高并发环境中,数据库的方案较慢,如果写入内存的 Redis 就会快很多。
此方案思路与悲观锁类似,都是把查询库存的操作与更新库存的操作绑定在一起,不被其他线程影响,区别在于存储介质,从数据库换为Redis。
Lua 脚本中可以编写逻辑(取库存、判断是否够用、更新库存),Redis 中执行 Lua 时可以保证原子性,所以能够满足我们的需求,而且内存操作非常快,我们也不用担心性能。
Lua 脚本的逻辑:
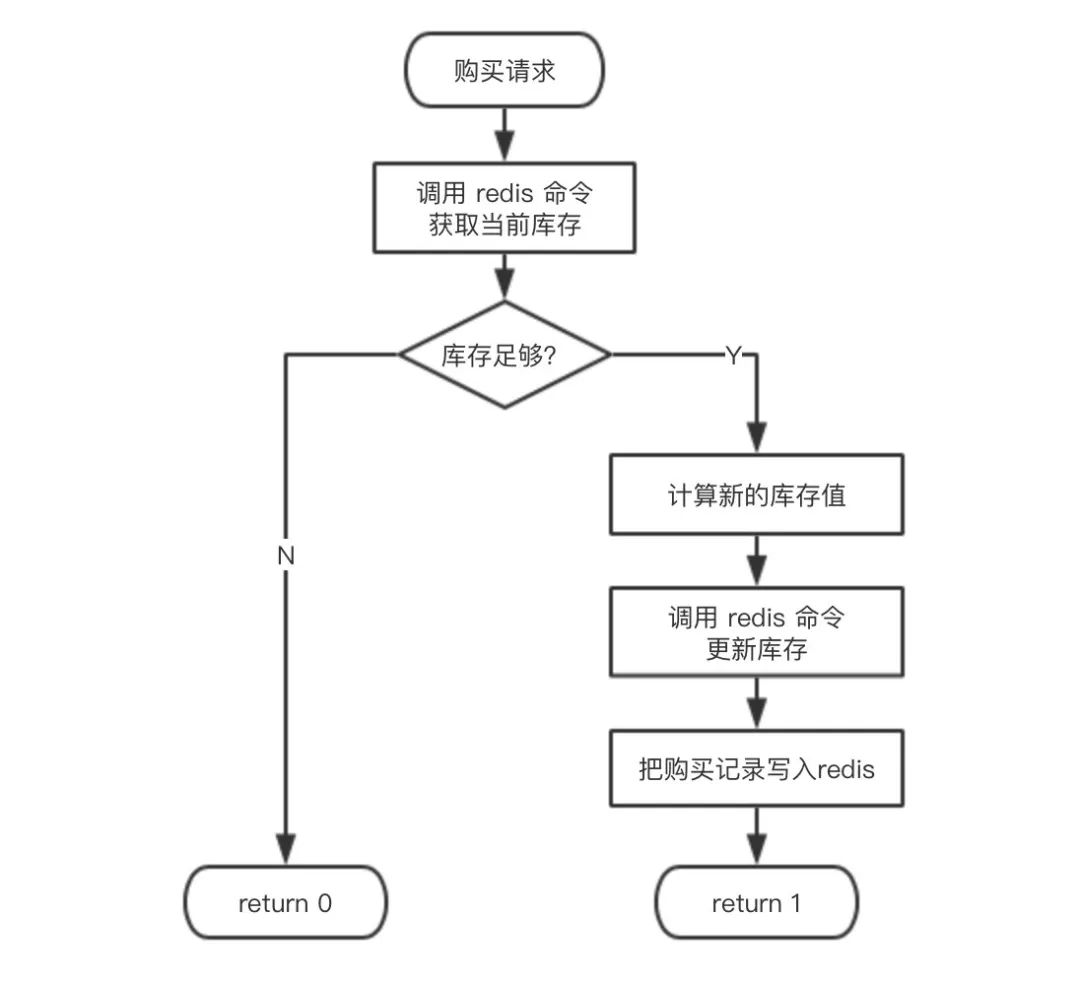
示例代码:
-- 获取当前库存
local stock = tonumber(redis.call('hget', product, 'stock'))
-- 如果库存小于购买数量,说明库存不足,返回0(失败)
if stock < quantity then return 0 end
-- 减少库存,得到新的库存数量
stock = stock - quantity
-- 更新库存
redis.call('hset', product, 'stock', tostring(stock))
-- 字符串拼接,生成购买记录
local purchaseRecord = ...
-- 把购买记录保存到 redis
redis.call('rpush', purchaseList, purchaseRecord)
-- 返回1(成功)
return 1
我们的程序接收到用户的购买请求时,就调用 Lua 进行处理。
上面的处理流程中有一步”把购买记录写入 redis“,这是因为 redis 不适合做持久化,我们还是需要把数据同步到数据库中,可以使用一个定时程序,把 redis 中的记录写入数据库。购买记录也可以不放在 redis 中,写入消息队列,然后通过消费者同步到数据库。
优点
性能最优,实现简单。
缺点
增加了辅助工作,需要额外处理数据库的同步,还要保证 redis 本身是高可用的。
3. 小结
---------------END----------------
后续的内容同样精彩
长按关注“IT实战联盟”哦

注意:本文归作者所有,未经作者允许,不得转载

