关系数据库经过几十年的发展,已经非常成熟,但同时也存在不足:
存储的是行记录,无法存储数据结构
例如微博的关注关系,“我关注的人”是一个用户ID列表,使用关系数据库只能将列表拆成多行,然后查询组装,无法直接存储一个列表。
schema 扩展不方便
表结构是强约束的,业务变更时扩充很麻烦。
在大数据场景下 I/O 较高
如果对大数据量的表进行统计运算,I/O会很高,因为即使只针对某列进行运算,也需要将整行数据读入内存。
搜索功能较弱
全文搜索只能使用 Like 进行整表扫描,性能非常低。
针对这些不足,产生了不同的 NoSQL 解决方案,在某些场景下比关系数据库更有优势,但同时也牺牲了某些特性,所以不能片面的迷信某种方案,应将其作为 SQL 的有利补充。
NoSQL != No SQL,而是:
NoSQL = Not Only SQL
典型的 NoSQL 方案分为4类:
K-V 存储
解决存储数据结构的问题,以 Redis 为代表。
文档数据库
解决 schema 强约束的问题,以 MongoDB 为代表。
列式数据库
解决大数据下 I/O 问题,以 HBASE 为代表。
全文搜索引擎
解决全文搜索性能问题,以 ElasticSearch 为代表。
1. K-V 存储
Redis 是典型,其 value 是具体的数据结构,包括 string, hash, list, set, sorted set, bitmap, hyperloglog,常被称为数据结构服务器。
以 list 为例:
LPOP key 是移除并返回队列左边的第一个元素。
如果用关系数据库就比较麻烦了,需要操作:
为每条数据添加 位置编号,否则没法判断哪条数据是第一条。不能用ID作为位置编号,因为会往列表头部插入数据。
查询出第一条数据。
删除第一条数据。
更新从第二条开始的所有数据的位置编号。
Redis 的缺点主要体现在不支持完成的ACID事务,只能保证隔离性和一致性,无法保证原子性和持久性。
2. 文档数据库
最大的特点是 no-schema,无需在使用前定义字段,读取一个不存在的字段也不会导致语法错误。
特点:
新增字段简单。
兼容历史数据,即使没有新增字段,不会出错。
很容易存储复杂数据,使用 JSON 描述数据,比关系数据库方便得多。
以电商为例,不同商品的属性差异很大,如冰箱和电脑,这种差异性在关系数据库中会有很大的麻烦,而使用文档数据库则非常方便。
文档数据库的主要缺点:
不支持事务
无法实现 join 操作
3. 列式数据库
关系数据库是按行来存储的,列式数据库是按照列来存储数据。
按行存储的优势:
同时读取多个列时效率高,一次磁盘操作就把一行数据中的各列都读取到内存了。
能够一次完成对一行中多个列的写操作,保证了对行数据写操作的原子性和一致性;如果使用列式存储,可能出现多次写操作,因为这些列都不在一起存储。
在某些场景下,这些优势就成为劣势了,例如,计算超重人员的数据,只需要读取体重这一列进行统计即可,但行式存储会将整行数据读取到内存中,很浪费。
而列式存储中,只需要读取体重这列的数据即可,I/O 将大大减少。
除了节省I/O,列式存储还有更高的压缩比,可以节省存储空间。普通行式数据库的压缩比在 3:1 到 5:1 左右,列式数据库在 8:1 到 30:1,因为单个列的数据相似度更高。
列式存储的随机写效率远低于行式存储,因为行式存储时同一行多个列都存储在连续空间中,而列式存储将不同列存储在不连续的空间。
一般将列式存储应用在离线大数据分析统计场景,因为这时主要针对部分列进行操作,而且数据写入后无须更新。
4. 全文搜索引擎
关系数据库通过索引进行快速查询,但在全文搜索的情景下,索引就不够了,因为:
全文搜索的条件可以随意排列组合,索引很难满足。
全文搜索的模糊匹配方式,索引无法满足,只能用 like,效率极低。
假设有一个交友网站,信息表如下:

美女1:我要找在上海做PHP的哥哥。
需要匹配性别、地点、语言列。
美女2:我要找北京爱旅游的哥哥。
需要匹配性别、地点、爱好列。
实际搜索中,各种排列组合非常多,关系数据库很难支持。
全文搜索引擎是使用倒排索引技术,建立单词到文档的索引,例如上面的表信息建立倒排索引:
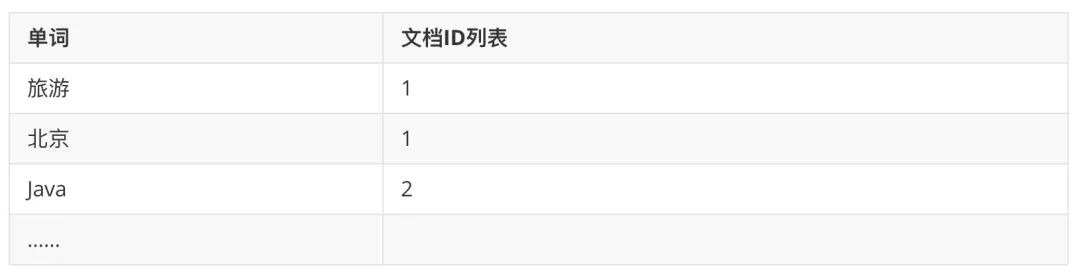
所以特别适合根据关键词来查询文档内容。
小结
上面介绍了几种典型的NoSQL方案,及各自的适用场景和特点,您可以根据实际需求进行选择。
---------------END----------------
后续的内容同样精彩
长按关注“IT实战联盟”哦

注意:本文归作者所有,未经作者允许,不得转载

