随着业务复杂度的提升以及微服务的兴起,传统单一项目会被按照业务规则进行垂直拆分,另外为了防止单点故障我们也会将重要的服务模块进行集群部署,通过负载均衡进行服务的调用。那么随着节点的增多,各个服务的日志也会散落在各个服务器上。这对于我们进行日志分析带来了巨大的挑战,总不能一台一台的登录去下载日志吧。那么我们需要一种收集日志的工具将散落在各个服务器节点上的日志收集起来,进行统一的查询及管理统计。那么ELK就可以做到这一点。ELK是ElasticSearch+Logstash+Kibana的简称
1.1、ElasticSearch(简称ES)
Elasticsearch是一个高度可扩展的开源全文搜索和分析引擎。它允许您快速、实时地存储、搜索和分析大量数据。它通常用作底层引擎/技术,为具有复杂搜索特性和需求的应用程序提供动力。我们可以借助如ElasticSearch完成诸如搜索,日志收集,反向搜索,智能分析等功能
1.2、Logstash
Logstash是一个开源数据收集引擎,具有实时流水线功能。Logstash可以动态地将来自不同数据源的数据统一起来,并将数据规范化后(通过Filter过滤)传输到您选择的目标。

在这里inputs代表数据的输入通道,大家可以简单理解为来源。常见的可以从kafka,FileBeat, DB等获取日志数据,这些数据经过fliter过滤后(比如说:日志过滤,json格式解析等)通过outputs传输到指定的位置进行存储(Elasticsearch,Mogodb,Redis等)
简单的实例:
cd logstash-6.4.1
bin/logstash -e 'input { stdin { } } output { stdout {} }'
1.3、Kibana
kibana是用于Elasticsearch检索数据的开源分析和可视化平台。我们可以使用Kibana搜索、查看或者与存储在Elasticsearch索引中的数据交互。同时也可以轻松地执行高级数据分析并在各种图表、表和映射中可视化数据。基于浏览器的Kibana界面使您能够快速创建和共享动态仪表板,实时显示对Elasticsearch查询的更改。
1.4、处理方案
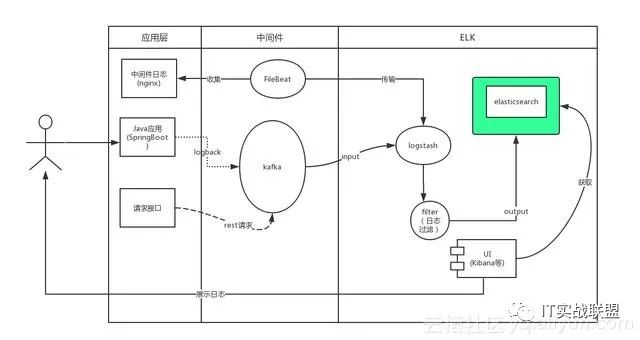
用户通过java应用程序的Slf4j写入日志,SpringBoot默认使用的是logback。我们通过实现自定义的Appender将日志写入kafka,同时logstash通过input插件操作kafka订阅其对应的主题。当有日志输出后被kafka的客户端logstash所收集,经过相关过滤操作后将日志写入Elasticsearch,此时用户可以通过kibana获取elasticsearch中的日志信息
二、SpringBoot中的配置
在SpringBoot当中,我们可以通过logback-srping.xml来扩展logback的配置。不过我们在此之前应当先添加logback对kafka的依赖,代码如下:

添加好依赖之后我们需要在类路径下创建logback-spring.xml的配置文件并做如下配置(添加kafka的Appender):
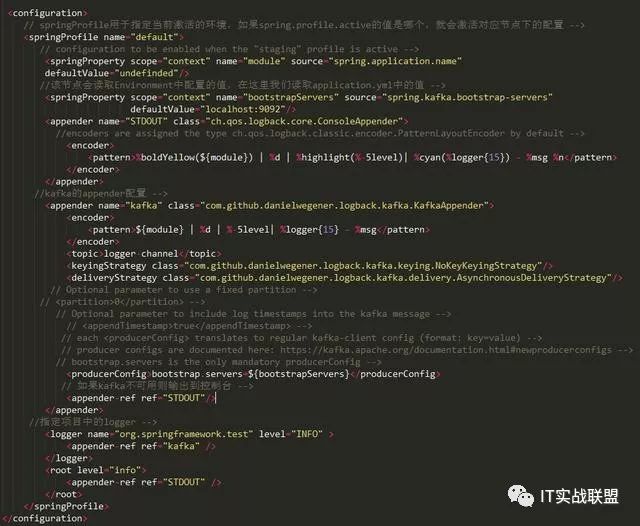
在这里面我们主要注意以下几点:
日志输出的格式是为模块名 | 时间 | 日志级别 | 类的全名 | 日志内容
SpringProfile节点用于指定当前激活的环境,如果spring.profile.active的值是哪个,就会激活对应节点下的配置
springProperty可以读取Environment中的值
三、ELK搭建过程
3.1、检查环境
ElasticSearch需要jdk8,官方建议我们使用JDK的版本为1.8.0_131,原文如下:
Elasticsearch requires at least Java 8. Specifically as of this writing, it is recommended that you use the Oracle JDK version 1.8.0_131
检查完毕后,我们可以分别在官网下载对应的组件
ElasticSearch
Kibana
Logstash
kafka
zookeeper
3.2、启动zookeeper
首先进入启动zookeeper的根目录下,将conf目录下的zoo_sample.cfg文件拷贝一份重新命名为zoo.cfg
mv zoo_sample.cfg zoo.cfg
配置文件如下:
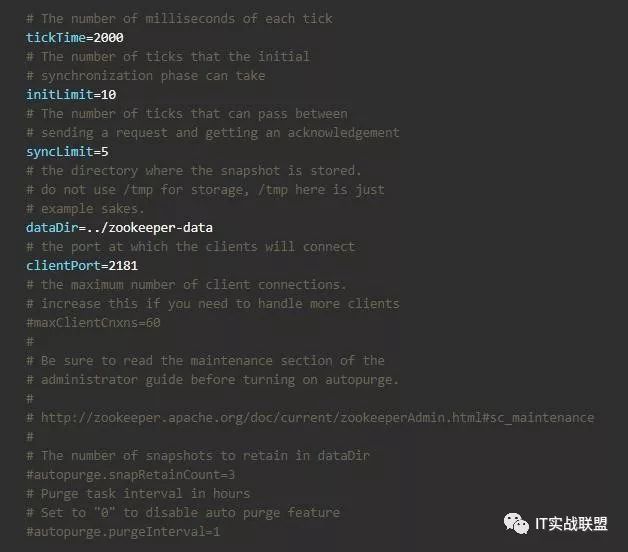
紧接着我们进入bin目录启动zookeeper:
./zkServer.sh start
3.3、启动kafka
在kafka根目录下运行如下命令启动kafka:
./bin/kafka-server-start.sh config/server.properties
启动完毕后我们需要创建一个logger-channel主题:
./bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic logger-channel
3.4、配置并启动logstash
进入logstash跟目录下的config目录,我们将logstash-sample.conf的配置文件拷贝到根目录下重新命名为core.conf,然后我们打开配置文件进行编辑:

我们分别配置logstash的input,filter和output(懂ruby的童鞋们肯定对语法结构不陌生吧):
在input当中我们指定日志来源为kafka,具体含义可以参考官网:kafka-input-plugin
在filter中我们配置grok插件,该插件可以利用正则分析日志内容,其中patterns_dir属性用于指定自定义的分析规则,我们可以在该文件下建立文件配置验证的正则规则。举例子说明:55.3.244.1 GET /index.html 15824 0.043的 日志内容经过如下配置解析:
grok {
match => { "message" => "%{IP:client} %{WORD:method} % {URIPATHPARAM:request} %{NUMBER:bytes} %{NUMBER:duration}" }
}
解析过后会变成:
client: 55.3.244.1
method: GET
request: /index.html
bytes: 15824
duration: 0.043
这些属性都会在elasticsearch中存为对应的属性字段。更详细的介绍请参考官网:grok ,当然该插件已经帮我们定义好了好多种核心规则,我们可以在这里查看所有的规则。
在output当中我们将过滤过后的日志内容打印到控制台并传输到elasticsearch中,我们可以参考官网上关于该插件的属性说明:地址
另外我们在patterns文件夹中创建好自定义的规则文件logback,内容如下:
# yyyy-MM-dd HH:mm:ss,SSS ZZZ eg: 2014-01-09 17:32:25,527
LOGBACKTIME 20%{YEAR}-%{MONTHNUM}-%{MONTHDAY} %{HOUR}:?%{MINUTE}(?::?%{SECOND})
编辑好配置后我们运行如下命令启动logstash:
bin/logstash -f first-pipeline.conf --config.reload.automatic
该命令会实时更新配置文件而不需启动
3.5、启动ElasticSearch
启动ElasticSearch很简单,我们可以运行如下命令:
./bin/elasticsearch
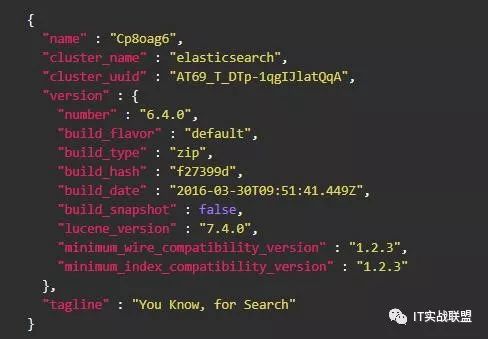
我们可以发送get请求来判断启动成功:
GET http://localhost:9200
我们可以得到类似于如下的结果:
3.5.1 配置IK分词器(可选)
我们可以在github上下载elasticsearch的IK分词器,地址如下:ik分词器,然后把它解压至your-es-root/plugins/ik的目录下,我们可以在{conf}/analysis-ik/config/IKAnalyzer.cfg.xmlor {plugins}/elasticsearch-analysis-ik-*/config/IKAnalyzer.cfg.xml 里配置自定义分词器:
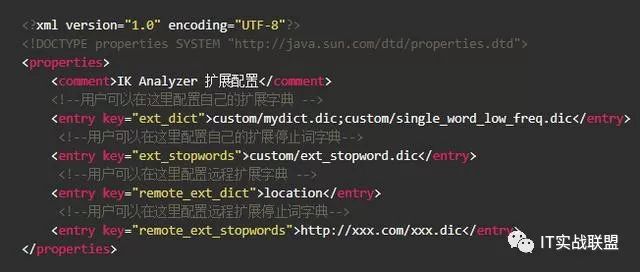
首先我们添加索引:
curl -XPUT http://localhost:9200/my_index
我们可以把通过put请求来添加索引映射:
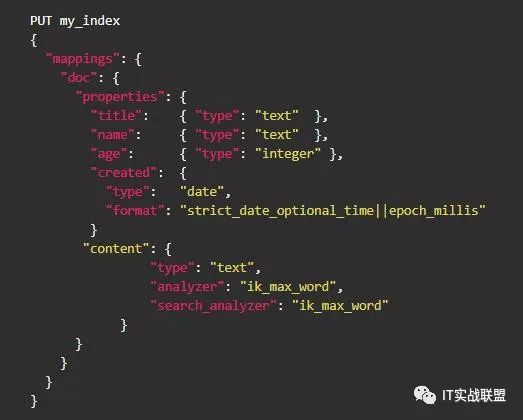
其中doc是映射名 my_index是索引名称
3.5.2 logstash与ElasticSearch
logstash默认情况下会在ES中建立logstash-*的索引,*代表了yyyy-MM-dd的时间格式,根据上述logstash配置filter的示例,其会在ES中建立module ,logmessage,class,level等索引。(具体我们可以根据grok插件进行配置)
3.6 启动Kibana
在kibana的bin目录下运行./kibana即可启动。启动之后我们可以通过浏览器访问http://localhost:5601 来访问kibanaUI。我们可以看到如下界面:
---------------END----------------
后续的内容同样精彩
长按关注“IT实战联盟”哦

注意:本文归作者所有,未经作者允许,不得转载

