https://juejin.cn/post/6944894142652612638
前言
大家好,我是jack xu,本文是RockeMQ精讲系列的最后一篇,讲的是RockeMQ一些进阶高级的知识,在我们平时的面试中会用到,掌握了这些东西也是体现一个高手和crud boy的区别。
为了使大家能够清晰明了,有层次的掌握这些知识,我们从生产者、Broker、消费者三个维度来讲解。
生产者
消息发送规则
在RocketMQ中,是基于多个Message Queue来实现类似于kafka的分区效果。如果一个Topic要发送和接收的数据量非常大,需要能支持增加并行处理的机器来提高处理速度,这时候一个Topic可以根据需求设置一个或多个Message Queue。Topic有了多个Message Queue 后,消息可以并行地向各个Message Queue发送,消费者也可以并行地从多个Message Queue读取消息并消费。
那么一个消息会发送到哪个Message Queue上呢,这个就需要我们的路由分发策略了。在Send的众多重载方法中,有这样一个参数 MessageQueueSelector。
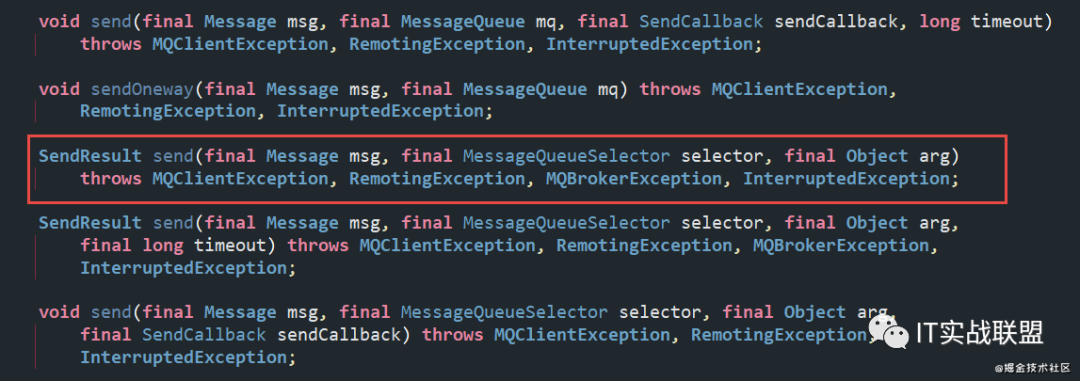
RocketMQ中已经帮我们实现了三个实现类:
- SelectMessageQueueByHash(默认):它是一种不断自增、轮询的方式。
- SelectMessageQueueByRandom:随机选择一个队列。
- SelectMessageQueueByMachineRoom:返回空,没有实现。
如果上面这几个不能满足我们的需求,还可以自定义MessageQueueSelector,作为参数传进去:
SendResult sendResult = producer.send(msg, new MessageQueueSelector() {
@Override
public MessageQueue select(List<MessageQueue> mqs, Message msg, Object arg) {
Integer id = (Integer) arg;
int index = id % mqs.size();
return mqs.get(index);
}
}, orderId);源码在example/ordermessage/Producer.java顺序消息
一道很经典的面试题,如何保证消息的有序性?思路是,需要保证顺序的消息要发送到同一个message queue中。其次,一个message queue只能被一个消费者消费,这点是由消息队列的分配机制来保证的。最后,一个消费者内部对一个mq的消费要保证是有序的。我们要做到生产者 - message queue - 消费者之间是一对一对一的关系。
具体操作过程如下:
- 生产者发送消息的时候,到达Broker应该是有序的。所以对于生产者,不能使用多线程异步发送,而是顺序发送。
- 写入Broker的时候,应该是顺序写入的。也就是相同主题的消息应该集中写入,选择同一个Message Queue,而不是分散写入。
要达到这个效果很简单,只需要我们在发送的时候传入相同的hashKey,就会选择同一个队列。

3. 消费者消费的时候只能有一个线程,否则由于消费的速率不同,有可能出现记录到数据库的时候无序。在Spring Boot中,consumeMode设置为ORDERLY,在Java API中,传入MessageListenerOrderly的实现类即可。
consumer.registerMessageListener(new MessageListenerOrderly() {当然顺序消费会带来一些问题:
- 遇到消息失败的消息,无法跳过,当前队列消费暂停
- 降低了消息处理的性能
事务消息
分布式事务有很多种解决方案,其中一种就是使用RocketMQ的事务消息来达到最终一致性。下面我们来看下RocketMQ是怎么实现的。下面是RocketMQ官网的一张流程图,我们对照着图来分析讲解一下。
rocketmq.apache.org/rocketmq/th…
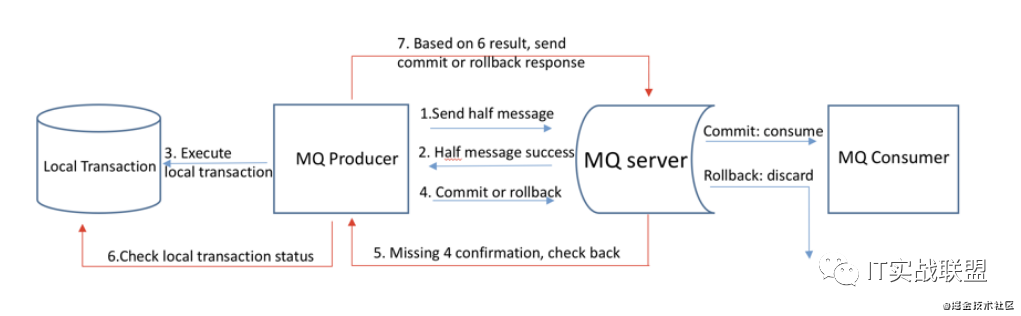
- 生产者向RocketMQ服务端发送半消息,什么叫半消息呢,就是暂不能投递消费者的消息,发送方已经将消息成功发送到了MQ服务端,此时消息被标记为暂不能投递状态,需要等待生产者对该消息的二次确认。
- MQ服务端给生产者发送ack,告诉生产者半消息已经成功收到了。
- 发送方开始执行本地数据库事务的逻辑。
- 执行完成以后将结果告诉MQ服务端,本地事务执行成功就告诉commint,MQ Server收到commit后则将半消息状态置为可投递,consumer最终将收到该消息;本地事务执行失败则发送rollback,MQ Server收到rollback以后则删除半消息,订阅费将不会收到该条消息。
- 未收到第4步的确认信息时,回查事务状态。消息回查: 因为网络闪断、生产者重启等原因,RocketMQ 的发送方会提供一个反查事务状态接口,如果一段时间内半消息没有收到任何操作请求,那么 Broker 会通过反查接口得知发送方事务是否执行成功。
- 发送方收到消息回查后,需要检查对应消息的本地事务执行的最终结果。
- 发送方根据检查本地事务的最终状态再次提交二次确认,发送commit或者rollback。
上述就是整个事务消息的执行流程,下面我们来看下如何在代码中操作。RocketMQ中提供了一个TransactionListener接口,我们需要实现它,然后在executeLocalTransaction方法中实现执行本地事务逻辑。
@Override
public LocalTransactionState executeLocalTransaction(Message msg, Object arg) {
//local transaction process,return rollback,commit or unknow
log.info("executeLocalTransaction:"+JSON.toJSONString(msg));
return LocalTransactionState.UNKNOW;
}这个方法必须返回一个状态,rollback,commit或者unknow,返回unknow之后,因为不确定到底事务有没有成功,Broker会主动发起对事务执行结果的查询,所以还要再实现一个checkLocalTransaction回查方法。
@Override
public LocalTransactionState checkLocalTransaction(MessageExt msg)
log.info("checkLocalTransaction:"+JSON.toJSONString(msg));
return LocalTransactionState.COMMIT_MESSAGE;
}默认回查总次数是15次,第一次回查的间隔是6s,后续每次间隔60s。最后在生产者发送的时候指定下事务监听器即可。
源码在
example/transaction/TransactionProducer.java
延迟消息
很多时候,我们村会在这样的业务场景:在一段时间之后,完成一个工作任务的需求,例如:滴滴打车订单完成之后,如果用户一直不评价,48小时会将自动评价为5星;外卖下单30分钟不支付自动取消等等。这种问题的解决方案有很多种,其中一种就是用RocketMQ的延迟队列来实现,但是开源版本功能被阉割了,只能支持特定等级的消息,商业版可以任意指定时间。
msg.setDelayTimeLevel(2); // 5秒钟比如leve=2代表5秒,一共支持18个等级,延迟的级别配置在代码MessageStoreConfig中:
private String messageDelayLevel = "1s 5s 10s 30s 1m 2m 3m 4m 5m 6m 7m 8m 9m 10m 20m 30m 1h 2h";Spring Boot中这样使用
rocketMQTemplate.syncSend(topic,message,1000,2);// 5秒钟源码在example/delay/DelayProducer.javaBroker
物理存储
我们进入到RocketMQ存储的文件夹看一下,这个目录是我们在安装的时候指定的。

下面依次介绍下这几个文件夹的作用:
- checkpoint:文件检查点,存储commitlog、consumequeue、indexfile最后一次刷盘时间或时间戳。
- commitlog:消息存储目录,一个文件集合,每个默认文件1G大小,当第一个文件写满了,第二个文件会以初始量命名。比如起始偏移量是1073741824,第二个文件名为00000000001073741824,以此类推。
- config:运行时的配置信息,包含主题消息过滤信息、集群消费模式消息消费进度、延迟消息队列拉取进度、消息消费组配置信息、topic配置属性等。
- consumequeue:消息消费队列存储目录,我们可以看到在consumequeue文件夹下是按topic的名字建文件夹,在每一个topic下面又是按message queue的编号建文件夹,在每个message queue文件夹下就是存放消息在commit log的偏移量以及大小和Tag属性。

5. index:消息索引文件存储目录,在前面使用java api发送消息的时候,我们看到会传入一个keys的参数,它是用来检索消息的。所以如果出现keys,服务端就会创建索引文件,以空格分割的每个关键字都会产生一个索引。单个IndexFile可以保存2000W个索引,文件固定大小约为400M。索引使用的是哈希索引,所以key尽量设置为唯一不重复。
存储理念
我们来看下RocketMQ官网的说明,
rocketmq.apache.org/rocketmq/ho… ,我们来导读一下,首先是说kafka为什么不能支持更多的分区,然后说在RocketMQ中我们是如何支持更多分区的。
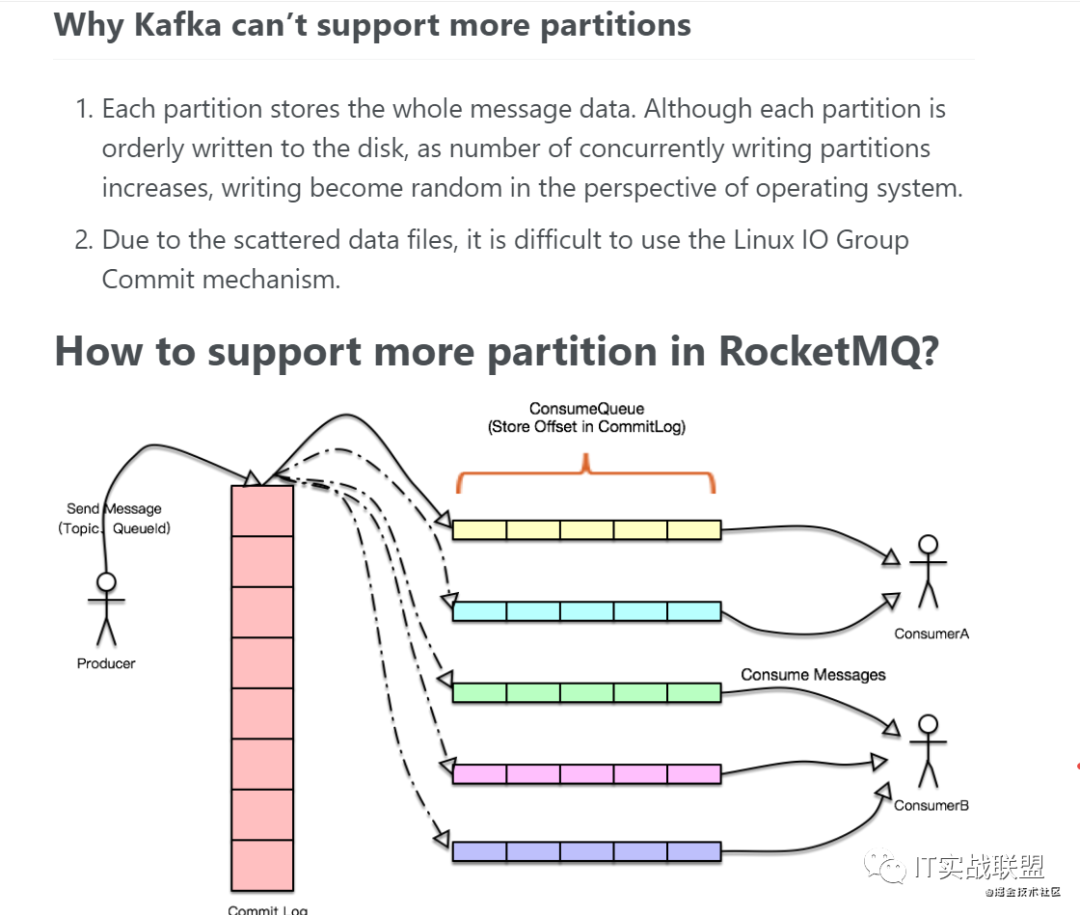
- 每个分区存储整个消息数据。虽然每个分区被有序地写入磁盘,但随着并发写入分区数量的增加,从操作系统的角度来看,写入变得随机。
- 由于数据文件分散,难以使用Linux IO Group Commit机制。
所以RocketMQ干脆另辟蹊径,设计了一种新的文件文件存储方式,就是所有topic的所有消息全部写在同一个文件中,这样就能够保证绝对的顺序写。当然消费的时候就复杂了,要到一个巨大的commitlog中去查找消息,我们不可能遍历所有消息吧,这样效率太慢了。
那怎么办呢?这个就是上面提到的consume queue,它把consume group消费的topic的最后消费到的offset存储在里面。当我们消费的时候,先从consume queue读取持久化消息的起始物理位置偏移量offset、大小size和消息tag的hashcode值,随后再从commitlog中进行读取待拉取消费消息的真正实体内容部分。
consume queue可以理解为消息的索引,它里面没有消息,当然这样的存储理念也不是十全十美,对于commitlog来说,写的时候虽然是顺序写,但是读的时候却变成了完全的随机读;读一条消息先会读consume queue,再读commit log,这样增加了开销。
文件清理策略
跟kalka一样,commit log的内容在消费之后是不会删除,这样做有两个好处,一个是可以被多个consumer group重复消费,只要修改consumer group,就可以从头开始消费,每个consumer group维护自己的offset;另一个是支持消息回溯,随时可以搜索。
但是如果不清理文件的话,文件数量不断地增加,最终会导致磁盘可用空间越来越少,所以RocketMQ会将commitLog、consume queue这些过期文件进行删除,默认是超过72个小时的文件。这里会启动两个线程去跑。
private void cleanFilesPeriodically() {
this.cleanCommitLogService.run();
this.cleanConsumeQueueService.run();
}过期文件选出来以后,什么时候去清理呢,有两种情况。一种是通过定时任务,每天凌晨四点去删除这些文件。第二种是磁盘使用空间超过75% 了,这时候已经火烧眉毛了,我还等到你四点干嘛,立即马上就清理了。
如果情况更严重,如果磁盘空间使用率超过85%,会开始批量清理文件,不管有没有过期,直到空间充足;如果磁盘使用率超过90%,会拒绝消息写入。
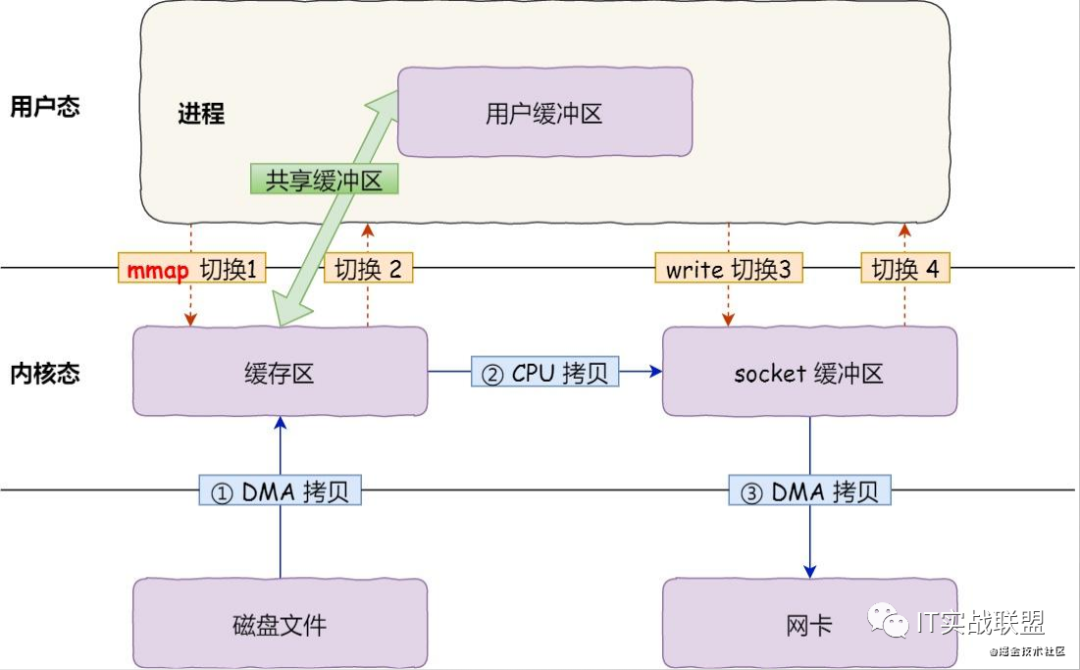
零拷贝
大家都知道RocketMQ的消息是存储在磁盘上的,但是怎么还能做到这么低的延迟和这么高的吞吐量,其中的一个奥秘就是使用到了零拷贝技术。
首先和大家介绍一下page Cache的概念,这个是操作系统层面的,CPU如果要读取或者操作磁盘上的数据,必须要把磁盘的数据加载到内存中,这个加载的大小有一个固定的单位,叫做Page。x86的linux中一个标准的页大小是4kb。如果要提升磁盘的访问速度,或者说减少磁盘的IO,可以把访问过的Page在内存中缓存起来,这个内存的区域就叫做Page Cache。
下次处理IO请求的时候,先到Page Cache中查找,找到了就直接操作,没找到再到磁盘中去找。当然Page Cache本身也会对数据进行预读,对于每个文件的第一个读请求操作,系统也会将所请求的页的相邻后几个页一起读出来。但是这里还有个问题,我们知道虚拟内存分为内核空间和用户空间,Page Cache属于内核空间,用户空间访问不了,还需要从内核空间拷贝到用户空间缓冲区,这个copy的过程就降低了数据访问的速度。
为了解决这个问题,就产生了零拷贝技术,干脆把Page Cache的数据在用户空间中做一个地址映射,这样用户进行就可以通过指针操作直接读写Page Cache,不再需要系统调用(例如read())和内存拷贝。RocketMQ中具体的实现是使用mmap(memory map,内存映射),而kafka用的是sendfile。
消费者
消费端的负载均衡与rebalance
和kafka一样,消费端也会针对Message Queue做负载均衡,使得每个消费者能够合理的消费多个分区的消息。消费者挂了,消费者增加,这时候就会用到我们的rebalance。
在RebalanceImpl.class的277行有rebalance的策略
AllocateMessageQueueStrategy strategy = this.allocateMessageQueueStrategy;
List<MessageQueue> allocateResult = null;
try {
allocateResult = strategy.allocate(this.consumerGroup,
this.mQClientFactory.getClientId(),
mqAll,
cidAll);
} catch (Throwable e) {
log.error("AllocateMessageQueueStrategy.allocate Exception. allocateMessageQueueStrategyName={}", strategy.getName(),e);
return;
}
AllocateMessageQueueStrategy有6种实现的策略,也可以自定义实现,在消费者端指定即可。
consumer.setAllocateMessageQueueStrategy();
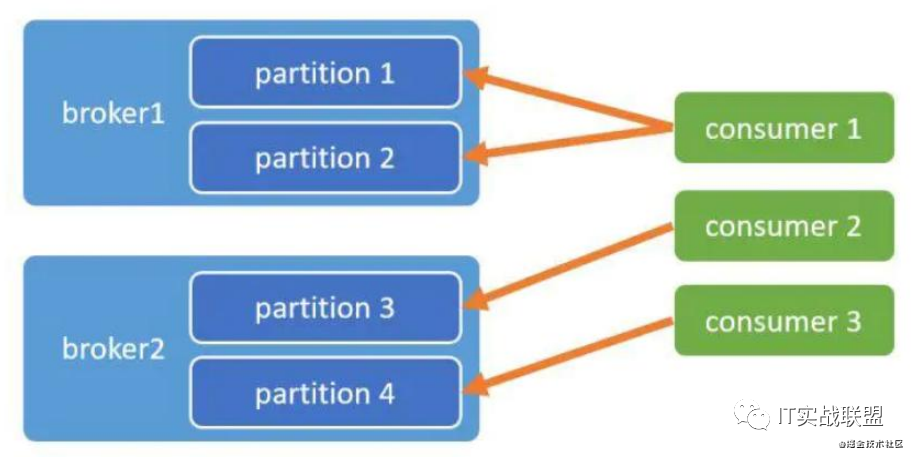
- AllocateMessageQueueAveragely:平均分配算法(默认)
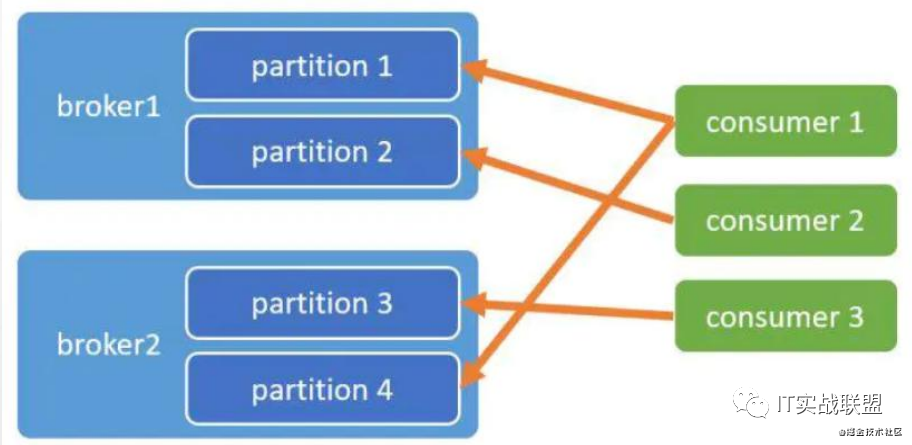
- AllocateMessageQueueAveragelyByCircle:环状分配消息队列
- AllocateMessageQueueByConfig:按照配置来分配队列,根据用户指定的配置来进行负载
- AllocateMessageQueueByMachineRoom:按照指定机房来配置队列
- AllocateMachineRoomNearby:按照就近机房来配置队列
- AllocateMessageQueueConsistentHash:一致性hash,根据消费者的cid进行
队列的数量尽量要大于消费者的数量。
重试与死信队列
在消费者端如果出现异常,比如数据库不可用、网络出现问题、中途断电等等,这时候返回给Broker的是RECONSUME_LATER,表示稍后重试。这个时候消息会发回到Broker,进入到RocketMQ的重试队列中。服务端会为consumer group创建一个名字为%RETRY%开头的重试队列。

重试队列过一段时间后再次投递到这个ConsumerGroup,如果还是异常,会再次进入到重试队列。重试的时间间隔会不断衰减,从10秒开始直到2个小时:10s 30s 1m 2m 3m 4m 5m 6m 7m 8m 9m 10m 20m 30m 1h 2h,最多重试16次。
而如果一直这样重复消费都持续失败到一定次数(默认16次),就会投递到DLQ死信队列。Broker会创建一个死信队列,死信队列的名字是%DLQ%+ConsumerGroupName,应用可以监控死信队列来做人工干预。一般情况下我们在实际生产中是不需要重试16次,这样既浪费时间又浪费性能,理论上当尝试重复次数达到我们想要的结果时如果还是消费失败,那么我们需要将对应的消息进行记录,并且结束重复尝试。
源码在
jackxu/SimpleConsumer.java
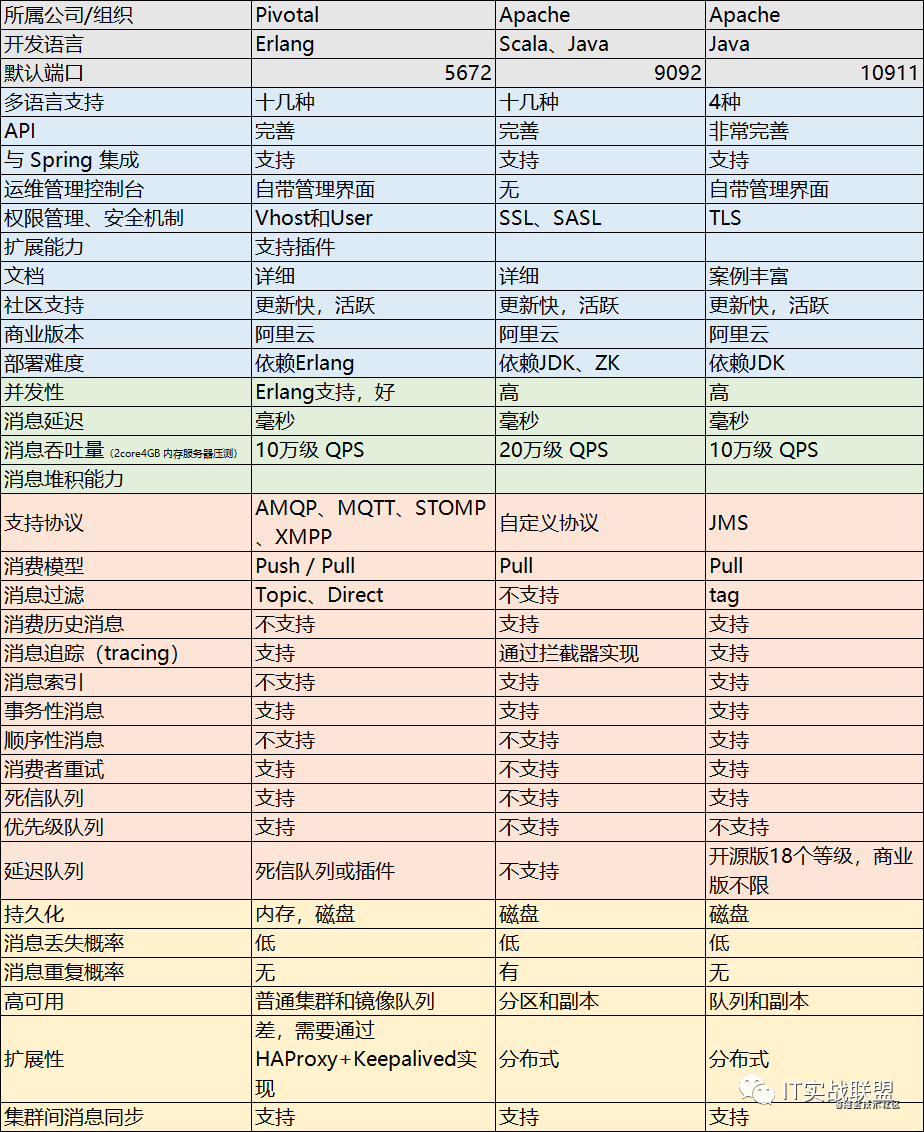
MQ选型分析
下面列出市面上常见的三种MQ的分析对比,供大家在项目中实际使用的时候参考对比:
好,RocketMQ系列到这里就结束了,感谢大家的观看~
注意:本文归作者所有,未经作者允许,不得转载

