如今的推荐系统,对于实时性的要求越来越高,实时推荐的流程大致可以概括为:推荐系统对于用户的请求产生推荐,用户对推荐结果作出反馈 (购买/点击/离开等等),推荐系统再根据用户反馈作出新的推荐。这个过程中有两个值得关注的地方:
- 这可被视为是一个推荐系统和用户不断交互、互相影响的过程。
- 推荐系统需要对用户反馈作出快速及时的响应。
这两点本篇分别通过强化学习和 Flink 来实现,而在此之前先了解一些背景概念。
强化学习
强化学习领域的知名教材 《Reinforcement Learning: An Introduction》开篇就写道:
当我们思考学习的本质的时候,脑中首先联想到的可能就是在与环境不断交互中学习。当一个婴儿在玩耍、挥舞手臂或是旁顾四周时,并没有任何老师教它,但它确实能直接感知到周围环境的变化。
强化学习的主要过程是构建一个智能体,使之在与环境交互的过程中不断学习,以期获得最大的期望奖励。它是一种非常通用的学习范式,可以用于对各种各样问题的建模,比如游戏、机器人、自动驾驶、人机交互、推荐、健康护理等等。其与监督学习的主要不同点在于:强化学习根据延迟的反馈通过不断试错 (trial-and-error) 进行学习,而监督学习则是每一步都有明确的反馈信息进行学习。
下图反映了一个推荐智能体 (recommender agent) 与环境进行互动的过程。这里将用户 (user) 视为环境,用户的行为数据作为状态 (state) 输入到智能体中,智能体据此作出相应的动作 (action) ,即推荐相应的物品给用户,用户对此推荐的反应如点击/不点击、购买/不购买等可视为新一轮的奖励。从这里可以看出,推荐可被认为是一个动态序列决策过程,推荐物品对用户产生影响,进而用户的反馈反过来影响推荐系统的决策本身,这样的过程会不断延续下去形成一个序列。
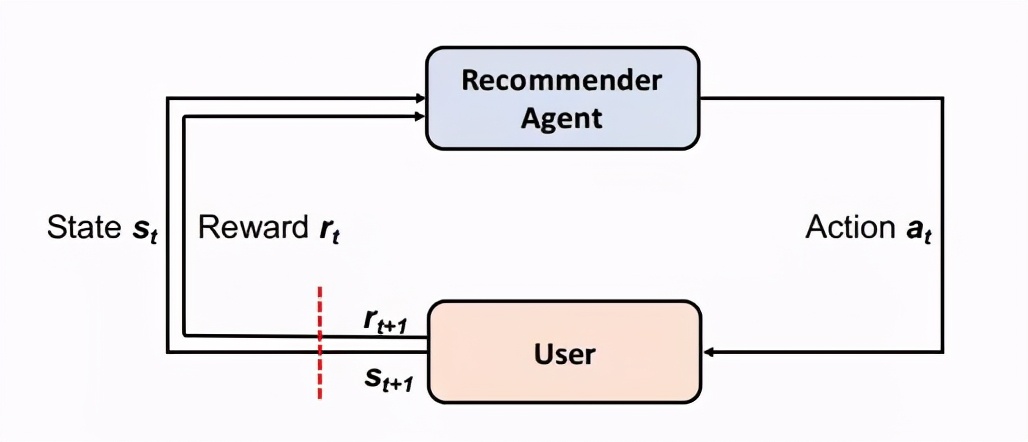
“决策” 这个词实际上很能代表强化学习本身的特点。设想当一个人在做决策的时候,很多时候需要对瞬息万变的局势进行评估并快速作出相应的选择,而另一方面,作出的决定需要考虑长期的目标而非仅仅是短期收益。而这两点恰恰是几乎所有用强化学习做推荐系统的论文中都会提到的关于传统推荐方法的问题,即将推荐视为静态预测的过程以及只注重短期收益等等。当然论文里这么说主要是为了凸显自己的成果,但实际的情况应该远不是这么简单。
强化学习的最终目标是学习出一个策略 (|) 来最大化期望奖励。策略 (policy) 指的是智能体如何根据环境状态 来决定下一步的动作 ,对应到推荐的场景中就是根据用户过往行为记录来决定下一步推荐的物品。
对于如何通过训练得到最优策略,目前主流有两类方法: on-policy 和 off-policy 。不同于监督学习的需要预先人工收集数据并标注,强化学习的数据来源于不断地与环境进行互动,继而用收集来的数据更新模型。所以在这个过程中有两个部分与策略相关,一是与环境互动时需要使用策略,二是训练时更新策略。On-policy 指的是环境互动的策略和训练时更新的策略是同一个策略,相应地 off-policy 则是互动和更新时使用的是不同的策略。如下左图为 on-policy,下中图为 off-policy (下右图为 offline 方法,后文再述 )。
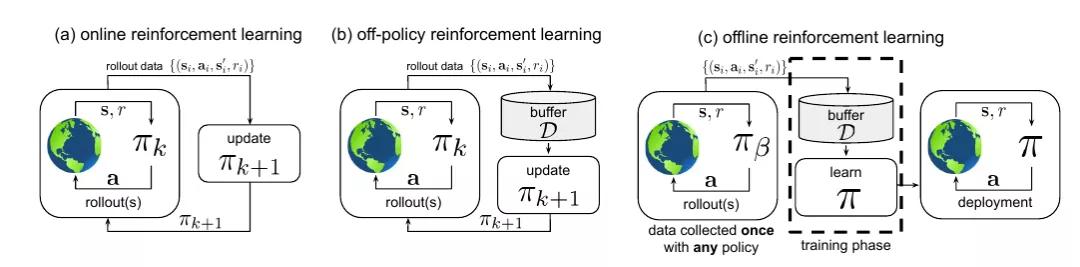
On-policy 的思想比较直观,相当于一个智能体在环境中边试错边学习,但是其主要问题是样本利用率低,进而训练效率低。使用了一个策略与环境进行交互取得数据进而更新模型后,就产生了一个新的策略,那么旧策略交互得来的数据可能就不服从新策略的条件分布了,所以这些数据不能再使用会被丢弃。
Off-policy 则缓解了这个问题,主要通过将之前策略收集来的数据通过一个经验回放池 (experience replay buffer) 储存起来,然后从中采样数据进行训练。那么 off-policy 类方法为什么能使用旧策略产生的数据进行训练?既然数据分布不同导致新旧数据不能放一起训练,那就调整数据分布使之接近就可以了,所以 Off-policy 类的算法普遍采用了重要性采样的思想对不同数据施加不同的权重,后文介绍 YouTube 的推荐系统时会提到,到那时再说。
那么本篇的强化学习方法适用于哪一种呢?这其实不大好说。我没有能互动的环境,只有静态数据集,所以 off-Policy 看上去更适合一些,但即使是 off-policy 的方法通常也需要与环境进行交互不断产生新数据用于训练。因此本篇的方法属于 batch reinforcement learning,或称 offline reinforcement learning,不过我倾向于使用 batch 这个词,因为 offline 和 off-policy 很容易混淆。上右图显示的就是 batch (offline) reinforcement learning,其特点是一次性收集完一批数据后就只用这批数据进行训练,在正式部署之前不再与环境作任何交互。
我们知道深度学习近年来在图像和 NLP 领域取得了很大的进展,一大原因是算力和数据的爆炸式增长。然而对于主流的深度强化学习算法来说,需要不断与环境进行交互来获取数据,这通常意味着需要边训练边收集数据。许多领域是无法像传统强化学习那样有条件频繁与环境进行交互的,存在成本太高或者安全性太低的原因,甚至会引发伦理问题,典型的例子如无人驾驶和医疗。
所以这时候人们自然会去想,训练强化学习时也收集一堆固定的数据,然后不断重复利用,不再收集新的,仿照深度学习那样在固定数据集上大力出奇迹,这样是否可行呢?因此 batch reinforcement learning 近年来受到越来越多学术界和工业界的关注,被广泛认为是实现强化学习大规模应用到实际的一个有效途径。而推荐系统就很适合这种模式,因为直接线上探索交互代价太大,影响用户体验,但收集用户行为日志却相对容易且数据量大。
Flink
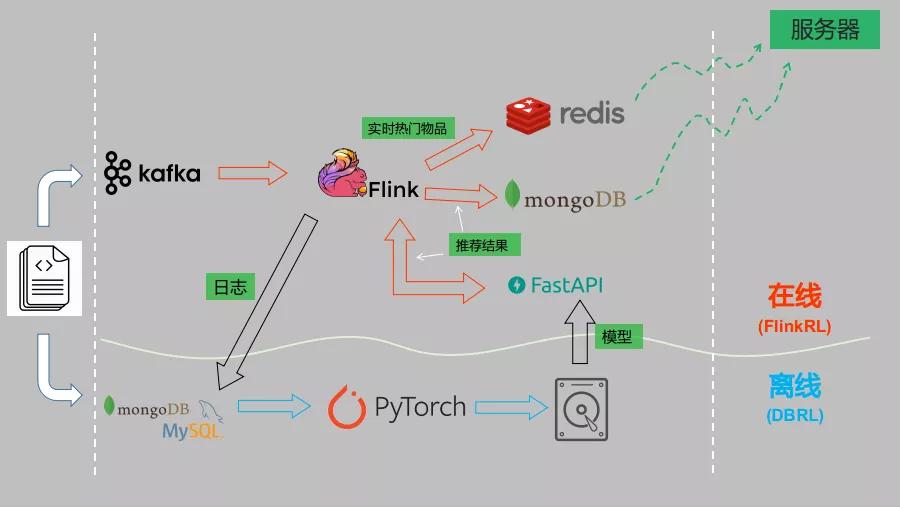
另一方面,推荐系统作为一个系统,光有算法肯定是不行的。上文提到 batch reinforcement learning 无需与环境互动,仅靠数据集就能训练,那么在训练完模型真正上线以后就需要与环境交互了,而这个过程中需要有中间载体,用于快速获得信息、清洗原始数据并转化成模型可输入的格式。在本篇中这个前道工序我们主要使用 Flink。Flink 官网上的自我介绍是 ”数据流上的有状态计算 (Stateful Computations over Data Streams)“:
换言之随着数据的不断流入,其可以保存和访问之前的数据和中间结果,当到达特定的条件后一并计算。对于我们的强化学习模型来说,需要累计一定的用户行为才能作为模型输入作推荐,所以需要在 Flink 中实时保存之前的行为数据,这就要用到 Flink 强大的状态管理功能。
另外,离线训练使用的深度学习框架是 PyTorch,这个不像 Tensorflow 那样部署方便,所以这里采用近年来流行的 FastAPI 做成 api 服务,在 Flink 中获取满足条件的特征后直接调用服务进行推理,产生推荐后存到数据库中,服务器在下次用户请求时可直接从数据库中调用推荐结果。
整体架构见下图, 完整代码和流程见:
FlinkRL:
https://github.com/massquantity/flink-reinforcement-learning
DBRL:https://github.com/massquantity/DBRL
下面介绍使用的三种算法,限于篇幅,这里仅仅大致介绍原理,欲了解细节可参阅原论文。下面是主要符号表:

YouTube Top-K (REINFORCE)
这个方法主要参考 YouTube 2018 年发表的论文 Top-K Off-Policy Correction for a REINFORCE Recommender System 。论文作者在这个视频中宣称这个方法取得了近两年来的最大增长,说实话我是有点怀疑的。在论文最后的实验部分提到,这个强化学习模型只是作为众多召回模型之一,然后所有的召回物品再经过一个独立的排序模块后推荐给用户,文中也没说这个排序模块用的是什么模型,所以这里面的空间就比较大了。
论文中使用了 policy gradient 领域最古老的 REINFORCE 算法,并就其具体业务情形做了一些改动,这里我们先看 REINFORCE 的基本框架。
假定执行的是随机策略,智能体在环境中互动产生的一个轨迹为 =(0,0,1,1,1,⋯,−1,−1,,) 。在深度强化学习中一般使用神经网络来参数化策略 ,一般会在环境中采样多个轨迹,那么该策略的期望总回报为:
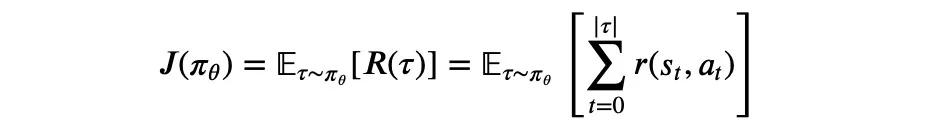
其中 是神经网络的参数,() 为轨迹 的总回报,因为轨迹带有随机性,所以我们希望最大化期望回报来获得最优的策略 ∗:
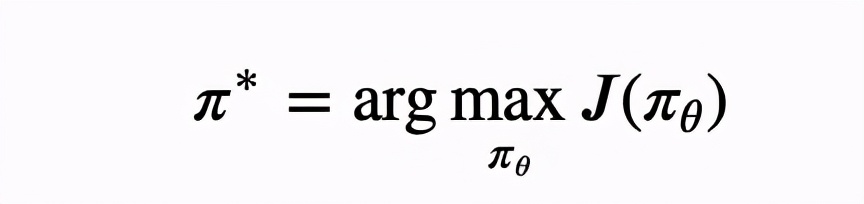
REINFORCE 的思想,或者说整个 policy gradient 的思想,和监督学习中的很多算法殊途同归,即通过梯度上升 (下降) 法求参数 ,把 (1.1) 式当成目标函数,那么一旦有了梯度,就可以用这个熟悉的式子进行优化了:
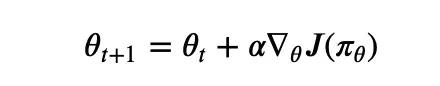
直接求 () 的梯度异常困难,但是通过 policy gradient 定理,我们可以得到一个近似解:

其中 =∑||′=′−(′,′) ,意为 时刻采取的动作获得的最终回报只与之后获得的奖励有关,而与之前的奖励无关。关于 policy gradient 定理的证明见附录 A 。
原始的 REINFORCE 算法是 on-policy 的,亦即线上交互和实际优化的是同一个策略,然而论文中说他们线上交互的是不同的策略,甚至是多种不同策略的混合体。这样就导致了数据分布不一致,如果直接使用 REINFORCE 会产生巨大的 bias 。论文中通过重要性采样把算法改造成 off-policy 的:
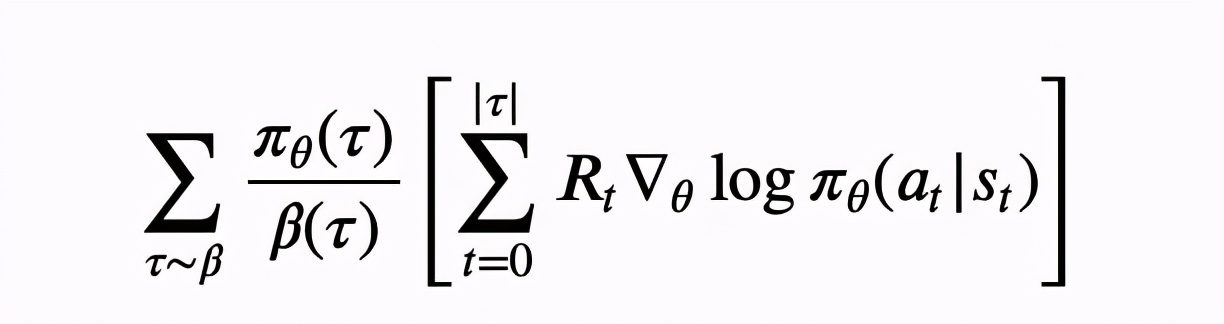
为实际的交互策略,这个式子的推导也可以直接通过 policy gradient 得出,具体见附录 B 。接下来经过一系列的权衡,作者认为下面这个式子比较合理地平衡了偏差与方差:
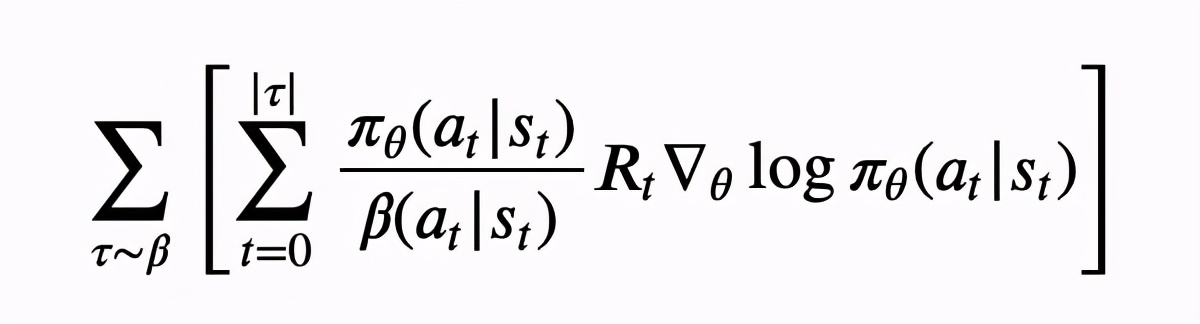
主要的不同就是采样是沿着 的轨迹进行,并在每一步 中加了重要性权重 (|)(|) ,而这个权重相对很容易计算。
论文中考虑的另外一个问题是,之前都是考虑的动作只有一个,即只推荐一个物品,但现实中往往是一次性推荐 个物品给用户,如果 个物品同时考虑就会组合爆炸。论文中假设同时展示 个不重复物品的总奖励等于每个物品的奖励之和,这样就可以转化为单个物品的优化,同时作者说这个假设成立的前提是用户对推荐列表中每个物品的观察是独立的。
YouTube 在 2019 年发表过另外一篇用强化学习做推荐的论文 (Reinforcement Learning for Slate-based Recommender Systems: A Tractable Decomposition and Practical Methodology) ,和 2018 年中的方法相比,主要的不同是使用了 on-policy 的 SARSA 算法,而且是用在了排序而不是召回阶段。
这篇论文中同样对推荐的 个物品作了某种假设:假设一个推荐列表中用户只会消费其中一个物品,如果用户消费完后又返回到这个推荐列表消费第二个物品,则这个行为会被视为另外的事件,在日志中分开记录。实际上这两个假设的本质就在于用户面对 个物品的列表只会关注其中一个而不管其他,然而实际很多时候用户会对多个感兴趣,但是消费完一个后就把剩余几个忘了。极端情况是推荐了 10 个全部都感兴趣,消费了一个后有些事离开了或者陷入不断点击循环消费,这样原来的另外 9 个感兴趣的就都被当成负样本处理了。
到这里我们可以看到,两篇论文都必须作出一些假设的根本原因在于使用的算法输出的都是离散型动作,即单个物品,然而推荐的场景不像一般的强化学习应用只需要输出一个动作就行了。所以不得不作出一些看上去很别扭的假设,而后面介绍的两个算法输出的都是连续型动作,则会有另外的解决办法。
接下来依然沿着上面的假设走, 个就转化为单个物品了,结合重要性权重后, (1.3) 式可转化为:
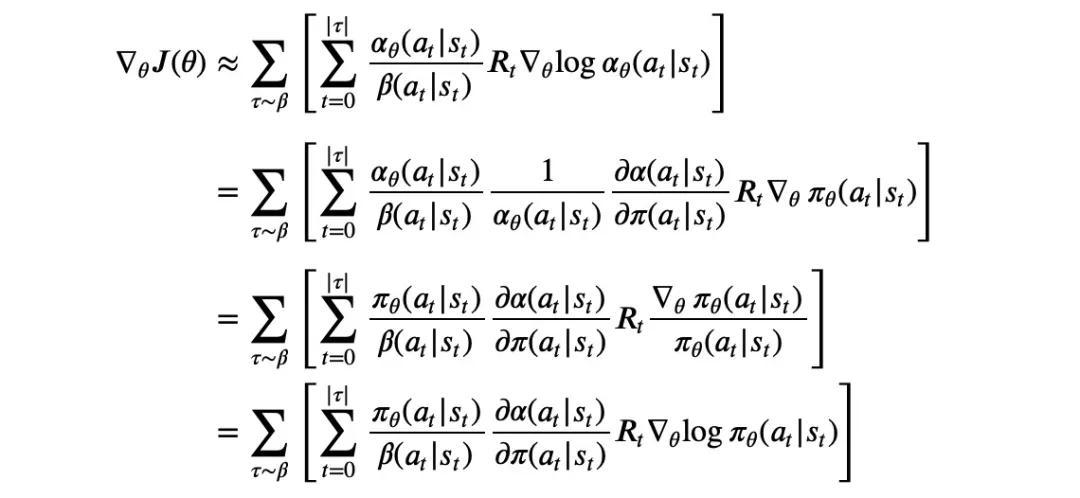
式中主要是用 (|) 代替了原来的 (|),因为 个物品是各自独立从策略 中采样的,则 (|)=1−(1−(|)) 表示 时刻物品 出现在最终的 个物品的列表中的概率,因为 (1−(|)) 表示 次都没有被采样到的概率。
可以看到 (1.3) 式和 (1.4) 式的唯一差别是多了一个乘子 : ∂(|)∂(|)=(1−(|))−1 。因此我们只要采样一个轨迹,在每一步 由神经网络计算出 (|),(|) (这两个实际就是 softmax 输出的概率),再整合计算折扣回报 =∑||′=′−(′,′) 后,就能相应地实现算法了,最终的代码见:
https://github.com/massquantity/DBRL/blob/master/dbrl/models/youtube_topk.py
DDPG
就推荐的场景来说,离散型动作是比较自然的想法,每个动作就对应每个物品。然而现实中物品数量可能至少有百万级,意味着动作空间很大,用 softmax 计算复杂度很高。上面 YouTube 的论文中使用 sampled softmax 来缓解这个问题,而这里我们可以换个思路,让策略输出一个连续的向量 ∈ℝ ,再将 与每个物品的 embedding 点乘再排序来获得推荐列表,在线上则可以使用高效的最近邻搜索来获取相应物品。对于连续型动作而言, DDPG 是比较通用的选择,在我看过的推荐相关的论文里使用 DDPG 是最多的,比如京东的两篇[1][2],阿里的一篇[1],华为的一篇[1] 。
DDPG 全称 Deep Deterministic Policy Gradient,是一种适用于连续型动作的 off-policy 算法。不同于上文的 REINFORCE,其使用的是确定性策略,顾名思义对于相同的状态 会产生唯一的动作 ,所以这里我们用 () 来表示。而因为是确定性策略,不存在动作 的概率分布 ,也就不需要重要性采样了。
DDPG 采用 Actor-Critic 框架,Actor 为具体的策略,其输入为状态 ,输出动作 。Critic 用于评估策略的好坏,其输入为 (+) 拼接而成的向量,输出为一个标量。Actor 和 Critic 都可以用神经网络来参数化,假设 Actor 网络为 (|) ,Critic 网络为 (,|) ,则 Actor 和 Critic 的目标函数和梯度分别为:
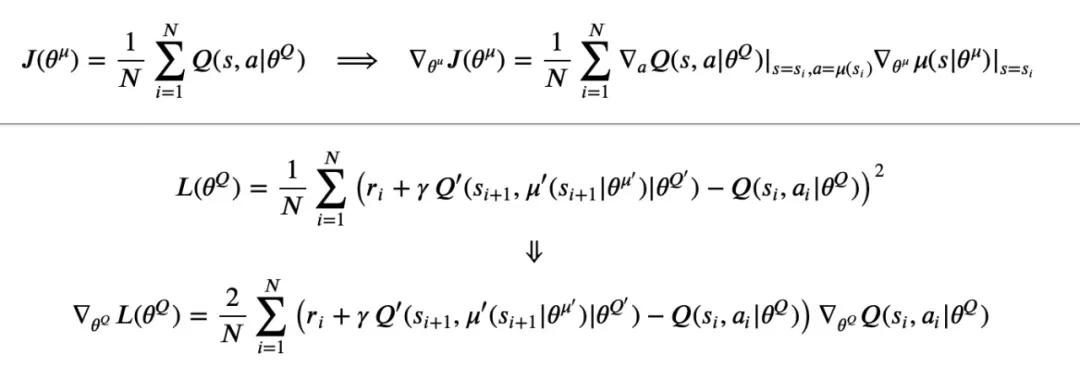
那么算法的核心就是通过梯度上升 (下降) 优化这两个目标函数来求得最终的参数,进而得到最优策略。DDPG 其他的一些实现细节如 target network、soft update 等等这里不再赘述,由于我们使用的是固定的数据集,因而只要将数据转化成 DDPG 算法可以输入的格式,再像监督学习那样分 batch 训练就行了,不用再与环境作交互,最终的代码见:
https://github.com/massquantity/DBRL/blob/master/dbrl/models/ddpg.py
BCQ
BCQ 算法全称 Batch-Constrained Deep Q-Learning ,出自论文 Off-Policy Deep Reinforcement Learning without Exploration 。BCQ 可以看作是对 DDPG 在 batch (offline) 场景的改造版本,如前文所述,batch (offline) reinforcement learning 指的是在固定的数据集上进行学习,不再与环境进行交互。论文作者指出在这种条件下当前流行的的 off-policy 算法如 DQN、DDPG 等可能效果不会很好,原因主要出在会产生 extrapolation error。
Extrapolation error 主要源于数据集中状态 和动作 组合的分布和当前策略中状态-动作组合分布的不一致,即采样的策略和当前策略差别很大,从而使得 Critic 对于值函数的估计不准,进而使得学习失效。以上文中 DDPG 的 Critic 网络的目标函数 (改变了一些符号) 为例:
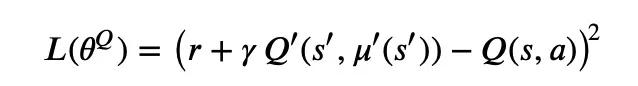
因为 ′ 本身是一个神经网络,如果 ′(′) 最终输出了一个不在数据集内的动作,那么很可能导致 ′(′,′(′)) 对于该状态-动作组合的估值不准,那么就学不到好的策略了。如下图(来源)就显示了如果动作 在行为策略 的分布之外,会有可能对 值产生过高的估计,导致后续错误不断累计。
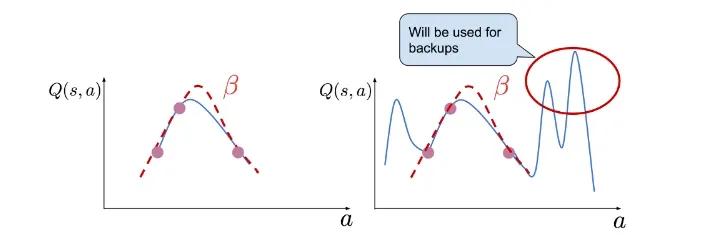
我在实际训练 DDPG 的时候确实碰到过类似情况,Critic 的损失有时候会到达 1e8 这样夸张的级别,不论再怎么调小学习率都没用。后来发现可能的原因,最开始是将用户之前交互过的多个物品向量平均起来作为状态 的表达,然而平均过后的向量就可能不会长得和任何单个物品向量很像了,也即远离了原来的数据分布。那么 ′() 输出的动作 自然也和数据集中的动作相去甚远,这样一环传一环致使最终 值爆炸,而后来改为物品向量直接拼接后就没这种情况了。
另外作者也提到,DQN、DDPG 这样常见的 off-policy 算法中并没有考虑 extrapolation error,为什么它们在正统强化学习任务中很有效呢?因为是这些算法本质上采用的是 growing batch learning 的训练方法:在用一批数据离线训练一段时间后,依然会用训练好的策略去环境中收集新数据用于训练,这样采样来的数据实际上和现有策略差别不大,因而 extrapolation error 可以忽略不计。但是在完全 offline 训练的情况下,数据集很可能是使用完全不同的策略收集而来的,因而这种时候 extrapolation error 的影响就比较显著了。
所以问题的核心是如何避免生成一个莫名其妙的状态-动作组合从而导致 extrapolation error?论文中的方法是用一个生成模型 (generative model) 来生成和数据集中相似的状态-动作组合,再用一个扰动模型 (perturbation model) 对生成的动作添加一些噪声来增加多样性。其中生成模型使用的是变分自编码器 (variational auto-encoder, VAE),扰动模型就是一个普通的全连接网络,输入为生成出的动作 ,输出为范围在 [−Φ,Φ] 内的新动作,Φ 为动作的最大值,对于连续型动作我们一般设定一个上限避免输出太大的动作值。
这两个模型合起来可视为 BCQ 算法使用的策略,即 Actor,而 Critic 的部分和 DDPG 差别不大,完整代码见:
https://github.com/massquantity/DBRL/blob/master/dbrl/models/bcq.py
Appendix A: Policy Gradient 定理
由 (1.1) 式可知目标函数为:

Appendix B: 重要性采样
(Importance Sampling)
设实际的交互策略 的轨迹分布为 () ,对 (A.2) 式应用重要性采样:
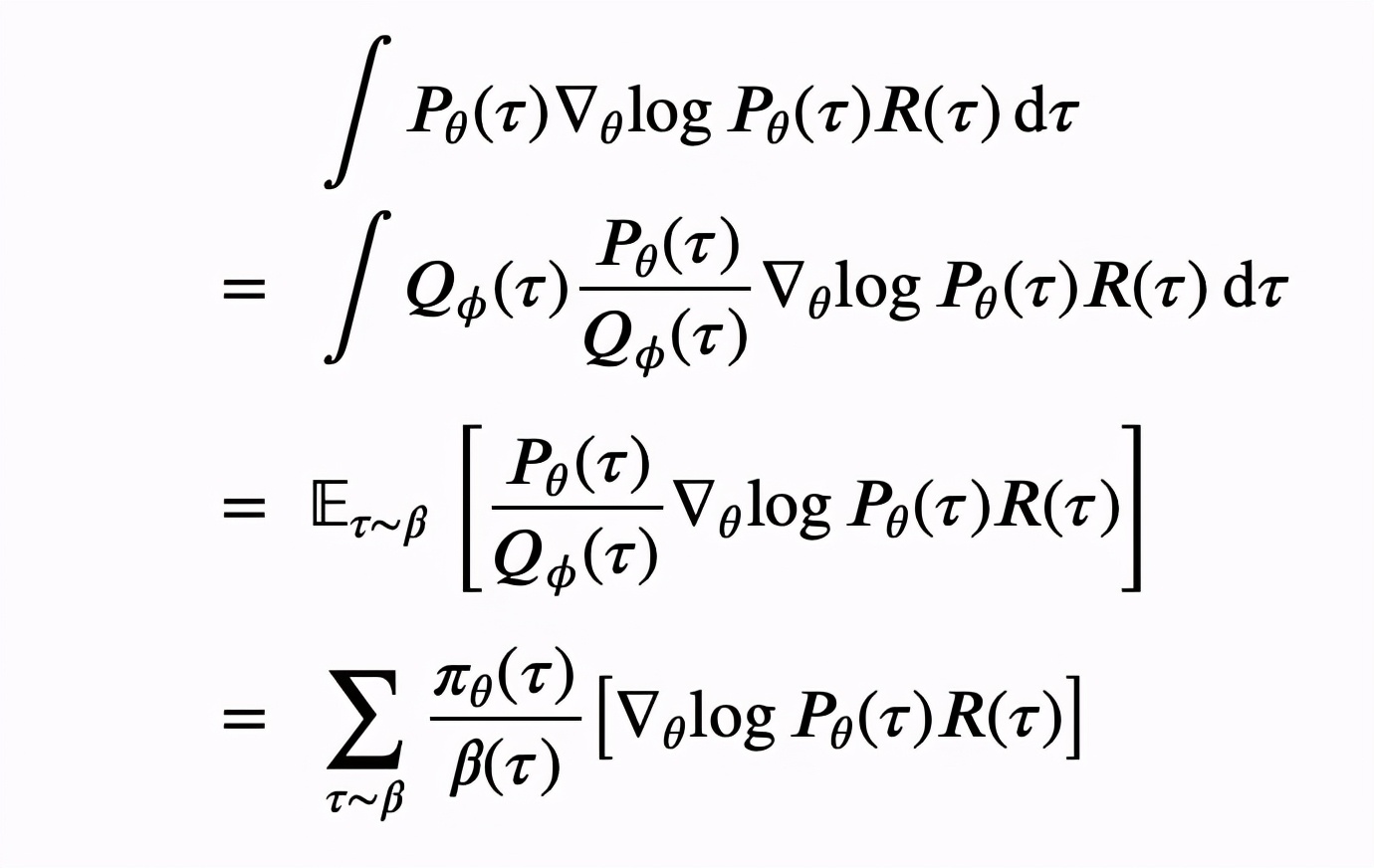
之后就和附录 A 的推导一样了。
References
- Richard S Sutton, Andrew G Barto, et al. Reinforcement learning: An introduction
- Minmin Chen, et al. Top-K Off-Policy Correction for a REINFORCE Recommender System
- Xiangyu Zhao, et al. Deep Reinforcement Learning for List-wise Recommendations
- Scott Fujimoto, et al. Off-Policy Deep Reinforcement Learning without Exploration
- Sergey Levine, Aviral Kumar, et al. Offline Reinforcement Learning: Tutorial, Review,and Perspectives on Open Problems
- Eugene Ie , Vihan Jain, et al. Reinforcement Learning for Slate-based Recommender Systems: A Tractable Decomposition and Practical Methodology
文章转载自博客,作者 massquantity。
原文链接:
https://www.cnblogs.com/massquantity/p/13842139.html
注意:本文归作者所有,未经作者允许,不得转载

