原文作者:IT晓月寒丶
原文链接:https://www.toutiao.com/a6664758389999927812
hadoop单机搭建
这几天准备开始学习hadoop,网上很多教程说的是用虚拟机搭建分布式、伪分布式hadoop集群,整了几天也没弄好。上次偶遇一位高人,指点迷津说你为啥不搭一个单机版的hadoop。遂茅塞顿开,一个小时不到就搞定了。
首先,由于hadoop是用java写的,所以在安装hadoop之前呢,需要先把jdk环境装好。
jdk的安装在此就不赘述了,无非就是先下载,解压,环境变量配置啥的~
hadoop安装
首先你得去官网把下载地址搞到手:http://hadoop.apache.org/

点击Download按钮去下载页面:
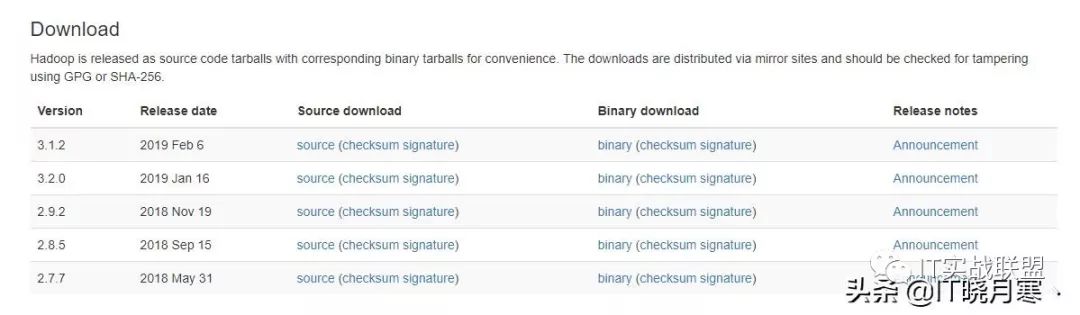
在这个页面,选择你喜欢的版本Binary download,反正我选的是2.9.2。
点击binary标签,进入下载地址页面:

复制这个地址,这是hadoop建议你下载的地址。
如果有防火墙啥的关一关,如果是云服务器的话需要配置安全组,开通两个端口:8088和50070.
下载:
使用wget下载就行了,在你喜欢的地方使用命令:
wget http://mirror.bit.edu.cn/apache/hadoop/common/hadoop-2.9.2/hadoop-2.9.2.tar.gz
解压:
tar -xvf hadoop-*.tar.gz
修改环境变量:
vim /etc/profile
以下是我的环境变量配置文件:
JAVA_HOME=/usr/java/jdk1.8.0_161MAVEN_HOME=/usr/local/apache-maven-3.6.0HADOOP_HOME=/my/hadoop/hadoop-2.9.2HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/nativeHADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib"PATH=$JAVA_HOME/bin:$MAVEN_HOME/bin:$HADOOP_HOME/bin:$PATHCLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jarexport JAVA_HOMEexport PATHexport CLASSPATH
路径需要按照你自己配置的路径去修改。
使环境变量生效:
source /etc/profile
新建一些文件夹供hadoop使用:
mkdir /root/hadoopmkdir /root/hadoop/tmpmkdir /root/hadoop/varmkdir /root/hadoop/dfsmkdir /root/hadoop/dfs/namemkdir /root/hadoop/dfs/data
进入hadoop目录下:
cd /my/hadoop/hadoop-2.9.2/etc/hadoop/
修改core-site.xml
<configuration><property><name>hadoop.tmp.dir</name><value>/root/hadoop/tmp</value><description>Abase for other temporary directories.</description></property><property><name>fs.default.name</name><value>hdfs://your ip:9000</value></property></configuration>
修改 hadoop-env.sh
export JAVA_HOME=${JAVA_HOME}
修改为
export JAVA_HOME=/usr/java/jdk1.8.0_161
修改hdfs-site.xml
<property><name>dfs.name.dir</name><value>/root/hadoop/dfs/name</value><description>Path on the local filesystem where theNameNode stores the namespace and transactions logs persistently.</description></property><property><name>dfs.data.dir</name><value>/root/hadoop/dfs/data</value><description>Comma separated list of paths on the localfilesystem of a DataNode where it should store its blocks.</description></property><property><name>dfs.replication</name><value>2</value></property><property><name>dfs.permissions</name><value>false</value><description>need not permissions</description></property>
修改mapred-site.xml
<property><name>mapred.job.tracker</name><value>test1:9001</value></property><property><name>mapred.local.dir</name><value>/root/hadoop/var</value></property><property><name>mapreduce.framework.name</name><value>yarn</value></property>
如果没有这个文件的话,把mapred-site.xml.template复制一份改个名字。
启动Hadoop
第一次启动需要初始化一下,在hadoop的bin目录下执行命令:
./hadoop namenode -format
启动命令:
./start-dfs.sh
在这之后会需要你多次输入密码,然后输入yes
启动YARN:
./start-yarn.sh
浏览器中输入地址:http://your ip:8088/cluster
至此单机版hadoop安装完成。
---------------END----------------
后续的内容同样精彩
长按关注“IT实战联盟”哦

注意:本文归作者所有,未经作者允许,不得转载

