Redis不是垃圾桶也不是 SUPER MAN,能力和资源都有限,不合理的使用会降低它的健康度,严重时甚至会引起redis抖动、阻塞等进而导致服务不可用,每一个使用redis的开发人员都应当掌握规范的开发和使用方法。

01合理使用集合类
案例
某活动需求,每天10点对昨天参加某活动的用户进行推送提醒。开发人员使用redis存储每天参加活动的用户,通过ZRANGEBYSCORE命令获取目标用户进行提醒,提醒完后使用ZREMRANGEBYSCORE命令从redis中清除这批用户。某一天ZRANGEBYSCORE、ZREMRANGEBYSCORE均出现了慢日志报警,排查发现这一天参加该活动的用户约有5万。
分析
案例中使用了redis的sortedset来储存用户信息,其中value是用户的账号、score是用户参加活动的时间,由于ZRANGEBYSCORE和ZREMRANGEBYSCORE命令的时间复杂度是 O(log(N) + M),其中M是操作的元素个数,N是集合元素总数,本例中当用户数量为5万时出现慢日志。可以通过缩小每次查询的集合数量,可以将一天分成多段,分批次查询,比如把查24小时范围的用户改为查4小时范围的用户,分别查6次处理即可。
Q:如果用户参加活动的时间很集中,在某一个时间段(比如晚18点到22点)查出来的数量还是特别多怎么办?
A:可以把粒度分得更细一些比如1小时或者30分钟,如果确定用户参加活动集中在某个时间点,可以考虑使用ZSCAN遍历操作并删除。另外,对于目标时间范围有确定的首尾元素时,还可以通过ZRANK命令查出元素的位置,通过 ZRANGE 以及ZREMRANGEBYRANK来进行查询和删除操作,这样每次操作可以控制操作数量,有效避免慢日志。
小结
使用 sortedset、set、list、hash等集合类的O(N)操作时要评估当前元素个数的规模以及将来的增长规模,对于短期就可能变为大集合的key,要预估O(N)操作的元素数量,避免全量操作,可以使用HSCAN、SSCAN、ZSCAN进行渐进操作。集合元素数量过大在使用过程中会影响redis的实际性能,元素个数建议尽量不要超过5000,元素数量过大可考虑拆分成多个key进行处理。
02合理设置过期时间
案例1
某投票功能,用于统计今日环比昨日的增长数量,开发人员使用redis存储每天的投票数,key设计为vote_count_{date},其中{date}为当天的日期,由于没有设置过期时间,一年以后产生了360多个key,实际在用的key始终只有2个。
分析
该案例中,每个生成的key在2天以后都不会再使用了,可将key加上过期时间。
案例2
某统计功能,用户会不定期的导入一批数据进 redis,每一批数据需要在30分钟后、1天后、3天后、7天后进行计算统计,统计结果发给用户。开发人员使用redis的同一个sortedset存储这些导入的数据,每天定时任务执行计算任务。由于没有清理,导致大量结束计算任务的废弃数据残留redis。
分析
该案例中,每一批数据都有相应的生命周期,在导入的第7天执行完最后一次计算任务生命周期结束,由于集合里的元素不能单独设置过期时间,可在代码逻辑中对最后一次使用这批数据后进行清理操作。
小结
如果key没有设置超时时间,会导致一直占用内存。对于可以预估使用生命周期的key应当设置合理的过期时间或在最后一次操作时进行清理,避免垃圾数据残留redis。
03合理利用批操作命令
案例
某运营需求,需要给用户生成短链,短链由短链前缀+短码组成,根据短码找到用户对应的手机号,开发人员使用redis hash结构存储短码到手机号的映射。接口每次会导入5万个手机号。
分析
下面是开发人员的三种操作redis方案的伪代码 方案1:直接使用redis的HSET逐个设置for(50000;)HSET(key,短码,手机号) 结果:失败。redis ops飙升,同时接口响应超时 方案2:改用redis的 HMSET一次将所有元素设置到hash中map<短码,手机号> 50000个元素HMSET(key,map) 结果:失败。出现redis慢日志 方案3:依然使用 HMSET,只是每次设置500个,循环100次map<短码,手机号> 500个元素for(100;)HMSET(key,map) 结果:成功对于大量频繁的hset操作可以使用 HMSET替代减少redis操作次数同时提升处理速度,但是要考虑单次请求操作的数量,避免慢日志。
小结
在redis使用过程中,要正视网络往返时间,合理利用批量操作命令,减少通讯时延和redis访问频次。redis为了减少大量小数据CMD操作的网络通讯时间开销 RTT (Round Trip Time),支持多种批操作技术:
MSET/HMSET等都支持一次输入多个key,LPUSH/RPUSH/SADD等命令都支持一次输入多个value,也要注意每次操作数量不要过多,建议控制在500个以内;
PipeLining 模式 可以一次输入多个指令。redis提供一个 pipeline 的管道操作模式,将多个指令汇总到队列中批量执行,可以减少tcp交互产生的时间,一般情况下能够有10%~30%不等的性能提升;
更快的是Lua Script模式,还可以包含逻辑。redis内嵌了 lua 解析器,可以执行lua 脚本,脚本可以通过eval等命令直接执行,也可以使用script load等方式上传到服务器端的script cache中重复使用。
04减少不必要的请求
案例
某业务系统,当用户进入某个页面时会同时请求多个接口,每个接口都会校验用户状态是否有效,用户状态存在redis里并设置有过期时间,对于key未过期但是过期时间大于指定阈值的,需要重新设置有效时间,否则需要使用del命令删除掉。但是部分key由于过期其实已经不存在了,所以出现部分无效del命令。用户越多,就会有越多的无效命令。
分析
ttl命令对于key不存在的情况会返回-2,若key不存在则不需要再调用del命令,可减少无效请求。
小结
redis的所有请求对于不存在的key都会有输出返回,合理利用返回值处理,避免不必要的请求,提升业务吞吐量。
05避免value设置过大
案例
某开发人员将一个商品集合信息序列化后用redis的字符串类型存储,使用的时候再反序列化成对象列表使用,大小超过1MB,在网络传输的时候由于数据比较大会触发拆包,会降低redis的吞吐量。
分析
数量比较多时可以考虑改用hash结构存储,每一个field是商品id,value是该商品对象,如果数量较大可使用hscan获取。
小结
String类型尽量控制在10KB以内。虽然redis对单个key可以缓存的对象长度能够支持的很大,但是实际使用场合一定要合理拆分过大的缓存项,1k 基本是redis性能的一个拐点。当缓存项超过10k、100k、1m性能下降会特别明显。关于吞吐量与数据大小的关系可见下面官方网站提供的示意图。
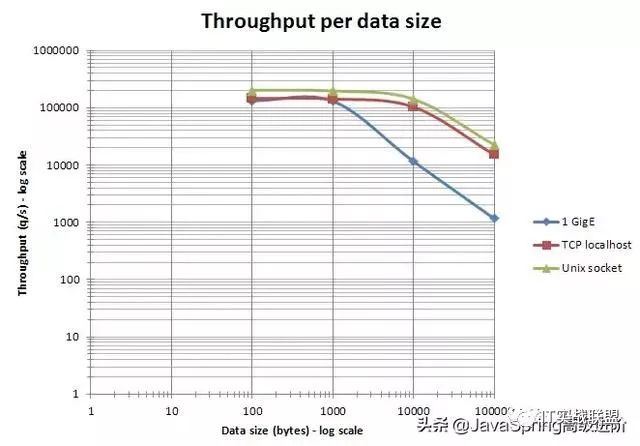
吞吐量与数据大小的关系
在局域网环境下只要传输的包不超过一个 MTU(以太网下大约 1500 bytes),那么对于 10、100、1000 bytes不同包大小的处理吞吐能力实际结果差不多。
06设计规范的key名
可读性
以业务名为前缀,用冒号分隔,可使用业务名:子业务名:id的结构命名,子业务下多单词可再用下划线分隔
举例:活动系统-人拉人红包活动-id,可命名为 ACTIVITY:INVITE_REDPACKET:001
简洁性
保证语义的前提下,控制key的长度,当key较多时,内存占用也不容忽视
不包含转义字符
不包含空格、换行、单双引号以及其他转义字符
07留心禁用命令
keys、monitor、flushall、flushdb应当通过redis的rename机制禁掉命令,若没有禁用,开发人员要谨慎使用。其中flushall、flushdb会清空redis数据;keys命令可能会引起慢日志;monitor命令在开启的情况下会降低redis的吞吐量,根据压测结果大概会降低redis50%的吞吐量,越多客户端开启该命令,吞吐量下降会越多。
keys和monitor在一些必要的情况下还是有助于排查线上问题的,建议可在重命名后在必要情况下由redis相关负责人员在redis备机使用,monitor命令可借助redis-faina等脚本工具进行辅助分析,能更快排查线上ops飙升等问题。
总 结
本文整理出的几点redis开发规范主要是涉及redis客户端的使用部分,每个开发人员在使用redis开发过程中几乎都会涉及到上述提到的几个问题,需要多多留心,提高代码质量,提升redis的健康度。
---------------END----------------
后续的内容同样精彩
长按关注“IT实战联盟”哦

注意:本文归作者所有,未经作者允许,不得转载

