自从微软收购了GitHub后,越来越拥抱开源了。在今年的 Spark + AI 峰会上,微软宣布 .NET for Apache Spark,并推出了首个预览版本 v0.1.0,这是一个用于 Spark 大数据的 .NET 框架,可以让 .NET 开发者轻松地使用 Apache Spark。近期在.net Foundation GitHub看到开源了.NET for Apache Spark。

从更新记录上看到还在不断的更新内容。
.NET for Apache®Spark™
.NET for Apache Spark 提供高性能的 .NET API 以便轻松的在 C# 和 F# 程序中使用 Apache Spark 。你可以访问最受欢迎的 Dataframe 和 SparkSQL ,可以处理结构化数据和 Spark Structured Streaming 流数据。

.NET for Apache Spark符合.NET标准 - .NET API的正式规范,在.NET实现中很常见。这意味着您可以在编写.NET代码的任何地方使用.NET for Apache Spark,从而允许您重用作为.NET开发人员已有的所有知识,技能,代码和库。
.NET for Apache®Spark 架构
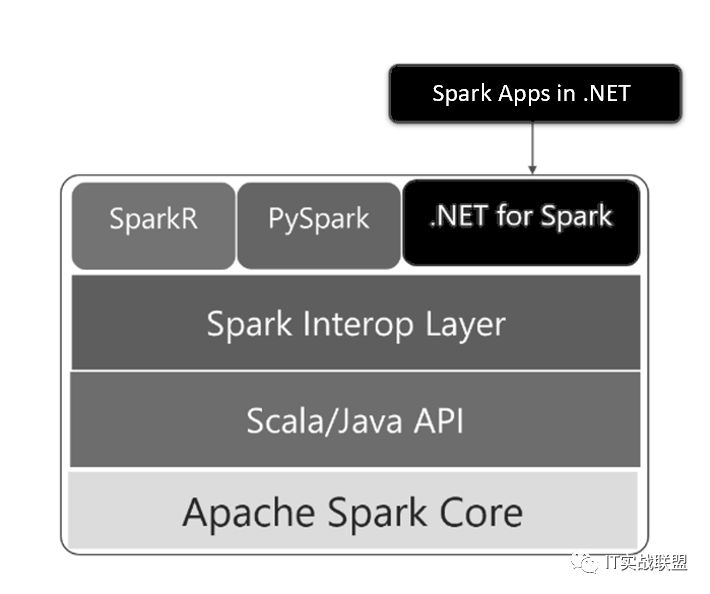
.NET for Apache Spark 兼容 .NET 标准,支持 Windows, Linux 和 macOS ,使用 .NET Core,或者是 Windows 下使用 .NET Framework。同时也可以运行在主流的云平台上,包括:Azure HDInsight Spark, Amazon EMR Spark, AWS & Azure Databricks.
.NET for Apache®Spark 性能
一项新技术的诞生作为技术人员首先考虑到的是有哪些方面比较突出或者吸引眼球的地方,那么大家可以看一下.net for apache spark 的性能表现:
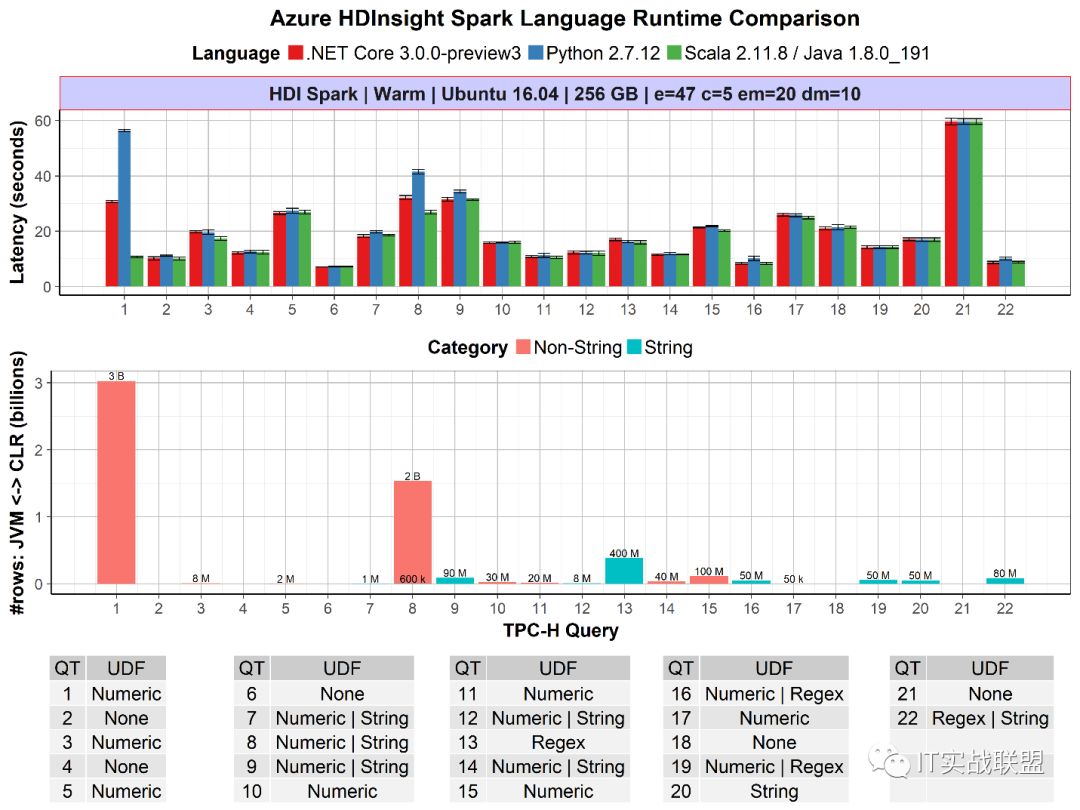
上图显示了针对Apache Spark与Python和Scala的.NET的每个查询性能。.NET for Apache Spark在Python和Scala上运行良好。此外,在UDF性能至关重要的情况下,例如查询1,其中在JVM和CLR .NET之间传递3B行非字符串数据,Apache Spark比Python快2倍。
同样重要的是要说这是我们为Apache Spark首次推出的.NET,我们的目标是进一步投资改进和基准性能(例如Arrow优化)。您可以按照我们的说明在我们的GitHub仓库上对此进行基准测试。
可以说是完全碾压毫无压力!
.NET for Apache®Spark 下一步展望
.NET for Apache Spark是将.NET打造成构建大数据应用程序的重要技术堆栈的第一步。近期规划路线
简化入门体验,文档和示例
与Visual Studio,Visual Studio Code,Jupyter笔记本等开发人员工具进行本机集成
.NET支持用户定义的聚合函数
用于C#和F#的.NET惯用API(例如,使用LINQ编写查询)
开发即用支持Azure Databricks,Kubernetes等。
为Spark Spark创建.NET for Spark Spark。您可以
在此处关注此进度。
.NET for Apache®Spark 入门
准备条件:
有关详细说明,您可以在Windows上看到从源代码构建针对Apache Spark的.NET。
从.NET为Apache Spark GitHub Releases页面选择Microsoft.Spark.Worker版本并下载到本地计算机(例如
c:\bin\Microsoft.Spark.Worker\)。重要信息创建新的环境变量
DotnetWorkerPath并将其设置为下载并解压缩Microsoft.Spark.Worker的目录(例如,c:\bin\Microsoft.Spark.Worker)。下载并安装以下内容:.NET Core 2.1 SDK | Visual Studio 2019 | Java 1.8 | Apache Spark 2.4.1
下载并安装Microsoft.Spark.Worker版本:
为Apache Spark应用程序编写.NET:
打开Visual Studio - >创建新项目 - >控制台应用程序(.NET Core) - >名称:
HelloSparkMicrosoft.Spark从spark nuget.org feed中将Nuget包安装到解决方案中- 请参阅安装Nuget Package的方法将以下代码写入
Program.cs:var spark = SparkSession。Builder()。GetOrCreate();
var df = spark。阅读()。Json(“ people.json ”);
df。显示();构建解决方案
运行.NET for Apache Spark App:
打开终端并导航到您的app文件夹:
cd <your-app-output-directory>people.json使用以下内容创建:{ “ name ”:“ Michael ” }
{ “ name ”:“ Andy ”,“年龄”:30 }
{ “ name ”:“贾斯汀”,“年龄”:19 }运行你的应用程序
spark-submit `
--class org.apache.spark.deploy.DotnetRunner `
--master local `
microsoft-spark-2.4.x-<version>.jar `
HelloSpark
请注意,此命令假定您已下载Apache Spark并将其添加到PATH环境变量中。
开源地址:https://github.com/dotnet/spark
---------------END----------------
后续的内容同样精彩
长按关注“IT实战联盟”哦

注意:本文归作者所有,未经作者允许,不得转载

