
Anith 在他非常成功的文章 Facts and Fallacies about First Normal Form 之后,对五个常见的数据库设计错误进行了引人入胜的讨论,尽管使用它们的不幸后果众所周知,但这些错误仍然存在。对于任何必须设计数据库的人来说,这是一个需要的提醒。
我们行业中的大多数人都知道糟糕的数据库设计的危险,但在现实世界的数据库中却忽略了它们。有害的设计缺陷常常被忽视。在某些情况下,DBMS 或 SQL 语言本身的限制可能会导致问题。在另一些情况下,可能是缺乏经验的数据库设计人员更注重编写奇特的代码,而未能专注于拥有良好的数据模型。
简单地说,数据库设计是将现实世界的一部分的事实转化为逻辑模型的过程。然后可以实现该模型,并且通常使用关系数据库来实现。虽然关系数据库确实拥有坚实的逻辑和基于集合的数学基础,但数据库设计过程的科学严谨性还涉及美学和直觉;但它当然也包括设计师的主观偏见。但这对设计有多大影响?在本文中,我将尝试解释人们在建模表格时犯的五个常见设计错误,并提出一些有关如何避免这些错误的指南。
(1) 常用查找表
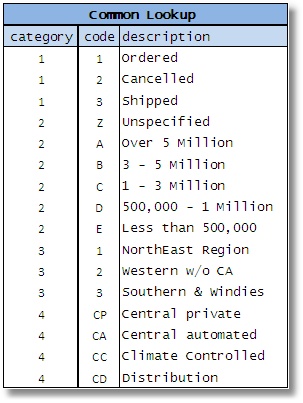
图1
几年前,Don Peterson 为SQL Server Central写了一篇文章,详细介绍了为通常称为代码表或“允许值表”(AVT) 的各种类型的数据创建单个查找表的常见做法。这些表往往很大,并且有一堆不相关的数据。Don 恰当地将这些表称为大规模统一代码密钥 (MUCK) 表(Peterson,2006 年),尽管多年来许多其他人已经写过有关它的文章,但这个名称似乎最有效地体现了与这种结构相关的笨拙之处。
在许多情况下,这些表中的数据是 VARCHAR(n) 尽管这些值的实际数据类型可以是从INTEGER到DATETIME 的任何内容。它们主要在三列中表示,这些列可能采用某种形式的示例表(图 1):
这里的理由是这里示例中的每个实体都有一组相似的属性,因此可以将其塞入单个表中。毕竟,它导致更少的表,使数据库更简单,对吧?
在设计过程中,数据库设计人员可能会遇到几个小表(在示例中,这些表代表不同类型的实体,例如“订单状态”、“金融资产优先级”、“位置代码”、“类型”仓库等)。
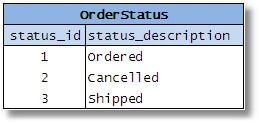
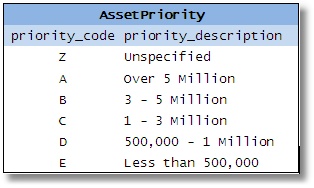
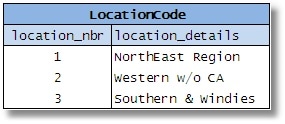

图 2-5
然后他决定将它们全部合并,因为它们的列相似。他假设他正在消除冗余表并简化数据库;他将拥有更少的表,他将节省空间,提高效率等。人们还认为它降低了所需 SQL 的复杂性,因为可以编写单个例程/存储过程来访问任何类型的数据。
那么它有什么问题呢?
- 首先,您失去了确保数据准确的手段;约束。通过将不同的实体组合到一个表中,您无法通过声明方式来限制某个类别的值。如果不在所有引用键中添加categoryid,就没有简单的方法来强制执行简单的外键约束。
- 其次,您被迫使用这种类型的通用查找表将每种数据类型表示为字符串。不同类型的这种混合可能是一个问题,因为如果没有主要的代码黑客攻击就不能强加检查约束。在我们给出的示例中,如果折扣代码是 CHAR(3) 并且location_nbr是 INT(4),那么 Common Lookup 表中“代码”列的数据类型应该是什么?
- 第三,你致力于僵化和随之而来的复杂性。你可能会问,这样一个看似简单灵活的设计怎么可能是死板的?好吧,考虑我们的常见查找表方案示例,想象一下“LocationCode”表包含另一列可能是“region”。将状态添加到“DiscountType”表的后果如何?只是为了更改单个类别,您必须考虑为表中的所有行让路,而不管新列是否适用于它们。复杂度怎么样?通常使用通用查找表的想法来自将实体泛化的想法,其中单个表代表一个“事物”——几乎任何东西。
将此与基本规则形成对比,即精心设计的表格表示一组关于同类实体或关系的事实。泛化实体的问题在于,表格会变成一堆不相关的行:因此,您会失去意义的精确性,随之而来的是混乱,并且通常会出现不必要的复杂性。
DBMS 的主要目标是强制执行控制数据表示和操作方式的规则。确保您不会在数据库设计的上下文中混淆术语“概括”、“重用”等,以至于您无法控制正在设计的内容。 - 第四也是最后,您面临着物理实施问题。虽然逻辑设计被认为与物理实现完全分开,但在 SQL Server 等商业 DBMS 产品中,物理实现会受到逻辑设计的影响,反之亦然。在大型企业中,这种常见的查找表可能会增长到数十万行,并且需要大量的物理数据库调优。还必须控制如此大表的锁定和并发问题。物理存储中特定行集的内部表示可能是决定 SQL 查询访问和操作值的效率的决定因素。
作为一般建议,始终为每个逻辑实体使用单独的表,用正确的类型、约束和引用标识适当的列。最好编写简单的例程和程序来访问和操作表中的数据,而不是针对“动态代码”。
通用查找表在合理的数据库设计中没有地位,无论是用作短期临时修复还是用作长期可行的解决方案。虽然应用程序强制的完整性有时受到开发人员的青睐,但 DBMS 仍然必须是所有完整性的集中执行者,这仍然是事实。因为给定数据库设计的首要目标是保持数据完整性和逻辑正确性,所以常见的查找表是人们可能犯的最严重的错误之一。
(2) 检查约束难题
检查约束有多种用途,但在两个方面给设计者带来麻烦:
- 他们错过了在必要时声明适当的检查约束。
- 他们不知道何时使用列级约束而不是具有外键约束的表。
SQL Server 中的约束可以用于许多不同的目的,包括对域约束、列约束以及在某种程度上的表约束的支持。数据库的主要目的是保持数据完整性,而明确定义的约束提供了一种极好的方法来控制列中允许使用哪些值。
那么,您是否应该避免使用检查约束?好吧,让我们考虑可以使用引用表(带有外键的表)来限制具有一组特定值的列的情况。

图 6
这里的值ins_code在投保人表可以从两个方面加以限制。一种方法是使用一个查找表来保存ins_code的允许值。另一种方法是在PolicyHolders表上设置一个检查约束,如下所示:
|
|
CHECK ( ins_code IN ( 'IC', 'FS', 'MC', 'PPO', 'POS', 'HMO' ) )
|
那么选择正确方法的经验法则是什么?数据库设计的老手会寻找三个特定标准来管理他们在检查约束或具有外键约束的单独表之间的选择。
- 如果值列表在一段时间内发生变化,则必须使用带有外键约束而不是检查约束的单独表。
- 如果值列表大于 15 或 20,则应考虑单独的表。
- 如果值列表是共享的或可重用的,在同一个数据库中至少使用了 3 次或更多次,那么使用单独表的情况非常好。
请注意,数据库设计是艺术与科学的结合,因此需要权衡取舍。经验丰富的设计师可以根据对特定要求的明智判断进行权衡。
(3) 实体-属性-值表
理想情况下,一个表代表一组实体,每个实体都有一组表示为列的属性。有时,设计师可能会陷入另类编程“范式”的世界,并可能会尝试实施它们。一种这样的模型称为实体-属性-值(或在某些上下文中称为对象-属性-模型),它是具有三列的表的昵称,一列表示它应该表示的实体类型,另一列表示该实体的参数或属性或属性,以及该属性的实际值的第三个。
考虑以下记录员工数据的表示例:
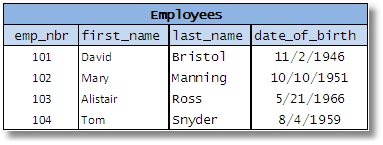
图 7
现在,EAV 方法将数据打乱,以便将属性表示为一列中的值,并将这些属性的相应值表示为另一列中的值:
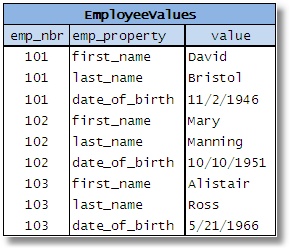
图 8
把这个发挥到极致,不需要额外的表——所有数据都可以塞进一个表中!这项发明归功于所谓的“临床数据库”设计者,他们决定当各种数据元素未知、部分已知或稀疏时,最好使用 EAV (Nadkarni, 2002)。问题是许多新手被诱惑在 SQL 数据库中应用这种方法,结果通常是混乱的。事实上,很多人认为不了解数据的本质是件好事!
那么被吹捧为 EAV 的好处是什么?嗯,没有。由于 EAV 表将包含任何类型的数据,我们必须将数据透视为带有适当列的表格表示,以使其有用。在许多情况下,中间件或客户端软件会在幕后执行此操作,从而让用户误以为他们正在处理精心设计的数据。
EAV 模型有很多问题。
- 首先,海量数据本身基本上是无法管理的。
- 其次,没有可能的方法来定义必要的约束——任何潜在的检查约束都必须包括适当的属性名称的大量硬编码。由于单个列包含所有可能的值,因此数据类型通常是 VARCHAR(n)。
- 第三,甚至不要考虑拥有任何有用的外键。
- 最后,还有查询的复杂性和笨拙性。有些人认为能够在必要时将各种数据塞入一个表中是一个好处——他们称之为“可扩展”。实际上,由于 EAV 将数据与元数据混合在一起,即使对于简单的要求,操作数据也更加困难。考虑一个简单的查询来检索 1950 年以后出生的员工。在传统模型中,您有:
|
|
SELECT first_name, last_name
FROM Employees
WHERE date_of_birth > '12/31/1950' ;
|
在 EAV 模型中,这是编写可比较查询的一种方法:
|
|
SELECT MAX( CASE emp_property WHEN 'first_name'
THEN value
END ) AS first_name,
MAX( CASE emp_property WHEN 'last_name'
THEN value
END ) AS last_name
FROM EmployeeValues
WHERE emp_nbr IN ( SELECT emp_nbr
FROM EmployeeValues
WHERE emp_property = 'date_of_birth'
AND CAST( value AS DATETIME ) > '12/31/1950' )
AND emp_property IN ( 'first_name', 'last_name' )
GROUP BY emp_nbr ;
|
清单 1
对于那些熟练使用 Transact-SQL 的人来说,继续添加一些具有不同数据类型的新列并尝试一些查询,看看它有多有趣!
EAV 噩梦的解决方案很简单:分析和研究用户的需求,并预先确定数据需求。关系数据库维护数据的完整性和一致性。在没有明确定义的需求的情况下,几乎不可能为设计这样的数据库提供理由。时期。
(4) 应用程序侵入数据库设计
应用程序可以通过多种方式侵入数据管理领域。我将简要解释几种方法,并就如何预防它提出一些指导方针。
通过应用程序强制执行完整性
基于应用程序完整性的支持者通常认为约束会对数据访问产生负面影响。他们还假设根据应用程序的需要有选择地应用规则是最好的选择。
让我们详细看看这个。是否存在任何良好的统计测量、比较和分析来解决 DBMS 和应用程序强制执行的相同规则之间的性能差异?应用程序执行数据相关规则的效率如何?如果多个应用程序需要相同的规则,是否可以避免代码重复?如果 DBMS 中已经存在完整性强制机制,为什么要重新发明轮子?
解决方法很简单。
除了数据库本身之外,别无他物来提供完整性和正确性。没什么,我的意思既不是用户也不是数据库外部的应用程序。虽然当前的 DBMS 产品可能无法成功执行所有可能的约束,但让应用程序或用户承担该责任是不明智的。
您可能会问为什么依赖应用程序来强制执行数据完整性是不好的?好吧,如果每个数据库只有一个应用程序,那么这不是真正的问题。但通常,数据库充当数据的中央存储库并为多个应用程序提供服务。因此,必须在所有这些应用程序中强制执行规则。这些规则也可能会改变。
作为一般准则,数据库不仅仅是数据存储库;它们是与该数据相关联的规则的来源。在可能的情况下,在数据库中为每个应该强制执行的规则声明完整性约束。仅在无法通过键和约束进行声明性完整性强制时才使用存储过程和触发器。只需要通过应用程序实现特定于应用程序的规则。
摇摆数据库狗的应用程序尾巴:
开发人员社区越来越倾向于将数据库视为“应用程序域”的一个组件。通常,应用程序开发人员根据需要添加表,然后在事后添加列。
这很方便,因为它避免了设计过程中麻烦的部分,例如需求收集。经验告诉我们,在大多数企业中,应用程序来来去去,但数据库通常会持续很长时间。 因此,根据上下文中特定于业务部门的规则努力开发良好的设计是很有意义的。(泰瑞,1994 年)。
(5) 误用数据值作为数据元素
在继续之前让我们澄清一些事情:这里的“数据值”是指实体的属性值;“数据元素”指的是元数据单元,例如列名或表名。通过将数据值误用为数据元素,我指的是拆分某个实体的属性值并将其表示在多个列或表中的做法。Joe Celko 正是这样称呼它——“属性分裂” (Celko,2005)。
考虑一个表格,该表格代表为公司工作的一些销售人员的销售数据。让我们假设采用以下设计,以便更容易检索数据以显示它:
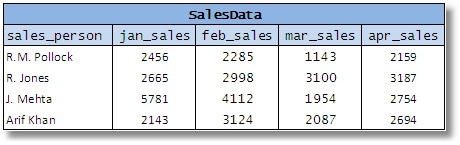
图 9
您将在此处看到业务模型中的单个属性“销售额”表示为一系列列。这使几乎每个使用这种方案的人的生活变得更加艰难。
现在,什么会使这种设计不受欢迎?
- 约束的重复会导致问题。必须为每个单独的列定义适用于每月销售额的任何约束。
- 如果不更改表格,则无法添加新月份的销售额。一种糟糕的选择是为所有可能的月销售额设置列,并在没有销售额的月份使用 NULL。
- 最后,难以表达相对简单的查询,例如比较销售人员之间的销售额或找到最佳月销售额。
顺便说一句,很多人认为这是违反第一范式的。这是一种误解,因为这里没有多值列 (Pascal,2005)。详细论述请参考浅谈文章:Facts and Fallacies about First Normal Form
设计这张桌子的理想方式是:
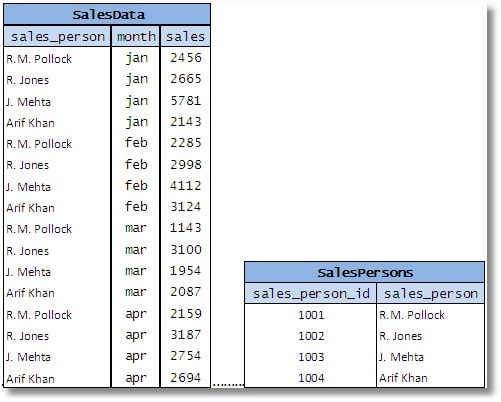
图 10
当然,您可以为销售人员创建一个单独的表,然后使用外键引用它,最好使用简单的代理键,例如sales_person_id,如上所示。
如果您被设计为图 9 的表格卡住了,您可以通过几种不同的方式从代码创建结果集:
1. 使用 UNION 查询:
|
|
SELECT sales_person, 'jan' AS "month", jan_sales AS "sales"
FROM salesdata
UNION ALL
SELECT sales_person, 'feb', feb_sales
FROM salesdata
UNION ALL
SELECT sales_person, 'mar', mar_sales
FROM salesdata
UNION ALL
SELECT sales_person, 'apr', apr_sales
FROM salesdata ;
|
2. 使用 JOIN 连接到具有列名的派生表:
|
|
SELECT sales_person,
m AS "month",
CASE m WHEN 'jan' THEN jan_sales
WHEN 'feb' THEN feb_sales
WHEN 'mar' THEN mar_sales
WHEN 'apr' THEN apr_sales
END AS sales
FROM salesdata
CROSS JOIN ( SELECT 'jan' UNION
SELECT 'feb' UNION
SELECT 'mar' UNION
SELECT 'apr' ) months ( m ) ;
|
3. 使用 UNPIVOT:
|
|
SELECT sales_person, "month", sales
FROM ( SELECT sales_person,
jan_sales, feb_sales, mar_sales, apr_sales, may_sales
FROM salesdata ) s ( sales_person, jan, feb, mar, apr, may )
UNPIVOT
( sales FOR "month" IN ( jan, feb, mar, apr, may ) ) m ;
|
像往常一样,您必须针对基础表进行测试,并考虑数据量和现有索引等因素,以确保哪种方法最有效。
这种方法的另一个变体是跨表拆分属性,即使用数据值作为表名本身的一部分。这通常通过拥有多个结构相似的表来完成。考虑以下一组表:
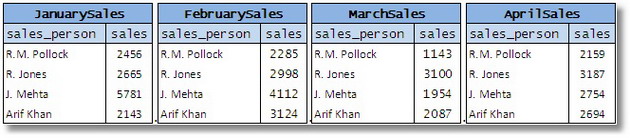
图 11
这里,属性“month”的各个值被分配给每个表。这种设计具有类似的缺点,例如约束重复和难以表达简单查询。为了有用,这些表必须被联合以形成一个带有代表月份的附加列的单个表。从单个基表开始会更容易。
我们应该小心不要将拆分属性与逻辑设计原则与表分区混淆,表分区是在物理级别完成的数据重组过程,它从大表或索引创建更小的数据子集,以尝试有效地管理和访问它们。
顺便提一下,这个问题已经被关系理论家大量讨论,特别是关于它对视图更新施加的限制。有些人认为它直接违反了信息原则(一种关系原则,它要求将数据库中的所有数据仅表示为表中的值),并建议数据库中的两个表不应具有重叠的含义。最初定义为新设计原则,这种建议每个表具有单一含义或谓词,目前在关系文献中称为正交设计原则(Date & McGoveran, 1995)。
结论
为完善的数据库模式建模总是值得花时间的。它不仅为您提供了一个易于访问和维护的模式,而且还避免了您定期修补漏洞。数据库设计人员通常会寻找捷径以节省时间和精力。不管它们看起来多么花哨,大多数杂物都是短暂的,最终会花费更多的时间、精力和费用。一个好的干净设计可能只需要遵循一些简单的规则,而遵循这些规则的决心是真正的数据库专业人员的特征。
注意:本文归作者所有,未经作者允许,不得转载

