来自:高可用架构
原文:https://mp.weixin.qq.com/s/_Ih4AyL2c1JjyLwKCPmphg
本文是一篇关于 Dubbo 地址推送性能的压测文章,我们期望通过对比的方式展现 Dubbo3 在性能方面的提升,尤其是新引入的应用级地址模型。但要注意,这并不是官方正式版本的性能参考基线,并且由于环境和时间原因,部分对比数据我们并没有采集,但只要记住我们只是在定性的检测阶段成果,这些限制总体上并不会有太大影响。
1 摘要
本文主要围绕下一代微服务框架 Dubbo 3.0 在地址推送链路的性能测试展开,也是在性能层面对 Dubbo 3.0 在阿里落地过程中的一个阶段性总结,本轮测试了 Dubbo2 接口级地址发现、Dubbo3 接口级地址发现、Dubbo3 应用级地址发现。压测数据表明,在百万实例地址的压测场景下:
- 基于接口级地址发现模型,Dubbo3 与 Dubbo2 对比,有超过 50% 常驻内存下降,Full GC 间隔更是明显拉长
- Dubbo3 新引入的应用级服务发现模型,可以进一步可以实现在资源占用方面的大幅下降,常驻内存比 Dubbo3 接口级地址进一步下降 40%,应用实例扩缩容场景增量内存分配基本为零,相同周期内(1小时) Full GC 减少为 2 次。
Dubbo 3.0 作为未来支撑业务系统的核心中间件,其自身对资源占用率以及稳定性的提升对业务系统毫无疑问将带来很大的帮助。
2 背景介绍
2.1 下一代服务框架 Dubbo 3.0 简介
一句话概括 Dubbo 3.0**,它是 HSF & 开源 Dubbo 后的融合产品,在兼容两款框架的基础上做了全面的云原生架构升级,它将成为未来面向阿里内部与开源社区的主推产品。**
Dubbo 3.0 诞生的大背景是阿里巴巴在推动的全站业务上云,这为我们中间件产品全面拥抱云上业务,提供内部、开源一致的产品提出了要求也提供了契机,让中间件产品有望彻底摆脱自研体系、开源体系多线作战的局面,有利于实现价值最大化的局面。一方面阿里电商系统大规模实践的经验可以输出到社区,另一方面社区优秀的开发者也能参与到项目贡献中。以服务框架为例,HSF 和 Dubbo 都是非常成功的产品:HSF 在内部支撑历届双十一,性能优异且久经考验;而在开源侧,Dubbo 坐稳国内第一开源服务框架宝座,用户群体非常广泛。
同时维护两款高度同质化的产品,对研发效率、业务成本、产品质量与稳定性都是非常大的考验。举例来说,首先,Dubbo 与 HSF 体系的互通是一个非常大的障碍,在阿里内部的一些生态公司如考拉、饿了么等都在使用 Dubbo 技术栈的情况下,要实现顺利平滑的与 HSF 的互调互通一直以来都是一个非常大的障碍;其次,产品不兼容导致社区输出成本过高、质量验收等成本也随之增长,内部业务积累的服务化经验与成果无法直接赋能社区,二次改造适配 Dubbo 后功能性、稳定性验收都要重新投入验证。为彻底解决以上问题,结合上文提到的阿里集团业务整体上云、开源以及云产品输出战略,我们制定了全面发展 Dubbo 3.0 的计划,
2.2 Dubbo 不同版本在地址推送链路上的性能压测与对比
下图是服务框架的基本工作原理,橙色路径即为我们此次重点压测的地址推送链路,我们重点关注在百万地址实例推送的情况下,Dubbo 不同版本 Consumer 间的差异,尤其是 Dubbo 3.0 的实际表现。
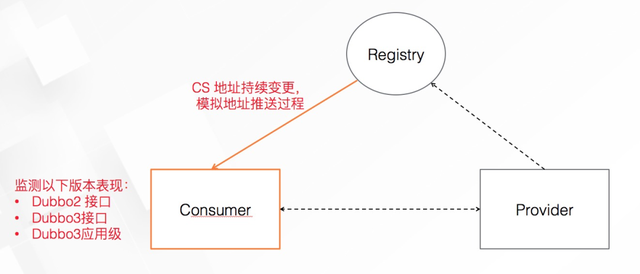
作为对比,我们选取了以下场景进行压测:
- Dubbo2,此次压测的参考基线
- Dubbo3 接口级地址发现模型,与 Dubbo2 采用的模型相同
- Dubbo3 应用级地址发现模型,由云原生版本引入,详细讲解请参见这篇文章
压测环境与方法

3 优化结果分析与对比
3.1 GC 耗时与分布
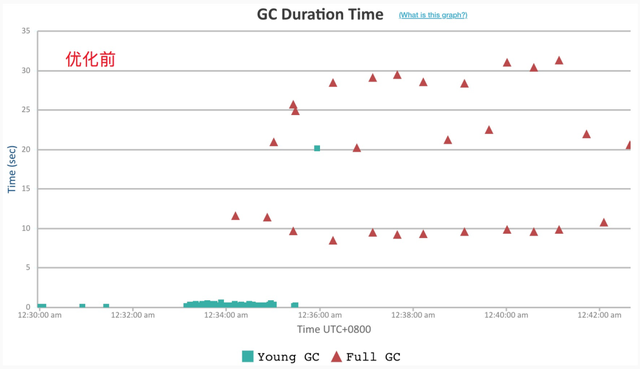
Dubbo2 接口级地址模型
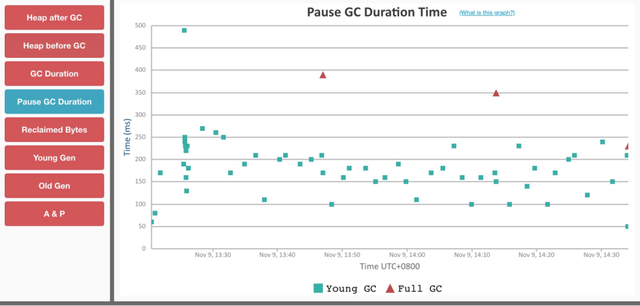
Dubbo3 接口级地址模型
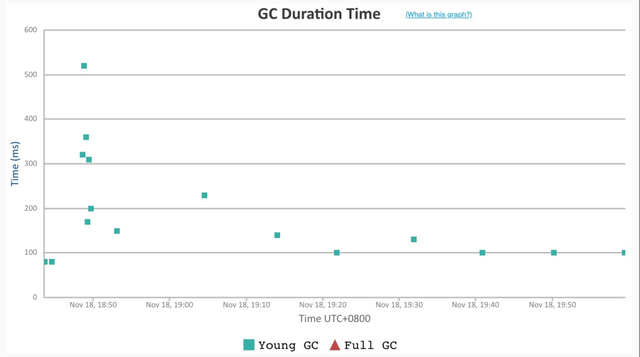
Dubbo3 应用级地址模型
3.2 增量内存分配情况
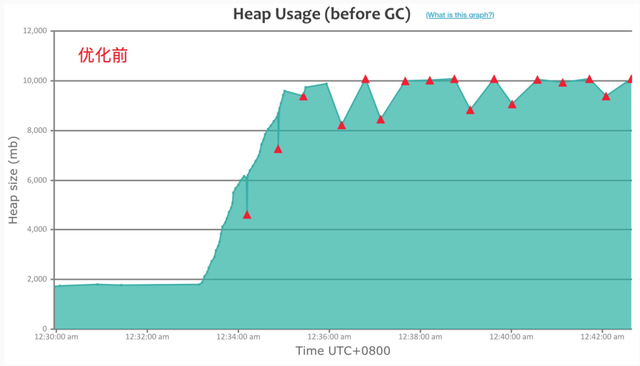
Dubbo2 接口级地址模型
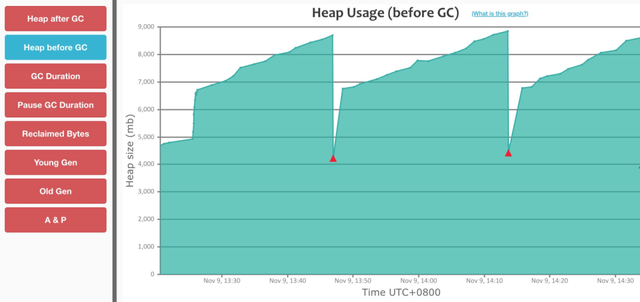
Dubbo 3.0 接口级地址模型
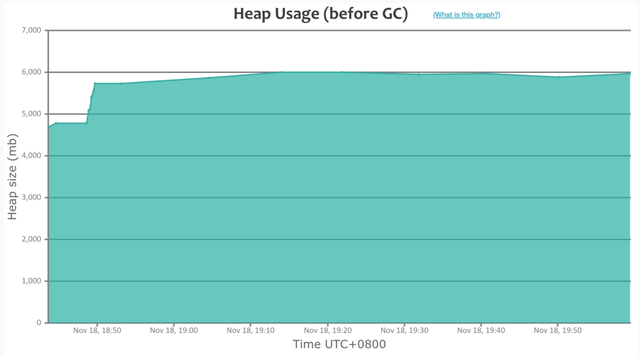
Dubbo3 应用级地址模型
3.3 OLD 区与常驻内存
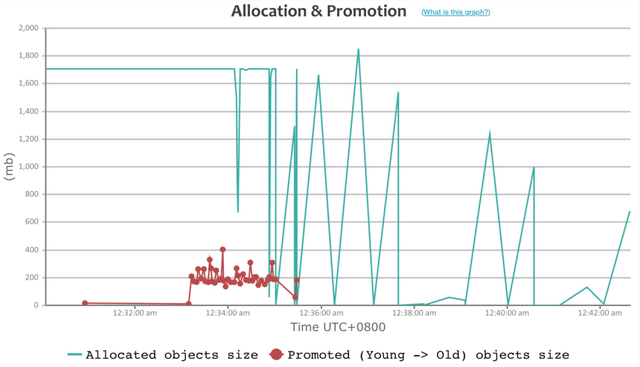
Dubbo2 接口级模型
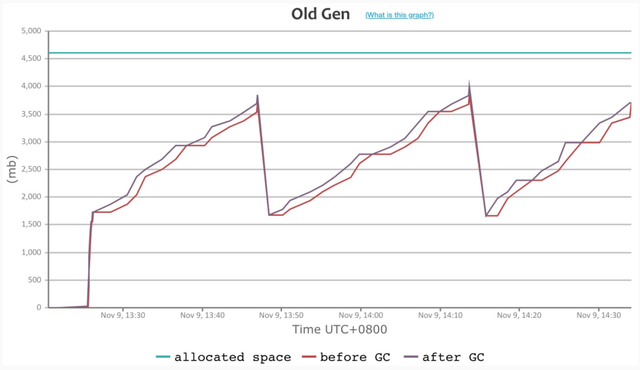
Dubbo3 接口级模型
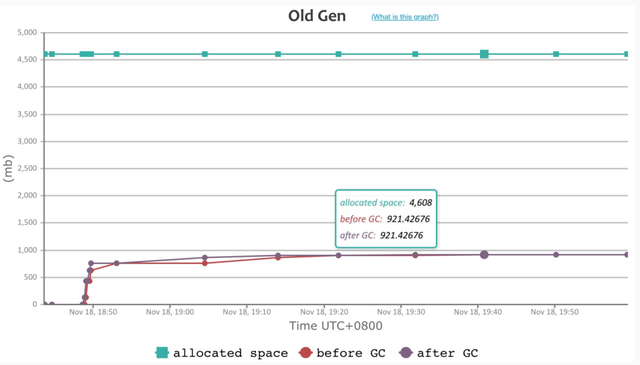
Dubbo3 应用级模型
3.4 Consumer 负载
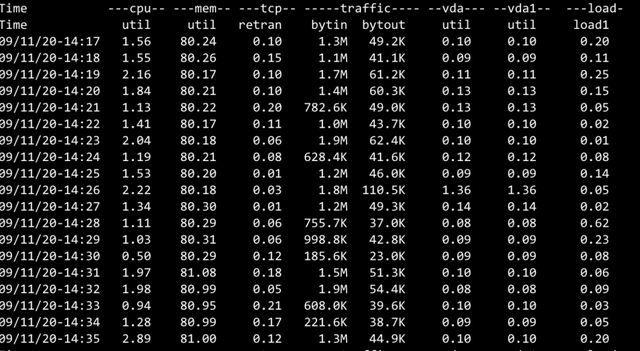
Dubbo3 接口级模型
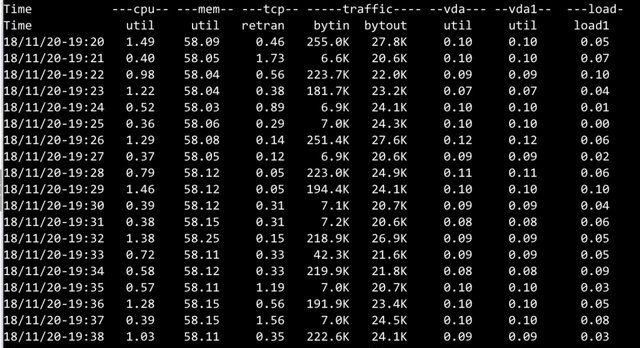
Dubbo3 应用级模型
4 详细对比与分析
4.1 Dubbo2接口模型 vs Dubbo3接口模型
在 200w 地址规模下,Dubbo2 很快吃满了整个堆内存空间,并且大部分都无法得到释放,而由此触发的频繁的 GC,使得整个 Dubbo 进程已无法响应,因此我们压测数据采集也没有持续很长时间;
同样保持接口级地址模型不变,经过优化后的 Dubbo3 ,在 1 个小时之内只有 3 次 Full GC,并且持续推送期间不可释放内存大概下降在 1.7G。
4.2 Dubbo3 接口模型 vs Dubbo3 应用模型
当切换到 Dubbo3 应用级服务发现模型后,整个资源占用情况又出现了明显下降,这体现在:
- 应用进程上下线场景,增量内存增长很小 (接口级的 MetadataData 基本得到完全复用,新增部分仅来自新扩容机器或部分服务的配置变更)
- 常驻内存相比 Dubbo3 接口级又下降了近 40%,维持在 900M 左右
值得一提的是,当前的应用级地址推送模型在代码实现还有进一步优化的空间,比如 Metadata 复用、URL 对象复用等,这部分工作将是我们后续探索的重点。
5 总结
Dubbo 3.0 目前已经实现了 Dubbo&HSF 的全面融合,云原生方案也在全面推进中。在刚刚过去的双十一中,Dubbo 3.0 平稳支撑了考拉业务,并且也已经通过阿里其他一些电商应用的部分线上试点。后续我们将专注在推动 Dubbo 3.0 的进一步完善,一方面兑现应用级服务发现、全新服务治理规则、下一代 Triple 协议等,另一方面兑现我们立项之初设定的资源占用、性能、集群规模等非功能性目标。
此次推送链路的性能压测,是落地/研发过程中的一次阶段性验收,应用级服务发现在资源占用方面大幅下降,让我们看到了新架构对未来构建真正可伸缩集群的可行性,这更坚定了我们对应用级服务发现架构的信心。后续迭代中,在继续完善接口级、应用级两种模型并实现 Dubbo 3.0 的全面性能领先后,我们将专注在迁移方案的实现上,以支持老模型到新模型的平滑、透明迁移。
注意:本文归作者所有,未经作者允许,不得转载

