来源:性能与架构
链接:https://mp.weixin.qq.com/s/s4k9nioEDd1m2g0quj9kqA

Pulsar 是类似于 Kafka 的一个消息中间件,是 Yahoo 开源的,可以说 Pulsar 就是针对 Kafka 的痛点而来的。
下面就说说 Kafka 都有哪些痛点,以及 Pulsar 的优质特性,当然还会说下它的不足。
1. Kafka 概述
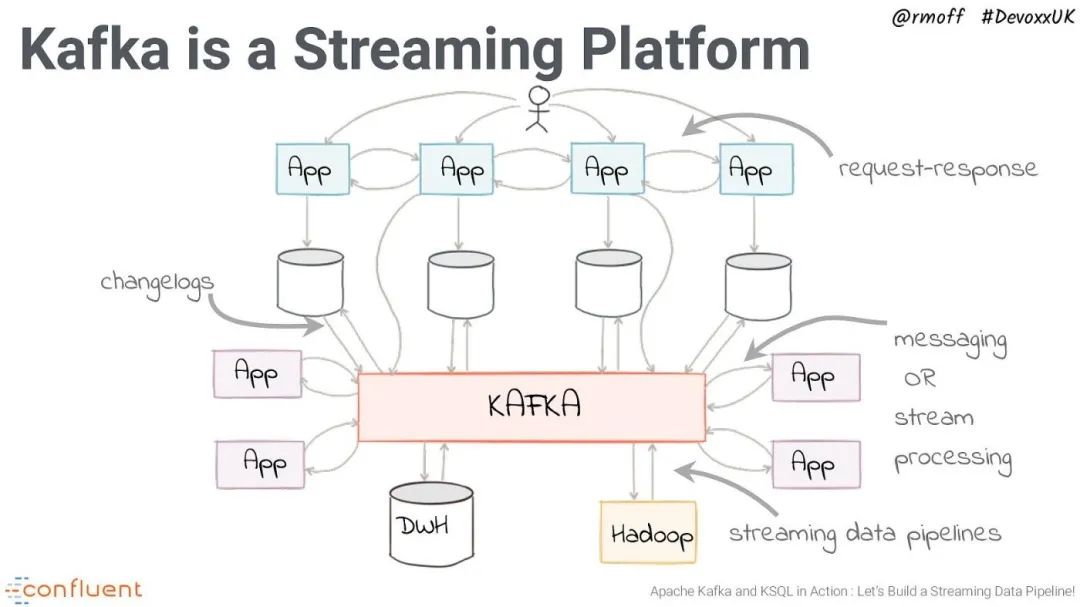
Kafka 于 2011 年由 LinkedIn 创建,发展到现在已经成为消息系统的王者,支持了越来越多的功能,例如:
- Schema Registry
- Kafka Connect,用于对接其他数据源
- Kafka Streams,用于分布式的流处理
- KSQL,用于对 Topic 进行类似 SQL 的查询
- ……
Kafka 速度快、安装简单,适用于非常多的使用场景,极其流行。
2. Kafka 痛点
- 扩展困难,这是 Kafka 架构造成的,broker 存储了数据,想要动 broker,就意味着 topic 分区以及副本的复制,非常耗时。
- 不支持完全独立的多租户模式。
- 异步复制的情况下可能丢失数据。
- 对于 broker、topic、partition、replica 的数量需要做一个规划,以便尽量避免扩展问题。
- 当你只需要一个单纯的消息系统时,基于 offset 的方式就有点麻烦。
- 集群再平衡会影响 producer 和 consumer 的性能。
- MirrorMaker Geo 复制机制有问题,例如 Uber 设计了自己的方案来克服此问题。
3. Pulsar 概述
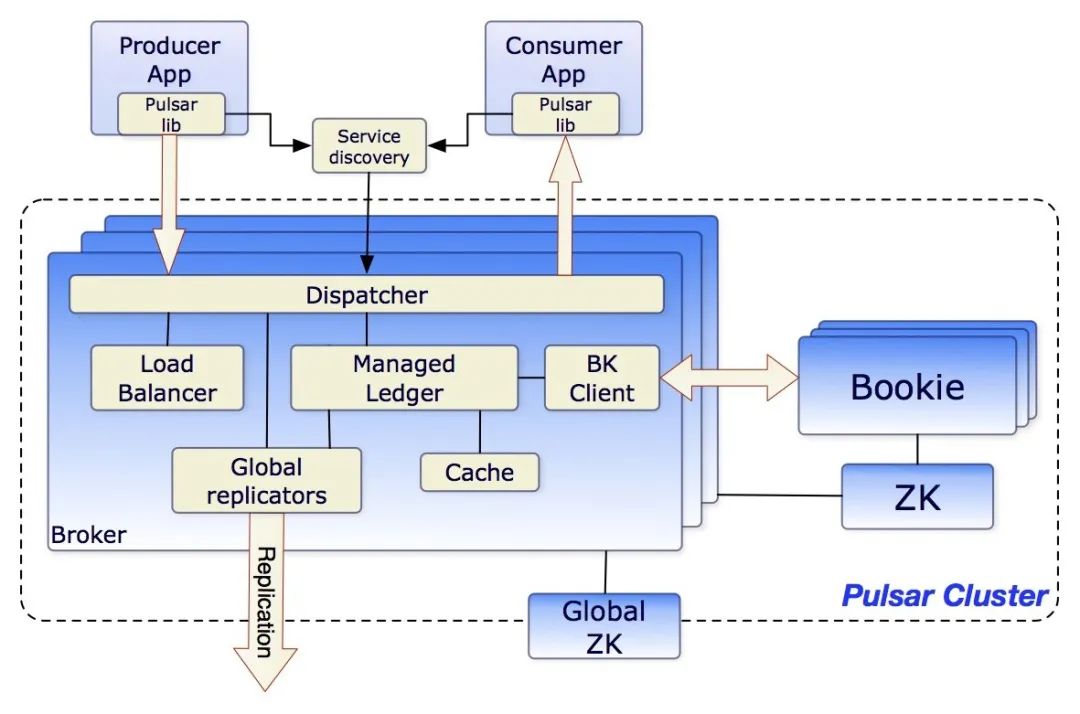
Pulsar 是 Yahoo 在 2013 年创建的,2016年贡献给了 Apache 基金会,目前已经是 Apache 的顶级项目。
Yahoo、Verizon、Twitter 等很多公司都在使用 Pulsar 来处理海量消息。
Pulsar 声称比 Kafka 更快、运行成本更低、解决了很多 Kafka 的痛点。
Pulsar 非常灵活,可以像 Kafka 一样作为分布式日志系统,也可以作为类似 RabbitMQ 这类简单的消息系统。
Pulsar 有多种订阅类型、传递保障、保存策略。
4. Pulsar 特性
- 内置多租户
不同的团队可以使用同一个集群,互相隔离。支持隔离、认证授权、配额。
- 多层架构
Pulsar 使用特定的数据层来存储 topic 数据,使用了 Apache BookKeeper 作为数据账本。Broker 与存储分离。
使用分隔机制可以解决集群的扩展、再平衡、维护等问题。也提升了可用性,不会丢失数据。
因为使用了多层架构,对于 topic 数量没有限制,topic 与存储是分离的,也可以创建非持久化的 topic。
- 多层存储
Kafka 中存储是很昂贵的,所以很少存储冷数据。Pulsar 使用了多层存储,可以自动把旧数据移动到专门的存储设备,例如 Amazon S3,但是对于客户端来讲是透明的,还可以正常使用。
- Functions
Pulsar Function 是一种部署简单,轻量级计算、对开发人员友好的 API,无需像 Kafka 那样运行自己的流处理引擎。
- 安全
内置了代理、多租户安全机制、可插入的身份验证等功能。
- 快速再平衡
partition 被分为了小块儿,所以再平衡时非常快。
- 多系统集成
例如 Kafka、RabbitMQ 等系统都可以轻松集成。
- 支持多种开发语言
例如 Go、Java、Scala、Node、Python 等等。
5. 小结
Pulsar 的确弥补了 Kafka 的很多不足,因为 Yahoo 就是为了解决这些问题而开发的 Pulsar。
但 Pulsar 也有明显的弱势,例如它的普及度比 Kafka 差太多了,而且 Kafka 有 Confluent 的专业支持,这个支持力度不是 Pulsar 能比的,由此就带来了其他问题,比如扩展插件太少、人才太少等等。
Pulsar 与 Kafka 各有所长,各有所短,没有技术是完美的,多一种技术就多一种选择,需要根据自己的情况来选择合适的技术。
参考资料:
https://itnext.io/pulsar-advantages-over-kafka-7e0c2affe2d6
注意:本文归作者所有,未经作者允许,不得转载

