1 什么时候用MQ?
1.1 MQ的基本概念
消息总线(Message Queue,MQ),是一种跨进程的通信机制,用于在上下游之间传递消息。MQ是一种常见的上下游“逻辑解耦+物理解耦”的消息通信服务,消息发送上游只需要依赖MQ,逻辑上和物理上都不用依赖其他服务。
1.2 MQ的使用场景
场景一:数据驱动的任务依赖
有些任务之间有一定的依赖关系,比如:task3需要使用task2的输出作为输入,task2需要使用task1的输出作为输入。这样的话,tast1, task2, task3之间就有任务依赖关系,必须task1先执行,再task2执行,再task3执行。对于这类需求,常见的实现方式是,使用cron人工排执行时间表:
task1,0:00执行,经验执行时间为50分钟;
task2,1:00执行(为task1预留10分钟buffer),经验执行时间也是50分钟;
task3,2:00执行(为task2预留10分钟buffer)
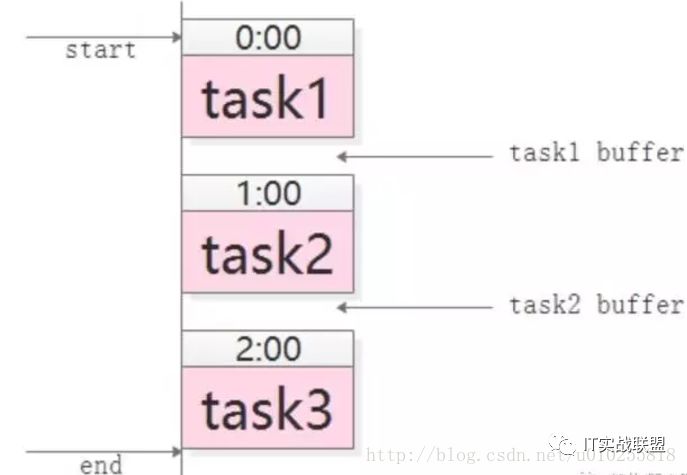
这种方法的坏处是:
如果有一个任务执行时间超过了预留buffer的时间,将会得到错误的结果;
总任务的执行时间很长,总是要预留很多buffer,如果前置任务提前完成,后置任务不会提前开始;
如果一个任务被多个任务依赖,这个任务将会称为关键路径,排班表很难体现依赖关系,容易出错;
如果有一个任务的执行时间要调整,将会有多个任务的执行时间要调整。
优化方案是,采用MQ解耦:task1准时开始,结束后发一个“task1 done”的消息;
task2订阅“task1 done”的消息,收到消息后第一时间启动执行,结束后发一个“task2 done”的消息;
task3同理

采用MQ的优点是:
不需要预留buffer,上游任务执行完,下游任务总会在第一时间被执行;
依赖多个任务,被多个任务依赖都很好处理,只需要订阅相关消息即可;
有任务执行时间变化,下游任务都不需要调整执行时间
需要特别说明的是,MQ只用来传递上游任务执行完成的消息,并不用于传递真正的输入输出数据。
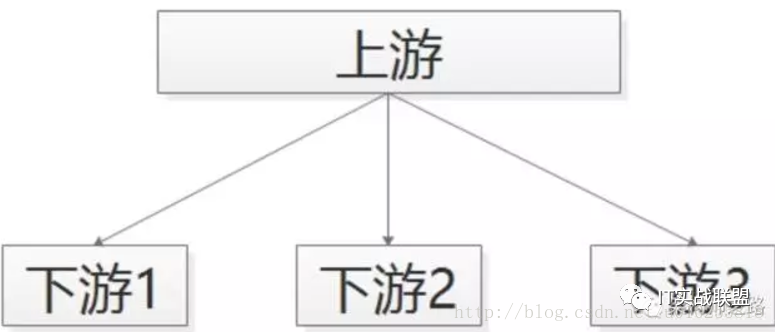
场景二:上游不必关心执行结果
上游需要关注执行结果时要用“调用”;上游不关注执行结果时,就可以使用MQ了。58同城的很多下游需要关注“用户发布帖子”这个事件,比如用户发布帖子后,修改用户统计数据。
对于这类需求,常见的实现方式是使用调用关系:帖子发布服务执行完成之后,调用下游业务来完成消息的通知。但事实上,这个通知是否正常正确的执行,帖子发布服务根本不关注。
这种方法的坏处是:
帖子发布流程的执行时间增加了;
下游服务宕机,可能导致帖子发布服务受影响,上下游逻辑+物理依赖严重;
每当增加一个需要知道“帖子发布成功”信息的下游,修改代码的是帖子发布服务,属于架构设计中典型的依赖倒转。
优化方案是,采用MQ解耦:
帖子发布成功后,向MQ发一个消息;
哪个下游关注“帖子发布成功”的消息,主动去MQ订阅
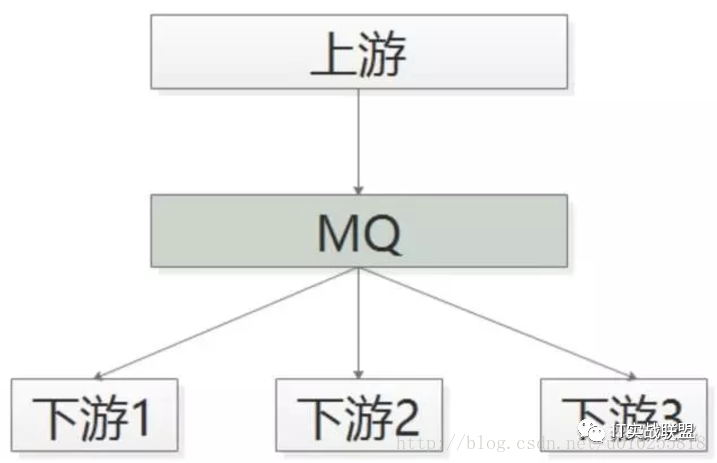
采用MQ的优点是:
上游执行时间短;
上下游逻辑+物理解耦,除了与MQ有物理连接,模块之间都不相互依赖;
新增一个下游消息关注方,上游不需要修改任何代码
场景三:上游关注执行结果,但执行时间很长
有时候上游需要关注执行结果,但执行结果时间很长。微信支付,跨公网调用微信的接口,执行时间会比较长,但调用方又非常关注执行结果,此时一般怎么玩呢?
一般采用“回调网关+MQ”方案来解耦:
调用方直接跨公网调用微信接口;
微信返回调用成功,此时并不代表返回成功;
微信执行完成后,回调统一网关;
网关将返回结果通知MQ;
请求方收到结果通知
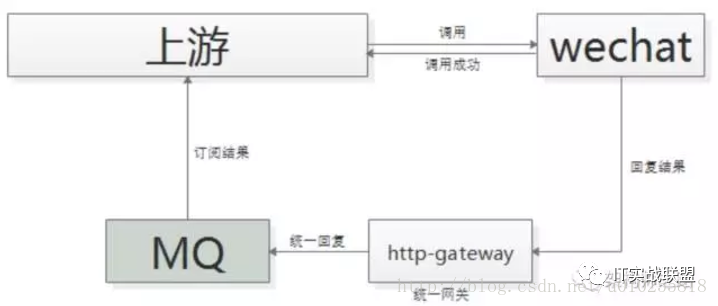
这里需要注意的是,不应该由回调网关来调用上游来通知结果,如果是这样的话,每次新增调用方,回调网关都需要修改代码,仍然会反向依赖,使用回调网关+MQ的方案,新增任何对微信支付的调用,都不需要修改代码啦。
1.3 什么时候不使用MQ
虽然MQ是分层架构中的解耦利器,但调用与被调用的关系,是无法被MQ取代的。
MQ的不足是:
系统更复杂,多了一个MQ组件;
消息传递路径更长,延时会增加;
消息可靠性和重复性互为矛盾,消息不丢不重难以同时保证;
上游无法知道下游的执行结果,这一点是很致命的
例如:用户登录场景,登录页面调用passport服务,passport服务的执行结果直接影响登录结果,此处的”登录页面”与”passport服务”就必须使用调用关系,而不能使用MQ通信。
1.4 总结
MQ是一个互联网架构中常见的解耦利器。
什么时候不使用MQ?上游实时关注执行结果。
什么时候使用MQ?1)数据驱动的任务依赖; 2)上游不关心多下游执行结果; 3)异步返回执行时间长。
2 MQ是如何做到消息必达?
MQ要想尽量消息必达,架构上有两个核心设计点:(1)消息落地(2)消息超时、重传、确认。
2.1 MQ核心架构
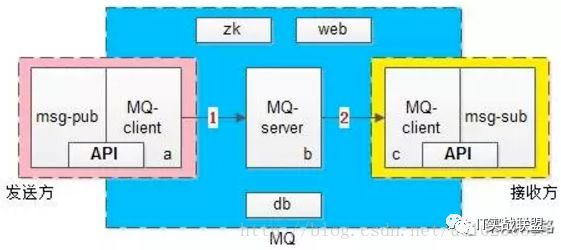
MQ是一个系统间解耦的利器,它能够很好的解除发布者、订阅者之间的耦合,将上下游的消息投递解耦成两个部分。MQ的核心架构图,基本可以分为三大块:
发送方 -> 左侧粉色部分,由两部分构成:业务调用方与MQ-client-sender,其中后者向前者提供了两个核心API:SendMsg(bytes[] msg)、SendCallback();
MQ核心集群 -> 中间蓝色部分,分为四个部分:MQ-server,zk,db,管理后台web;
接收方 -> 右侧黄色部分,由两部分构成:业务接收方与MQ-client-receiver,其中后者向前者提供了两个核心API:RecvCallback(bytes[] msg)、SendAck()
2.2 MQ消息可靠投递核心流程
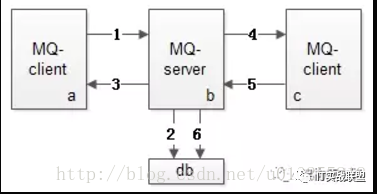
MQ既然将消息投递拆成了上下半场,为了保证消息的可靠投递,上下半场都必须尽量保证消息必达。
MQ消息投递上半场,MQ-client-sender到MQ-server流程见上图:
MQ-client将消息发送给MQ-server(此时业务方调用的是API:SendMsg);
MQ-server将消息落地,落地后即为发送成功;
MQ-server将应答发送给MQ-client(此时回调业务方是API:SendCallback)
MQ消息投递下半场,MQ-server到MQ-client-receiver流程见上图:
MQ-server将消息发送给MQ-client(此时回调业务方是API:RecvCallback);
MQ-client回复应答给MQ-server(此时业务方主动调用API:SendAck);
MQ-server收到ack,将之前已经落地的消息删除,完成消息的可靠投递
2.3 如果消息丢了怎么办?
MQ消息投递的上下半场,都可以出现消息丢失,为了降低消息丢失的概率,MQ需要进行超时和重传。
2.3.1 上半场的超时与重传
MQ上半场的1或者2或者3如果丢失或者超时,MQ-client-sender内的timer会重发消息,直到期望收到3,如果重传N次后还未收到,则SendCallback回调发送失败,需要注意的是,这个过程中MQ-server可能会收到同一条消息的多次重发。
2.3.2 下半场的超时与重传
MQ下半场的4或者5或者6如果丢失或者超时,MQ-server内的timer会重发消息,直到收到5并且成功执行6,这个过程可能会重发很多次消息,一般采用指数退避的策略,先隔x秒重发,2x秒重发,4x秒重发,以此类推,需要注意的是,这个过程中MQ-client-receiver也可能会收到同一条消息的多次重发。
3.MQ如何做到消息幂等
3.1 消息必达的前提
MQ消息必达,架构上有两个核心设计点:消息落地,消息超时、重传、确认
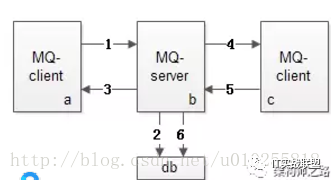
它由发送端、服务端、固化存储、接收端四大部分组成。为保证消息的可达性,超时、重传、确认机制可能导致消息总线、或者业务方收到重复的消息,从而对业务产生影响。所以,MQ幂等性设计至关重要。
3.2 上半场的幂等性设计
MQ消息发送上半场,即上图中的步骤1-3
发送端MQ-client将消息发给服务端MQ-server;
服务端MQ-server将消息落地;
服务端MQ-server回ACK给发送端MQ-client
如果3丢失,发送端MQ-client超时后会重发消息,可能导致服务端MQ-server收到重复消息。此时重发是MQ-client发起的,消息的处理是MQ-server。
为了避免步骤2落地重复的消息,对每条消息,MQ系统内部必须生成一个inner-msg-id,作为去重和幂等的依据,这个内部消息ID的特性是:
1)全局唯一;
2)MQ生成,具备业务无关性,对消息发送方和消息接收方屏蔽
有了这个inner-msg-id,就能保证上半场重发,也只有1条消息落到MQ-server的DB中,实现上半场幂等。
3.3 下半场的幂等性设计
MQ消息发送下半场,即上图中的步骤4-6
4,服务端MQ-server将消息发给接收端MQ-client;
5,接收端MQ-client回ACK给服务端;
6,服务端MQ-server将落地消息删除
需要强调的是,接收端MQ-client回ACK给服务端MQ-server,是消息消费业务方的主动调用行为,不能由MQ-client自动发起,因为MQ系统不知道消费方什么时候真正消费成功。
如果5丢失,服务端MQ-server超时后会重发消息,可能导致MQ-client收到重复的消息。此时重发是MQ-server发起的,消息的处理是消息消费业务方,消息重发势必导致业务方重复消费。为了保证业务幂等性,业务消息体中,必须有一个biz-id,作为去重和幂等的依据,这个业务ID的特性是:
(1)对于同一个业务场景,全局唯一
(2)由业务消息发送方生成,业务相关,对MQ透明
(3)由业务消息消费方负责判重,以保证幂等
有了这个业务ID,才能够保证下半场消息消费业务方即使收到重复消息,也只有1条消息被消费,保证了幂等。
3.4 总结
MQ为了保证消息必达,消息上下半场均可能发送重复消息,如何保证消息的幂等性呢?
上半场
MQ-client生成inner-msg-id,保证上半场幂等。
这个ID全局唯一,业务无关,由MQ保证。
下半场
业务发送方带入biz-id,业务接收方去重保证幂等。
这个ID对单业务唯一,业务相关,对MQ透明。
结论:幂等性,不仅对MQ有要求,对业务上下游也有要求。
4. MQ如何实现消息延迟
4.1 缘起
很多时候,业务有“在一段时间之后,完成一个工作任务”的需求。例如:滴滴打车订单完成后,如果用户一直不评价,48小时后会将自动评价为5星。一般来说怎么实现这类“48小时后自动评价为5星”需求呢?常见方案:启动一个cron定时任务,每小时跑一次,将完成时间超过48小时的订单取出,置为5星,并把评价状态置为已评价。
假设订单表的结构为:t_order(oid, finish_time, stars, status, …),更具体的,定时任务每隔一个小时会这么做一次:
select oid from t_order where finish_time > 48hours and status=0;
update t_order set stars=5 and status=1 where oid in[…];
如果数据量很大,需要分页查询,分页update,这将会是一个for循环。方案的不足:
(1)轮询效率比较低
(2)每次扫库,已经被执行过记录,仍然会被扫描(只是不会出现在结果集中),有重复计算的嫌疑
(3)时效性不够好,如果每小时轮询一次,最差的情况下,时间误差会达到1小时
(4)如果通过增加cron轮询频率来减少(3)中的时间误差,(1)中轮询低效和(2)中重复计算的问题会进一步凸显
4.2 高效延时消息设计与实现
高效延时消息,包含两个重要的数据结构:
(1)环形队列,例如可以创建一个包含3600个slot的环形队列(本质是个数组)
(2)任务集合,环上每一个slot是一个Set
同时,启动一个timer,这个timer每隔1s,在上述环形队列中移动一格,有一个Current Index指针来标识正在检测的slot。
Task结构中有两个很重要的属性:
(1)Cycle-Num:当Current Index第几圈扫描到这个Slot时,执行任务
(2)Task-Function:需要执行的任务指针

假设当前Current Index指向第一格,当有延时消息到达之后,例如希望3610秒之后,触发一个延时消息任务,只需:
(1)计算这个Task应该放在哪一个slot,现在指向1,3610秒之后,应该是第11格,所以这个Task应该放在第11个slot的Set中
(2)计算这个Task的Cycle-Num,由于环形队列是3600格(每秒移动一格,正好1小时),这个任务是3610秒后执行,所以应该绕3610/3600=1圈之后再执行,于是Cycle-Num=1
Current Index不停的移动,每秒移动到一个新slot,这个slot中对应的Set,每个Task看Cycle-Num是不是0:
(1)如果不是0,说明还需要多移动几圈,将Cycle-Num减1
(2)如果是0,说明马上要执行这个Task了,取出Task-Funciton执行(可以用单独的线程来执行Task),并把这个Task从Set中删除
使用了“延时消息”方案之后,“订单48小时后关闭评价”的需求,只需将在订单关闭时,触发一个48小时之后的延时消息即可:
(1)无需再轮询全部订单,效率高
(2)一个订单,任务只执行一次
(3)时效性好,精确到秒(控制timer移动频率可以控制精度)
4.3 总结
环形队列是一个实现“延时消息”的好方法,开源的MQ好像都不支持延迟消息,不妨自己实现一个简易的“延时消息队列”,能解决很多业务问题,并减少很多低效扫库的cron任务。
5.MQ如何实现削峰填谷
5.1 站点与服务、服务与服务上下游之间,一般如何通讯?
一种是“直接调用”,通过RPC框架,上游直接调用下游;另一种是采用“MQ推送”,上游将消息发给MQ,MQ将消息推送给下游。
5.2 为什么会有流量冲击?
不管采用“直接调用”还是“MQ推送”,都有一个缺点,下游消息接收方无法控制到达自己的流量,如果调用方不限速,很有可能把下游压垮。假如,上游下单业务简单,每秒发起了10000个请求,下游秒杀业务复杂,每秒只能处理2000个请求,很有可能导致下游系统被压垮,引发雪崩。
为了避免雪崩,常见的优化方案有两种:1)业务上游队列缓冲,限速发送;2)业务下游队列缓冲,限速执行。
5.3 MQ怎么改能缓冲流量?
由MQ-server推模式,升级为MQ-client拉模式。MQ-client根据自己的处理能力,每隔一定时间,或者每次拉取若干条消息,实施流控,达到保护自身的效果。并且这是MQ提供的通用功能,无需上下游修改代码。
5.4 如果上游发送流量过大,会不会导致消息在MQ中堆积?
下游MQ-client拉取消息,消息接收方能够批量获取消息,需要下游消息接收方进行优化,方能够提升整体吞吐量,例如:批量写。
5.4 结论
1)MQ-client提供拉模式,定时或者批量拉取,可以起到削平流量,下游自我保护的作用(MQ需要做的)
2)要想提升整体吞吐量,需要下游优化,例如批量处理等方式(消息接收方需要做的)
注意:本文归作者所有,未经作者允许,不得转载

