Apache Geode 简介
Apache Geode 是一个数据管理平台,提供实时的、一致的、贯穿整个云架构的访问数据关键型应用,具有高并发处理能力
Geode 池化了服务器上的内存、CPU、 网络资源和系统的本地磁盘,并且跨了多个进程来管理应用的对象和行为。它使用了动态数据复制和分区技术来实现高性能、 高可扩展性、高可用和高容错行。另外, 对于一个分布式数据容器,Apache Geode 是一个基于内存的数据管理系统。提供了可靠的异步事件通知和可靠的消息投递。
1.10.0新特性
显著提高了连接池的性能,同时减少了套接字资源的数量。
现在可以通过千分尺(micrometer)获得更多统计信息。
使用 NIO 改善对等 SSL 连接的可伸缩性。
启用实验性集群管理 API。
Tab 补全现在可以在 gfsh 帮助下使用。
引入了使用替代日志记录方案替换 Log4j 的功能。要使用替代的附加程序来写入日志文件,请从类路径中排除“log4j-core”。
添加了指定在首次启动异步事件队列(AEQ)时应暂停事件处理的功能。提供了“恢复”命令以在所需时间开始事件处理。添加或修改了三个 gfsh 命令以支持此功能:“create async-event-queue --pause-event-processing”,“alter async-event-queue --pause-event-processing”和“resume async-event-queue-dispatcher”。

更多更新内容:https://cwiki.apache.org/confluence/display/GEODE/Release+Notes#ReleaseNotes-1.10.0
Geode主要概念和模块
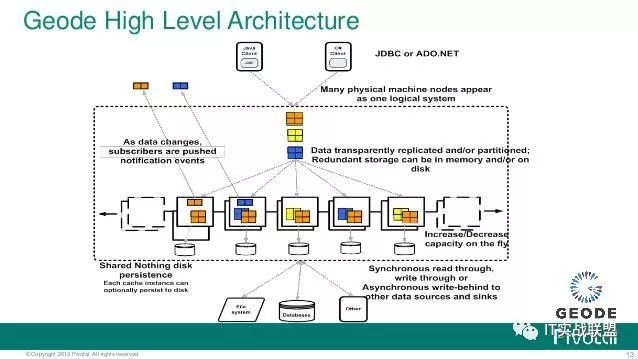
缓存 是一个抽象的概念, 在一个 Geode 分布式系统中用于描述一个节点.
在每个缓存中, 你定义数据 regions. 数据 regions 类似于传统关系型数据库中的'表'的概念, 以分布式的方式来管理数据 , 表现为名/值对儿形式. 在分布式系统的每个缓存成员中, 一个 复制 region 保存数据的拷贝. 一个 分区 region 跨缓存成员来同步数据. 在系统配置后, 客户端应用能够访问regions 中的分布式数据, 而不需要知道系统整体架构的知识. 你能够定义监听器来接收通知, 当数据发生变化时, 同时你也能够定义超时标准来删除在一个 region 中的废弃掉的数据.
Locators 提供了发现和负载均衡服务. 你配置带有 locator 服务列表的客户端, 同时 locators 维护一个成员服务器的动态列表. 默认情况下, Geode 客户端和服务器使用端口 40404 和多播来互相发现.
Geode 包含了如下的特性:
结合冗余, 复制, 和 "shared nothing" 的一致性架构来交付 '自动防故障' 的可靠性和高性能。
水平扩展到数千个缓存成员, 具有多种缓存拓扑结构来满足不同的企业级部署需求. 缓存能够跨多台机器进行分布。
异步和同步缓存更新传播。
Delta 传播只分发新版本和旧版本的变化量 (delta) , 而不是整个对象, 从而可以节省大量的网络开销。
通过经过优化的, 低延时的通信层进行可靠的异步事件通知, 高保障的消息投递。
在没有额外硬件的辅助下, 应用可以加速4 到 40,000 倍。
数据感知和实时BI. 当你查询时, 如果数据变化了, 你能够立刻在系统中看见数据的变化。
集成 Spring 框架来加速和简化高可扩展、高并发和事务型企业级应用的开发复杂度。
JTA 兼容的事务支持。
集群的配置可以写到文件中和导出到其他集群中。
通过HTTP做 远程集群管理。
基于REST应用开发的REST APIs。
滚动升级是可行的, 但是需要服从新特性的限制问题。
背景
Apache Geode 是一个相当成熟, 强健的技术, 最初由GemStone Systems 公司开发(位于美国俄勒冈州的比弗顿市). 商标为 GemFire™, 此项技术初期被广泛应用在金融领域, 用于华尔街交易平台,作为事务性, 低延时的数据引擎. 那么今天Apache Geode 有超过600家大中型企业级用户, 主要是必须满足低延时和24x7 高可靠要求的,高可扩展的关键业务应用系统。
此工程目前在ASF下正处于孵化阶段, 通过孵化器来提供赞助. 孵化对于所有新加入的工程很重要,直到基础设施, 通信, 决策流程足够稳定,和其他成功的 ASF工程一致. 当孵化器状态完成或代码稳定时, 它提示此工程完全由 ASF 承认。
据说以前12306用的就是Apache Geode的商业版。
注意:本文归作者所有,未经作者允许,不得转载

