背景
在微服务架构中,一个大系统被拆分成多个小服务,小服务之间大量 RPC 调用,经常可能因为网络抖动等原因导致 RPC 调用失败,这时候使用重试机制可以提高请求的最终成功率,减少故障影响,让系统运行更稳定。
重试的风险
重试能够提高服务稳定性,但是一般情况下大家都不会轻易去重试,或者说不敢重试,主要是因为重试有放大故障的风险。
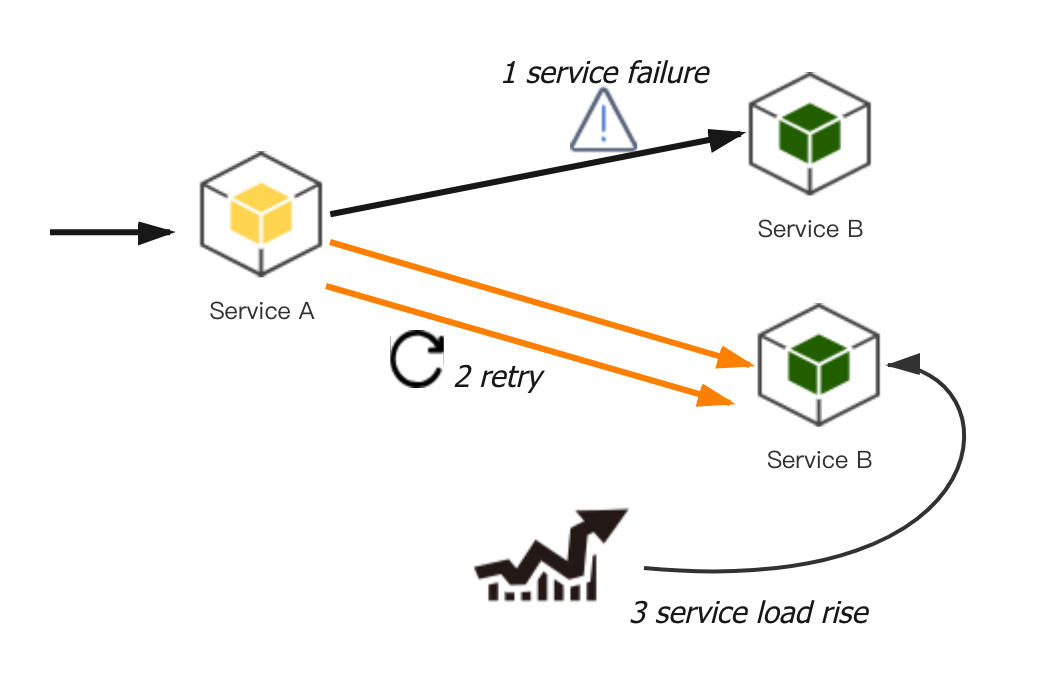
首先,重试会加大直接下游的负载。如下图,假设 A 服务调用 B 服务,重试次数设置为 r(包括首次请求),当 B 高负载时很可能调用不成功,这时 A 调用失败重试 B ,B 服务的被调用量快速增大,最坏情况下可能放大到 r 倍,不仅不能请求成功,还可能导致 B 的负载继续升高,甚至直接打挂。
更可怕的是,重试还会存在链路放大的效应,结合下图说明一下:
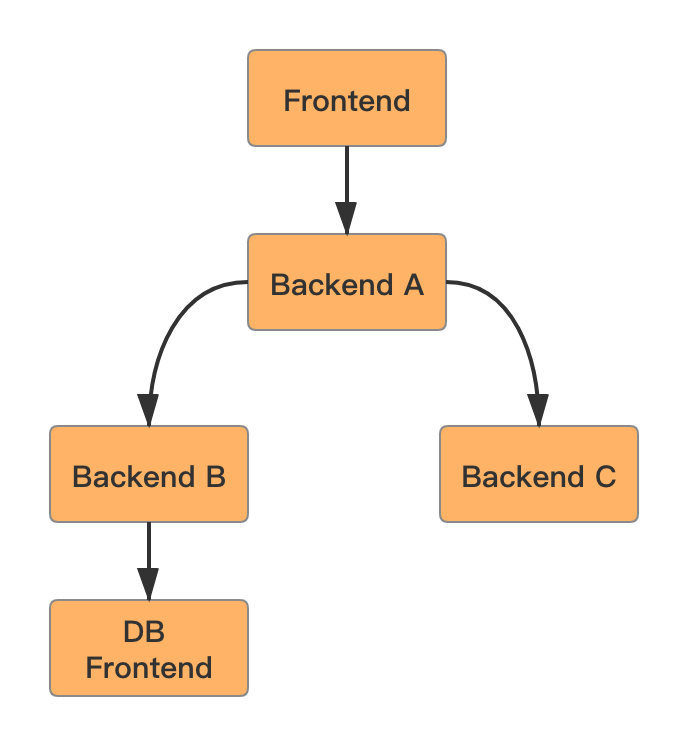
假设现在场景是 Backend A 调用 Backend B,Backend B 调用 DB Frontend,均设置重试次数为 3 。如果 Backend B 调用 DB Frontend,请求 3 次都失败了,这时 Backend B 会给 Backend A 返回失败。但是 Backend A 也有重试的逻辑,Backend A 重试 Backend B 三次,每一次 Backend B 都会请求 DB Frontend 3 次,这样算起来,DB Frontend 就会被请求了 9 次,实际是指数级扩大。假设正常访问量是 n,链路一共有 m 层,每层重试次数为 r,则最后一层受到的访问量最大,为 n * r ^ (m - 1) 。这种指数放大的效应很可怕,可能导致链路上多层都被打挂,整个系统雪崩。
重试的使用成本
另外使用重试的成本也比较高。之前在字节跳动的内部框架和服务治理平台中都没有支持重试,在一些很需要重试的业务场景下(比如调用一些第三方业务经常失败),业务方可能用简单 for 循环来实现,基本不会考虑重试的放大效应,这样很不安全,公司内部出现过多次因为重试而导致的事故,且出事故的时候还需要修改代码上线才能关闭重试,导致事故恢复也不迅速。
另外也有一些业务使用开源的重试组件,这些组件通常会考虑对直接下游的保护,但不会考虑链路级别的重试放大,另外需要业务方修改 RPC 调用代码才能使用,对业务代码入侵较多,而且也是静态配置,需要修改配置时都必须重新上线。
基于以上的背景,为了让业务方能够灵活安全的使用重试,我们字节跳动直播中台团队设计和实现了一个重试治理组件,具有以下优点:
- 能够在链路级别防重试风暴。
- 保证易用性,业务接入成本小。
- 具有灵活性,能够动态调整配置。
下面介绍具体的实现方案。
重试治理
动态配置
如何让业务方简单接入是首先要解决的问题。如果还是普通组件库的方式,依旧免不了要大量入侵用户代码,且很难动态调整。
字节跳动的 Golang 开发框架支持中间件 (Milddleware) 模式,可以注册多个自定义 Middleware 并依次递归调用,通常是用于完成打印日志、上报监控等非业务逻辑,能够有效将业务和非业务代码功能进行解耦。因此我们决定使用 Middleware 的方式来实现重试功能,定义一个 Middleware 并在内部实现对 RPC 的重复调用,把重试的配置信息用字节跳动的分布式配置存储中心存储,这样 Middleware 中能够读取配置中心的配置并进行重试,对用户来说不需要修改调用 RPC 的代码,而只需要在服务中引入一个全局的 Middleware 即可。
如下面的整体架构图所示,我们提供配置的网页和后台,用户能够在专门进行服务治理的页面上很方便的对 RPC 进行配置修改并自动生效,内部的实现逻辑对用户透明,对业务代码无入侵。
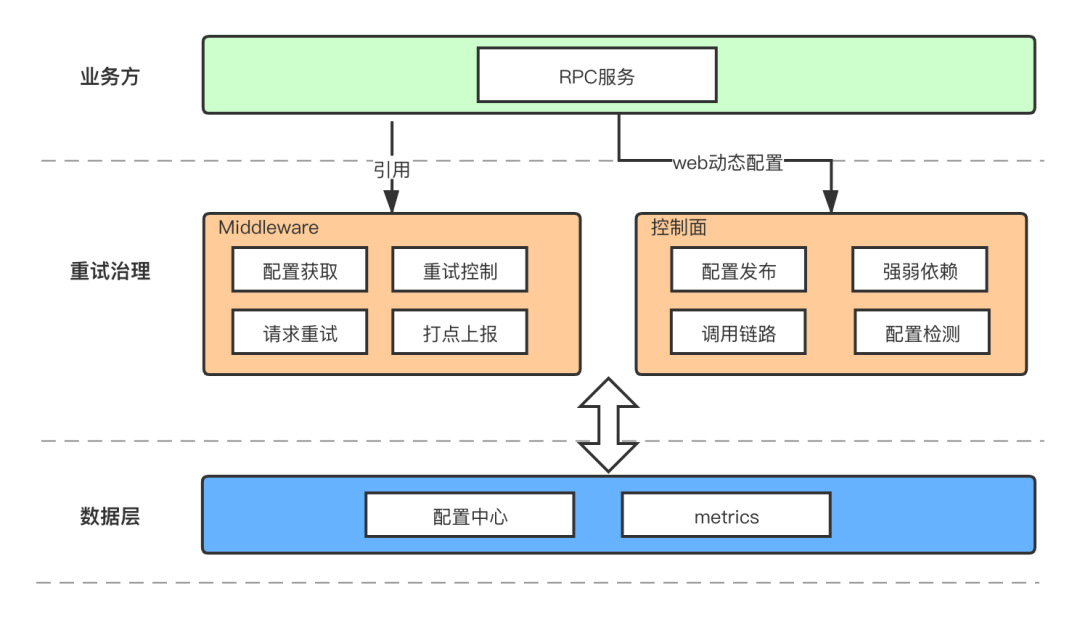
配置的维度按照字节跳动的 RPC 调用特点,选定 [调用方服务,调用方集群,被调用服务, 被调用方法] 为一个元组,按照元组来进行配置。Middleware 中封装了读取配置的方法,在 RPC 调用的时候会自动读取并生效。
这种 Middleware 的方式能够让业务方很容易接入,相对于之前普通组件库的方式要方便很多,并且一次接入以后就具有动态配置的能力,可能很方便地调整或者关闭重试配置。
退避策略
确定了接入方式以后就可以开始实现重试组件的具体功能,一个重试组件所包含的基本功能中,除了重试次数和总延时这样的基础配置外,还需要有退避策略。
对于一些暂时性的错误,如网络抖动等,可能立即重试还是会失败,通常等待一小会儿再重试的话成功率会较高,并且也可能打散上游重试的时间,较少因为同时都重试而导致的下游瞬间流量高峰。决定等待多久之后再重试的方法叫做退避策略,我们实现了常见的退避策略,如:
- 线性退避:每次等待固定时间后重试。
- 随机退避:在一定范围内随机等待一个时间后重试。
- 指数退避:连续重试时,每次等待时间都是前一次的倍数。
防止 retry storm
如何安全重试,防止 retry storm 是我们面临的最大的难题。
限制单点重试
首先要在单点进行限制,一个服务不能不受限制的重试下游,很容易造成下游被打挂。除了限制用户设定的重试次数上限外,更重要的是限制重试请求的成功率。
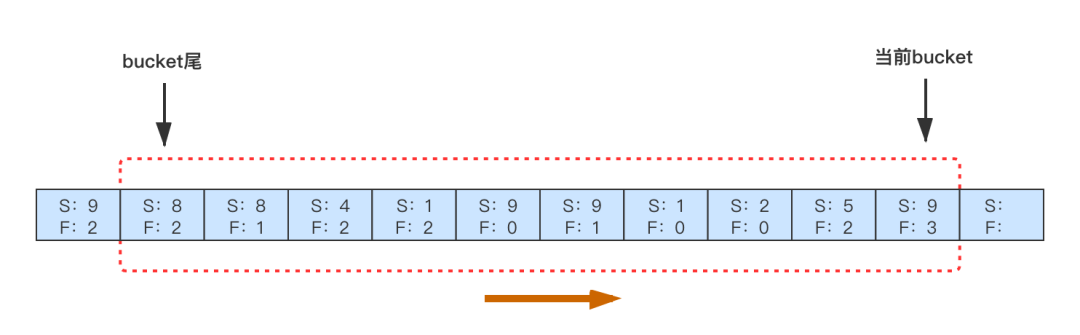
实现的方案很简单,基于断路器的思想,限制 请求失败/请求成功 的比率,给重试增加熔断功能。我们采用了常见的滑动窗口的方法来实现,如下图,内存中为每一类 RPC 调用维护一个滑动窗口,比如窗口分 10 个 bucket ,每个 bucket 里面记录了 1s 内 RPC 的请求结果数据(成功、失败)。新的一秒到来时,生成新的 bucket ,并淘汰最早的一个 bucket ,只维持 10s 的数据。在新请求这个 RPC 失败时,根据前 10s 内的 失败/成功 是否超过阈值来判断是否可以重试。默认阈值是 0.1 ,即下游最多承受 1.1 倍的 QPS ,用户可以根据需要自行调整熔断开关和阈值。
限制链路重试
前面说过在多级链路中如果每层都配置重试可能导致调用量指数级扩大,虽然有了重试熔断之后,重试不再是指数增长(每一单节点重试扩大限制了 1.1 倍),但还是会随着链路的级数增长而扩大调用次数,因此还是需要从链路层面来考虑重试的安全性。
链路层面的防重试风暴的核心是限制每层都发生重试,理想情况下只有最下一层发生重试。Google SRE 中指出了 Google 内部使用特殊错误码的方式来实现:
- 统一约定一个特殊的 status code ,它表示:调用失败,但别重试。
- 任何一级重试失败后,生成该 status code 并返回给上层。
- 上层收到该 status code 后停止对这个下游的重试,并将错误码再传给自己的上层。
这种方式理想情况下只有最下一层发生重试,它的上游收到错误码后都不会重试,链路整体放大倍数也就是 r 倍(单层的重试次数)。但是这种策略依赖于业务方传递错误码,对业务代码有一定入侵,而且通常业务方的代码差异很大,调用 RPC 的方式和场景也各不相同,需要业务方配合进行大量改造,很可能因为漏改等原因导致没有把从下游拿到的错误码传递给上游。
好在字节跳动内部用的 RPC 协议中有扩展字段,我们在 Middleware 中做了很多尝试,封装了错误码处理和传递的逻辑,在 RPC 的 Response 扩展字段中传递错误码标识 nomore_retry ,它告诉上游不要再重试了。Middleware 完成错误码的生成、识别、传递等整个生命周期的管理,不需要业务方修改本身的 RPC 逻辑,错误码的方案对业务来说是透明的。
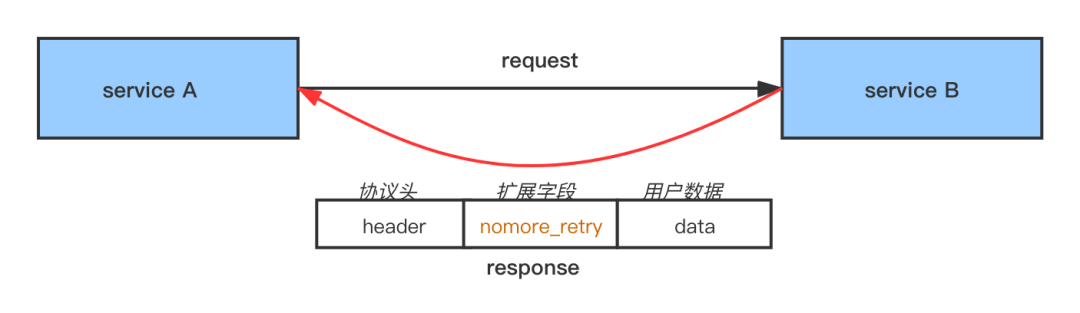
在链路中,推进每层都接入重试组件,这样每一层都可以通过识别这个标志位来停止重试,并逐层往上传递,上层也都停止重试,做到链路层面的防护,达到“只有最靠近错误发生的那一层才重试”的效果。
超时处理
在测试错误码上传的方案时,我们发现超时的情况可能导致传递错误码的方案失效。
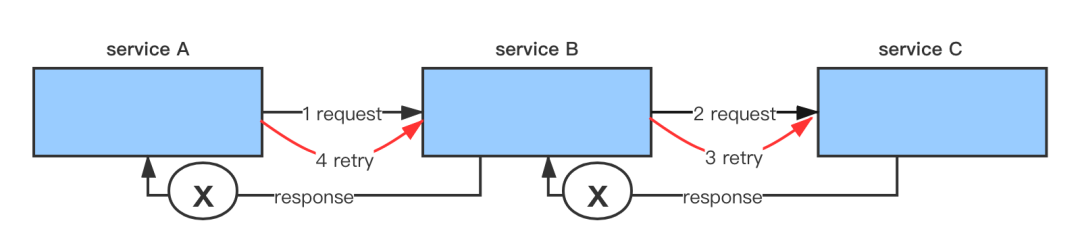
对于 A -> B -> C 的场景,假设 B -> C 超时,B 重试请求 C ,这时候很可能 A -> B 也超时了,所以 A 没有拿到 B 返回的错误码,而是也会重试 B , 这个时候虽然 B 重试 C 且生成了重试失败的错误码,但是却不能再传递给 A 。这种情况下,A 还是会重试 B ,如果链路中每一层都超时,那么还是会出现链路指数扩大的效应。
因此为了处理这种情况,除了下游传递重试错误标志以外,我们还实现了“对重试请求不重试”的方案。
对于重试的请求,我们在 Request 中打上一个特殊的 retry flag ,在上面 A -> B -> C 的链路,当 B 收到 A 的请求时会先读取这个 flag 判断这个请求是不是重试请求,如果是,那它调用 C 即使失败也不会重试;否则调用 C 失败后会重试 C 。同时 B 也会把这个 retry flag 下传,它发出的请求也会有这个标志,它的下游也不会再对这个请求重试。
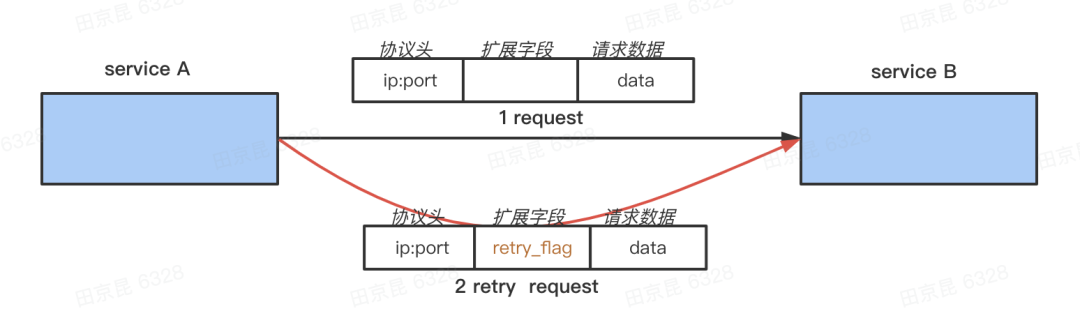
这样即使 A 因为超时而拿不到 B 的返回,对 B 发出重试请求后,B 能感知到并且不会对 C 重试,这样 A 最多请求 r 次,B 最多请求 r + r - 1,如果后面还有更下层次的话,C 最多请求 r + r + r - 2 次, 第 i 层最多请求 i * r - (i-1) 次,最坏情况下是倍数增长,不是指数增长了。加上实际还有重试熔断的限制,增长的幅度要小很多。
通过重试熔断来限制单点的放大倍数,通过重试错误标志链路回传的方式来保证只有最下层发生重试,又通过重试请求 flag 链路下传的方式来保证对重试请求不重试,多种控制策略结合,可以有效地较少重试放大效应。
超时场景优化
分布式系统中,RPC 请求的结果有三种状态:成功、失败、超时,其中最难处理的就是超时的情况。但是超时往往又是最经常发生的那一个,我们统计了字节跳动直播业务线上一些重要服务的 RPC 错误分布,发现占比最高的就是超时错误,怕什么偏来什么。
在超时重试的场景中,虽然给重试请求添加 retry flag 能防止指数扩大,但是却不能提高请求成功率。如下图,假如 A 和 B 的超时时间都是 1000ms ,当 C 负载很高导致 B 访问 C 超时,这时 B 会重试 C ,但是时间已经超过了 1000ms ,时间 A 这里也超时了并且断开了和 B 的连接,所以 B 这次重试 C 不管是否成功都是无用功,从 A 的视角看,本次请求已经失败了。
这种情况的本质原因是因为链路上的超时时间设置得不合理,上游和下游的超时时间设置的一样,甚至上游的超时时间比下游还要短。在实际情况中业务一般都没有专门配置过 RPC 的超时时间,所以可能上下游都是默认的超时,时长是一样的。为了应对这种情况,我们需要有一个机制来优化超时情况下的稳定性,并减少无用的重试。
如下图,正常重试的场景是等拿到 Resp1 (或者拿到超时结果) 后再发起第二次请求,整体耗时是 t1 + t2 。我们分析下,service A 在发出去 Req1 之后可能等待很长的时间,比如 1s ,但是这个请求的 pct99 或者 pct999 可能通常只有 100ms 以内,如果超过了 100ms ,有很大概率是这次访问最终会超时,能不能不要傻等,而是提前重试呢?
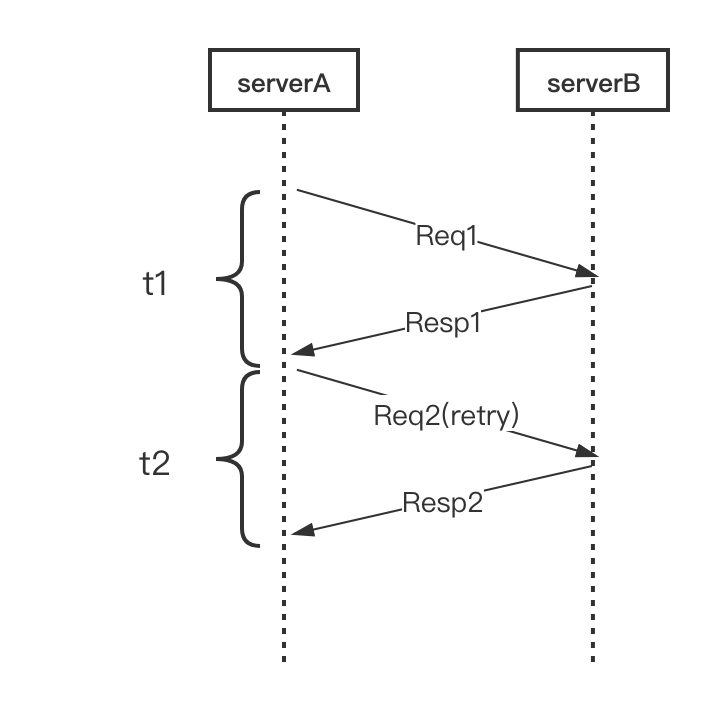
基于这种思想,我们引入并实现了 Backup Requests 的方案。如下图,我们预先设定一个阈值 t3(比超时时间小,通常建议是 RPC 请求延时的 pct99 ),当 Req1 发出去后超过 t3 时间都没有返回,那我们直接发起重试请求 Req2 ,这样相当于同时有两个请求运行。然后等待请求返回,只要 Resp1 或者 Resp2 任意一个返回成功的结果,就可以立即结束这次请求,这样整体的耗时就是 t4 ,它表示从第一个请求发出到第一个成功结果返回之间的时间,相比于等待超时后再发出请求,这种机制能大大减少整体延时。
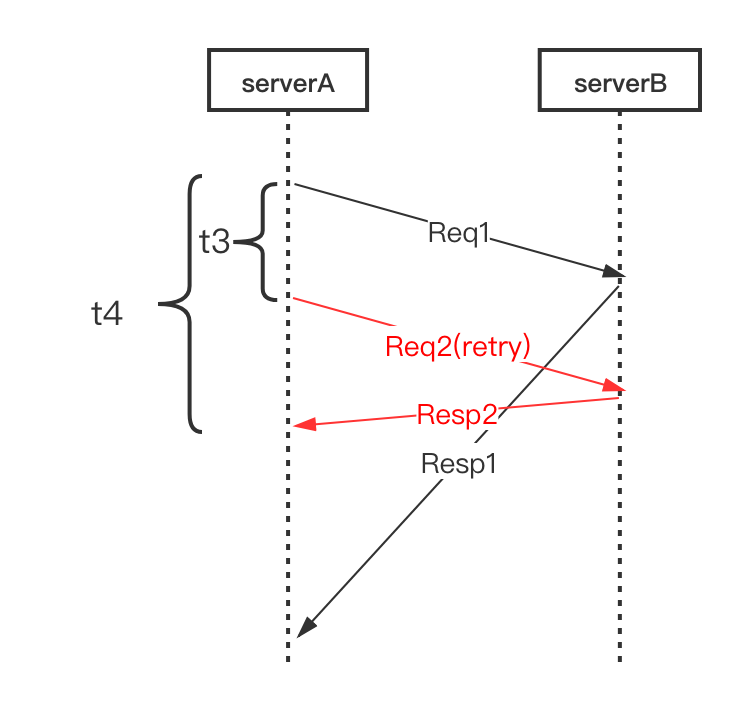
实际上 Backup Requests 是一种用访问量来换成功率 (或者说低延时) 的思想,当然我们会控制它的访问量增大比率,在发起重试之前,会为第一次的请求记录一次失败,并检查当前失败率是否超过了熔断阈值,这样整体的访问比率还是会在控制之内。
结合 DDL
Backup Requests 的思路能在缩短整体请求延时的同时减少一部分的无效请求,但不是所有业务场景下都适合配置 Backup Requests ,因此我们又结合了 DDL 来控制无效重试。
DDL 是“ Deadline Request 调用链超时”的简称,我们知道 TCP/IP 协议中的 TTL 用于判断数据包在网络中的时间是否太长而应被丢弃,DDL 与之类似,它是一种全链路式的调用超时,可以用来判断当前的 RPC 请求是否还需要继续下去。如下图,字节跳动的基础团队已经实现了 DDL 功能,在 RPC 请求调用链中会带上超时时间,并且每经过一层就减去该层处理的时间,如果剩下的时间已经小于等于 0 ,则可以不需要再请求下游,直接返回失败即可。
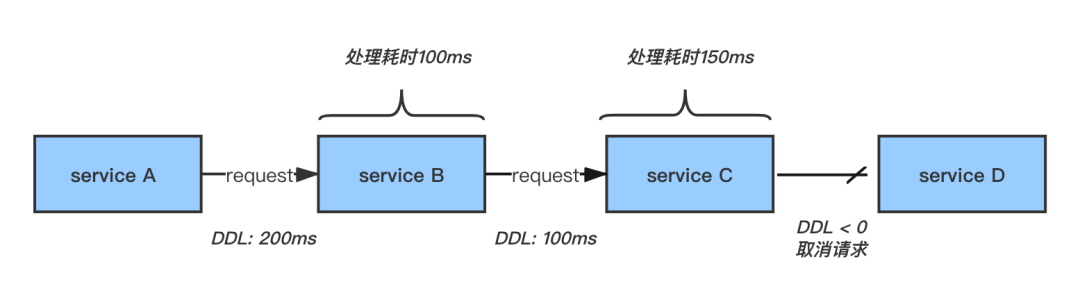
DDL 的方式能有效减少对下游的无效调用,我们在重试治理中也结合了 DDL 的数据,在每一次发起重试前都会判断 DDL 的剩余值是否还大于 0 ,如果已经不满足条件了,那也就没必要对下游重试,这样能做到最大限度的减少无用的重试。
实际的链路放大效应
之前说的链路指数放大是理想情况下的分析,实际的情况要复杂很多,因为有很多影响因素:
策略说明重试熔断请求失败 / 成功 > 0.1 时停止重试链路上传错误标志下层重试失败后上传错误标志,上层不再重试链路下传重试标志重试请求特殊标记,下层对重试请求不会重试DDL当剩余时间不够时不再发起重试请求框架熔断微服务框架本身熔断、过载保护等机制也会影响重试效果
各种因素综合下来,最终实际方法情况不是一个简单的计算公式能说明,我们构造了多层调用链路,在线上实际测试和记录了在不同错误类型、不同错误率的情况下使用重试治理组件的效果,发现接入重试治理组件后能够在链路层面有效的控制重试放大倍数,大幅减少重试导致系统雪崩的概率。
总结
如上所述,基于服务治理的思想我们开发了重试治理的功能,支持动态配置,接入方式基本无需入侵业务代码,并使用多种策略结合的方式在链路层面控制重试放大效应,兼顾易用性、灵活性、安全性,在字节跳动内部已经有包括直播在内的很多服务接入使用并上线验证,对提高服务本身稳定性有良好的效果。目前方案已经被验证并在字节跳动直播等业务推广,后续将为更多的字节跳动业务服务。
注意:本文归作者所有,未经作者允许,不得转载

