前言
启动是 App 给用户的第一印象,启动越慢用户流失的概率就越高,良好的启动速度是用户体验不可缺少的一环。启动优化涉及到的知识点非常多面也很广,一篇文章难以包含全部,所以拆分成两部分:原理和实践。
本文从基础知识出发,先回顾一些核心概念,为后续章节做铺垫;接下来介绍 IPA 构建的基本流程,以及这个流程里可用于启动优化的点;最后大篇幅讲解 dyld3 的启动 pipeline,因为启动优化的重点还在运行时。
基本概念
启动的定义
启动有两种定义:
- 广义:点击图标到首页数据加载完毕
- 狭义:点击图标到 Launch Image 完全消失第一帧
不同产品的业务形态不一样,对于抖音来说,首页的数据加载完成就是视频的第一帧播放;对其他首页是静态的 App 来说,Launch Image 消失就是首页数据加载完成。由于标准很难对齐,所以我们一般使用狭义的启动定义:即启动终点为启动图完全消失的第一帧。
以抖音为例,用户感受到的启动时间:
Tips:启动最佳时间是 400ms 以内,因为启动动画时长是 400ms。
这是从用户感知维度定义启动,那么代码上如何定义启动呢?Apple 在 MetricKit 中给出了官方计算方式:
- 起点:进程创建的时间
- 终点:第一个CA::Transaction::commit()
Tips:CATransaction 是 Core Animation 提供的一种事务机制,把一组 UI 上的修改打包,一起发给 Render Server 渲染。
启动的种类
根据场景的不同,启动可以分为三种:冷启动,热启动和回前台。
- 冷启动:系统里没有任何进程的缓存信息,典型的是重启手机后直接启动 App
- 热启动:如果把 App 进程杀了,然后立刻重新启动,这次启动就是热启动,因为进程缓存还在
- 回前台:大多数时候不会被定义为启动,因为此时 App 仍然活着,只不过处于 suspended 状态
那么,线上用户的冷启动多还是热启动多呢?
答案是和产品形态有关系,打开频次越高,热启动比例就越高。
Mach-O
Mach-O 是 iOS 可执行文件的格式,典型的 Mach-O 是主二进制和动态库。Mach-O 可以分为三部分:
- Header
- Load Commands
- Data
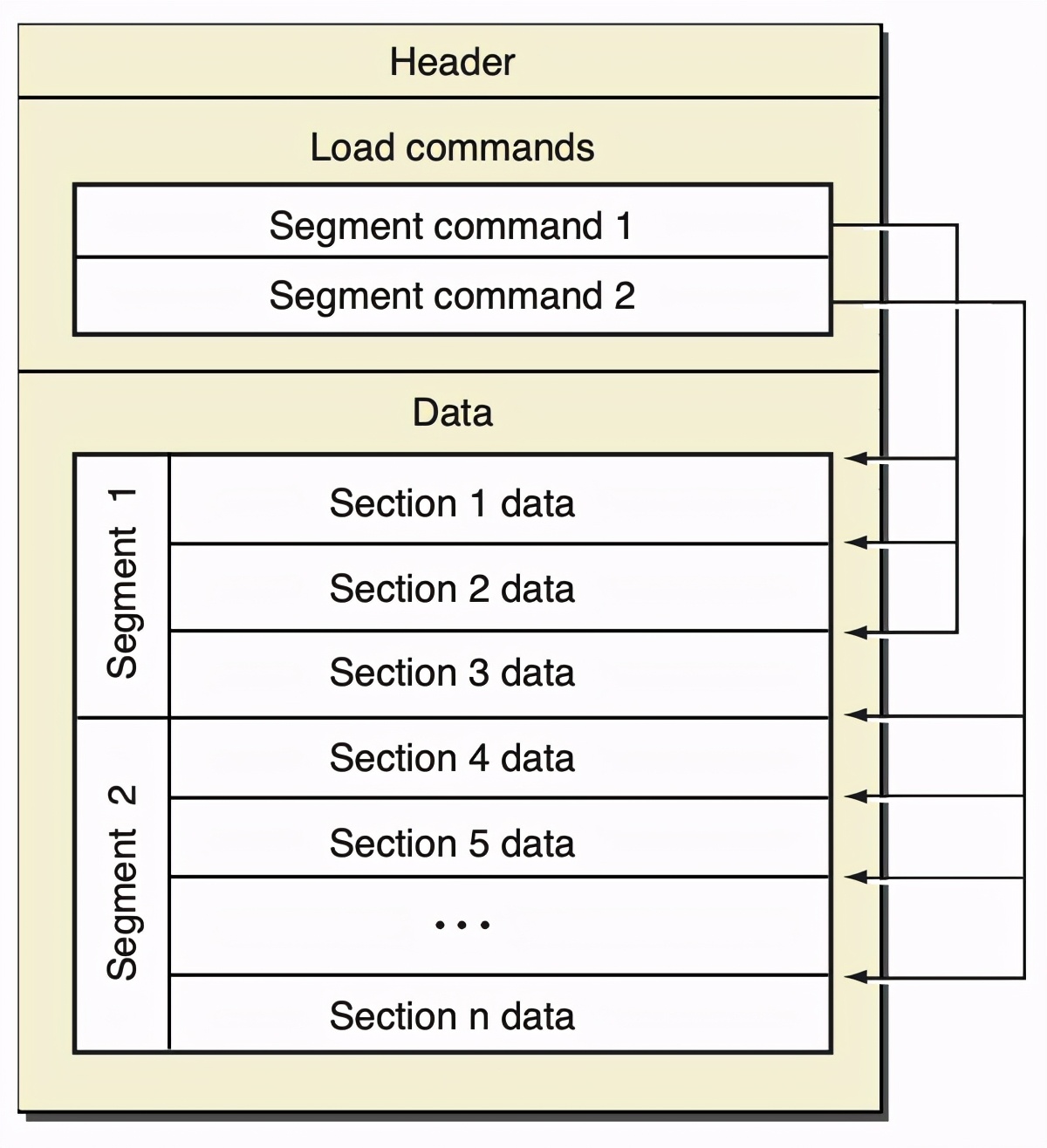
Header 的最开始是 Magic Number,表示这是一个 Mach-O 文件,除此之外还包含一些 Flags,这些 flags 会影响 Mach-O 的解析。
Load Commands 存储 Mach-O 的布局信息,比如 Segment command 和 Data 中的 Segment/Section 是一一对应的。除了布局信息之外,还包含了依赖的动态库等启动 App 需要的信息。
Data 部分包含了实际的代码和数据,Data 被分割成很多个 Segment,每个 Segment 又被划分成很多个 Section,分别存放不同类型的数据。
标准的三个 Segment 是 TEXT,DATA,LINKEDIT,也支持自定义:
- TEXT,代码段,只读可执行,存储函数的二进制代码(__text),常量字符串(__cstring),Objective C 的类/方法名等信息
- DATA,数据段,读写,存储 Objective C 的字符串(__cfstring),以及运行时的元数据:class/protocol/method…
- LINKEDIT,启动 App 需要的信息,如 bind & rebase 的地址,代码签名,符号表…
dyld
dyld 是启动的辅助程序,是 in-process 的,即启动的时候会把 dyld 加载到进程的地址空间里,然后把后续的启动过程交给 dyld。dyld 主要有两个版本:dyld2 和 dyld3。
dyld2 是从 iOS 3.1 引入,一直持续到 iOS 12。dyld2 有个比较大的优化是dyld shared cache,什么是 shared cache 呢?
- shared cache 就是把系统库(UIKit 等)合成一个大的文件,提高加载性能的缓存文件。
iOS 13 开始 Apple 对三方 App 启用了 dyld3,dyld3 的最重要的特性就是启动闭包,闭包里包含了启动所需要的缓存信息,从而提高启动速度。
虚拟内存
内存可以分为虚拟内存和物理内存,其中物理内存是实际占用的内存,虚拟内存是在物理内存之上建立的一层逻辑地址,保证内存访问安全的同时为应用提供了连续的地址空间。
物理内存和虚拟内存以页为单位映射,但这个映射关系不是一一对应的:一页物理内存可能对应多页虚拟内存;一页虚拟内存也可能不占用物理内存。
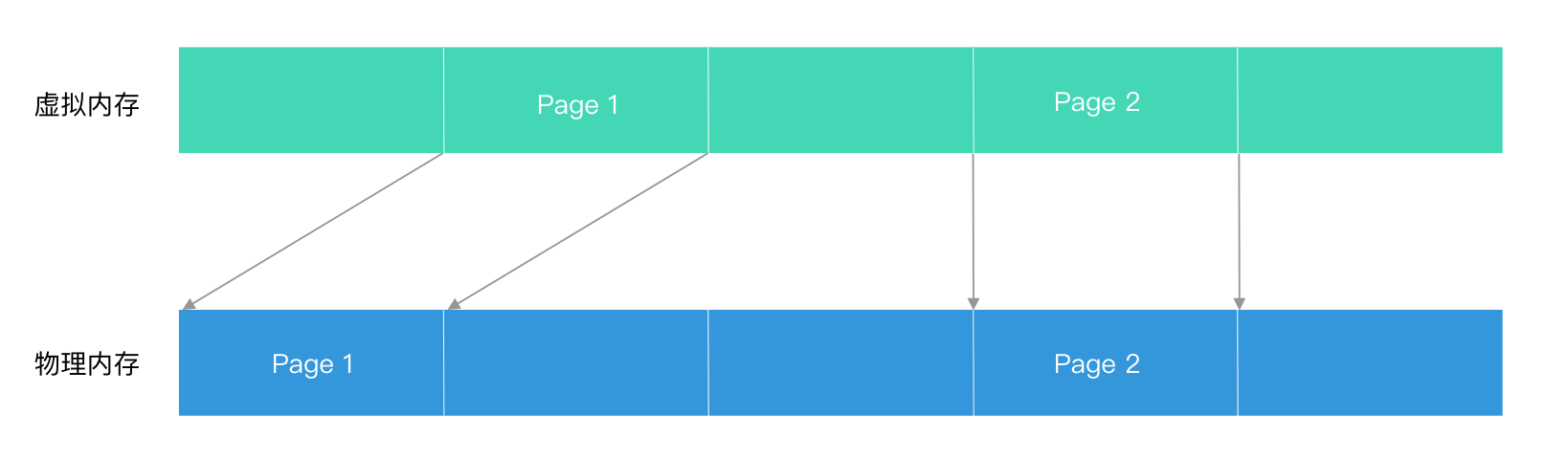
iPhone 6s 开始,物理内存的 Page 大小是 16K,6 和之前的设备都是 4K,这是 iPhone 6 相比 6s 启动速度断崖式下降的原因之一。
mmap
mmap 的全称是 memory map,是一种内存映射技术,可以把文件映射到虚拟内存的地址空间里,这样就可以像直接操作内存那样来读写文件。当读取虚拟内存,其对应的文件内容在物理内存中不存在的时候,会触发一个事件:File Backed Page In,把对应的文件内容读入物理内存。
启动的时候,Mach-O 就是通过 mmap 映射到虚拟内存里的(如下图)。下图中部分页被标记为 zero fill,是因为全局变量的初始值往往都是 0,那么这些 0 就没必要存储在二进制里,增加文件大小。操作系统会识别出这些页,在 Page In 之后对其置为 0,这个行为叫做 zero fill。
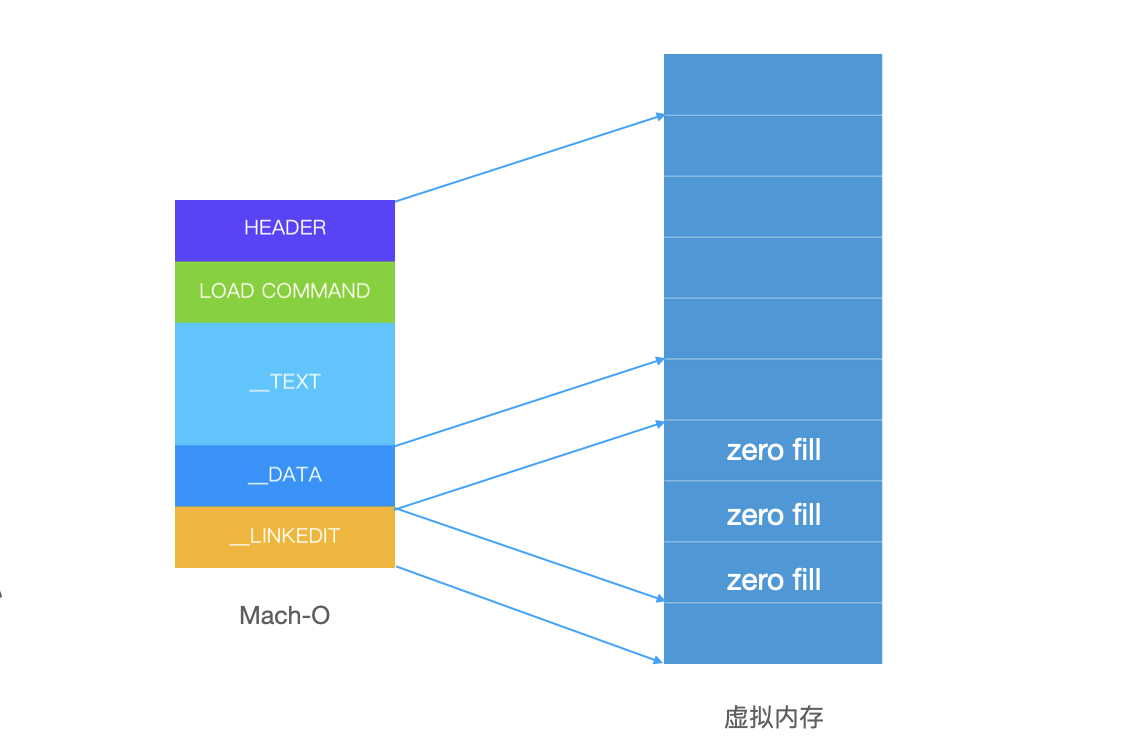
Page In
启动的路径上会触发很多次 Page In,其实也比较容易理解,因为启动的会读写二进制中的很多内容。Page In 会占去启动耗时的很大一部分,我们来看看单个 Page In 的过程:
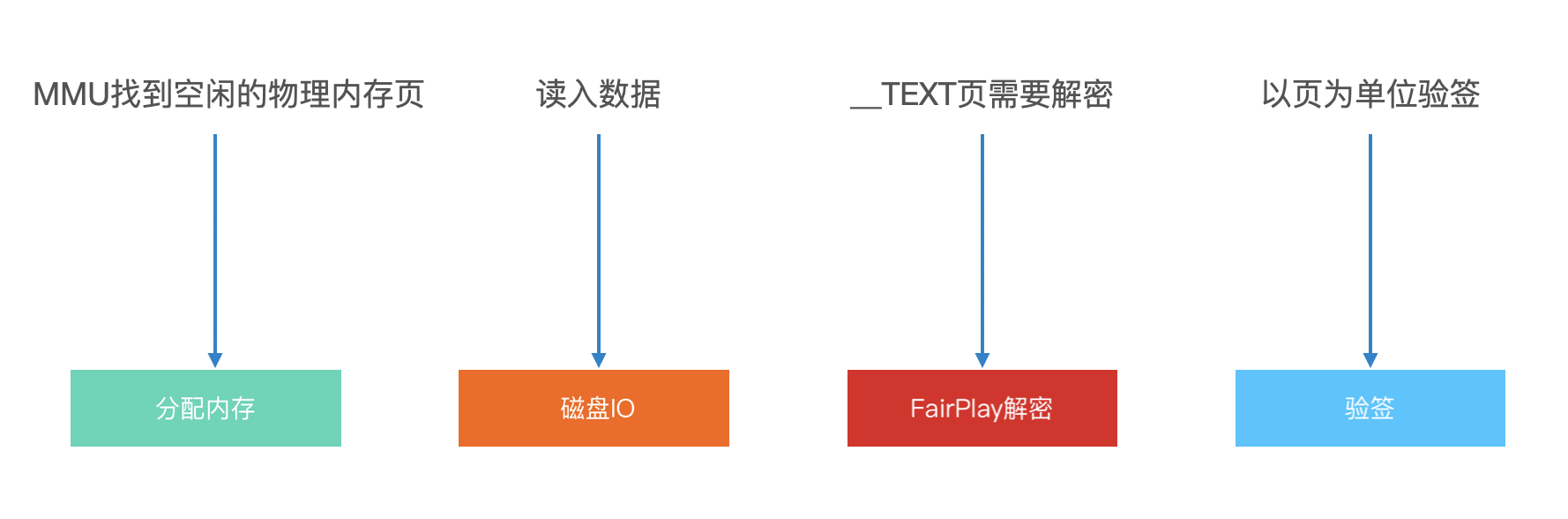
- MMU 找到空闲的物理内存页面
- 触发磁盘 IO,把数据读入物理内存
- 如果是 TEXT 段的页,要进行解密
- 对解密后的页,进行签名验证
其中解密是大头,IO 其次。
为什么要解密呢?因为 iTunes Connect 会对上传 Mach-O 的 TEXT 段进行加密,防止 IPA 下载下来就直接可以看到代码。这也就是为什么逆向里会有个概念叫做“砸壳”,砸的就是这一层 TEXT 段加密。iOS 13 对这个过程进行了优化,Page In 的时候不需要解密了。
二进制重排
既然 Page In 耗时,有没有什么办法优化呢?启动具有局部性特征,即只有少部分函数在启动的时候用到,这些函数在二进制中的分布是零散的,所以 Page In 读入的数据利用率并不高。如果我们可以把启动用到的函数排列到二进制的连续区间,那么就可以减少 Page In 的次数,从而优化启动时间:
以下图为例,方法 1 和方法 3 是启动的时候用到的,为了执行对应的代码,就需要两次 Page In。假如我们把方法 1 和 3 排列到一起,那么只需要一次 Page In,从而提升启动速度。
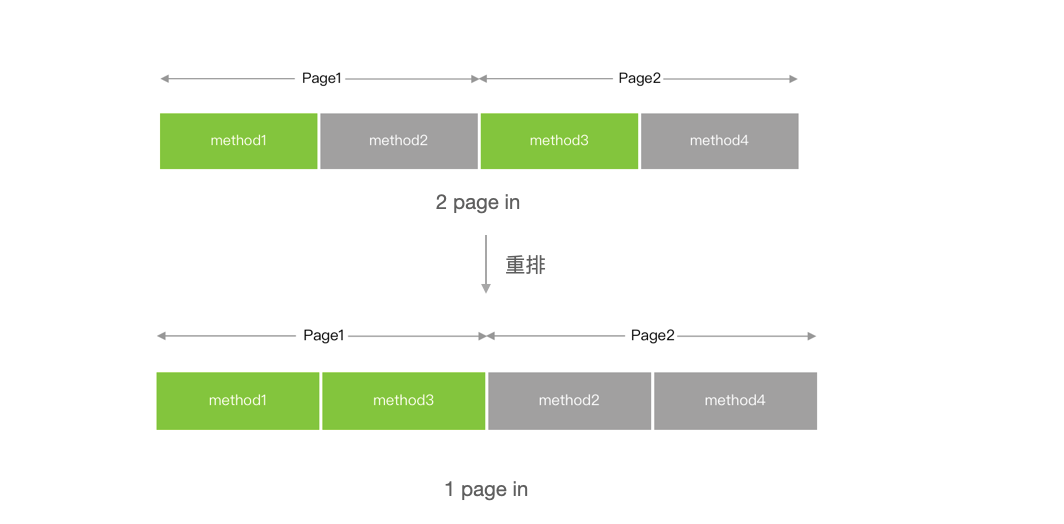
链接器 ld 有个参数-order_file 支持按照符号的方式排列二进制。获取启动时候用到的符号的有很多种方式,感兴趣的同学可以看看抖音之前的文章:基于二进制文件重排的解决方案 APP 启动速度提升超 15%。
IPA 构建
pipeline
既然要构建,那么必然会有一些地方去定义如何构建,对应 Xcode 中的两个配置项:
- Build Phase:以 Target 为维度定义了构建的流程。可以在 Build Phase 中插入脚本,来做一些定制化的构建,比如 CocoaPod 的拷贝资源就是通过脚本的方式完成的。
- Build Settings:配置编译和链接相关的参数。特别要提到的是 other link flags 和 other c flags,因为编译和链接的参数非常多,有些需要手动在这里配置。很多项目用的 CocoaPod 做的组件化,这时候编译选项在对应的.xcconfig 文件里。
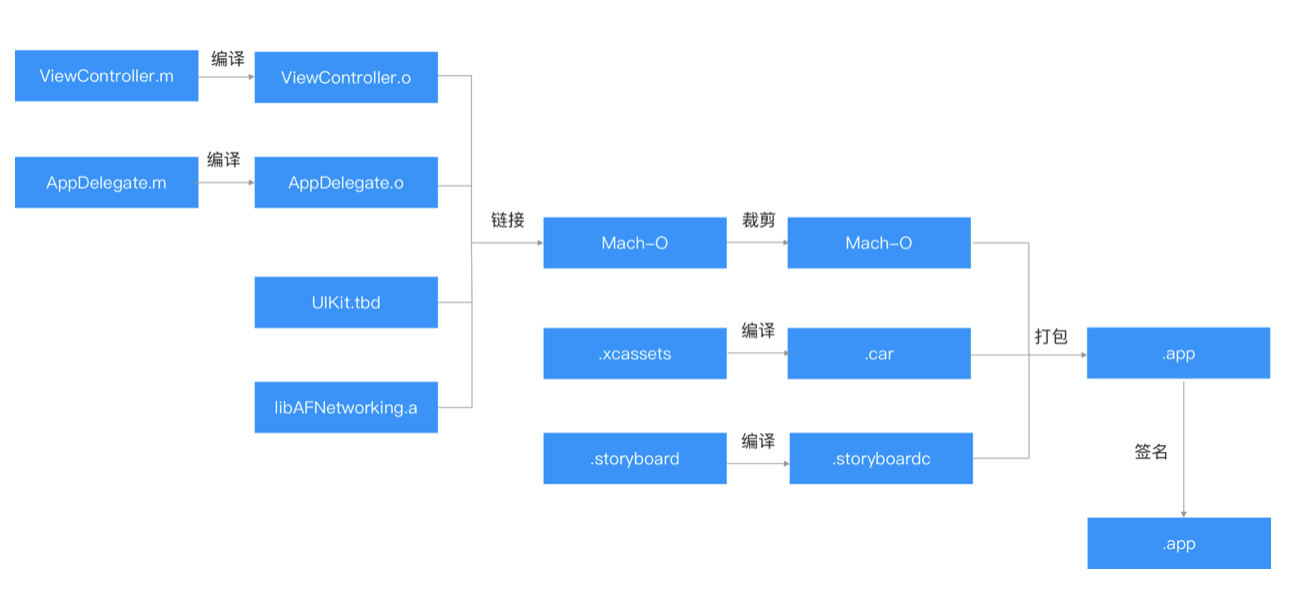
以单 Target 为例,我们来看下构建流程:
- 源文件(.m/.c/.swift 等)是单独编译的,输出对应的目标文件(.o)
- 目标文件和静态库/动态库一起,链接出最后的 Mach-O
- Mach-O 会被裁剪,去掉一些不必要的信息
- 资源文件如 storyboard,asset 也会编译,编译后加载速度会变快
- Mach-O 和资源文件一起,打包出最后的.app
- 对.app 签名,防篡改
编译
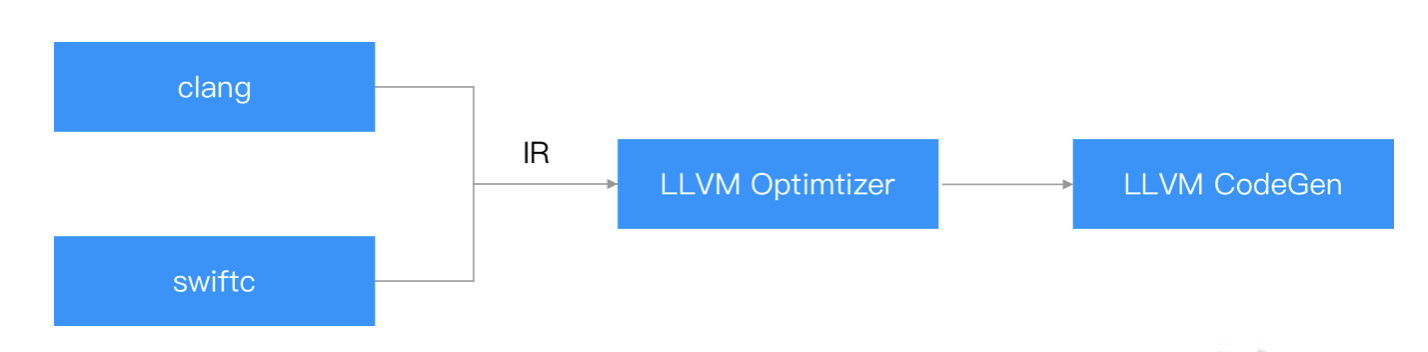
编译器可以分为两大部分:前端和后端,二者以 IR(中间代码)作为媒介。这样前后端分离,使得前后端可以独立的变化,互不影响。C 语言家族的前端是 clang,swift 的前端是 swiftc,二者的后端都是 llvm。
- 前端负责预处理,词法语法分析,生成 IR
- 后端基于 IR 做优化,生成机器码
那么如何利用编译优化启动速度呢?
代码数量会影响启动速度,为了提升启动速度,我们可以把一些无用代码下掉。那怎么统计哪些代码没有用到呢?可以利用 LLVM 插桩来实现。
LLVM 的代码优化流程是一个一个 Pass,由于 LLVM 是开源的,我们可以添加一个自定义的 Pass,在函数的头部插入一些代码,这些代码会记录这个函数被调用了,然后把统计到的数据上传分析,就可以知道哪些代码是用不到的了 。
Facebook 给 LLVM 提的order_file的 feature 就是实现了类似的插桩。
链接
经过编译后,我们有很多个目标文件,接着这些目标文件会和静态库,动态库一起,链接出一个 Mach-O。链接的过程并不产生新的代码,只会做一些移动和补丁。
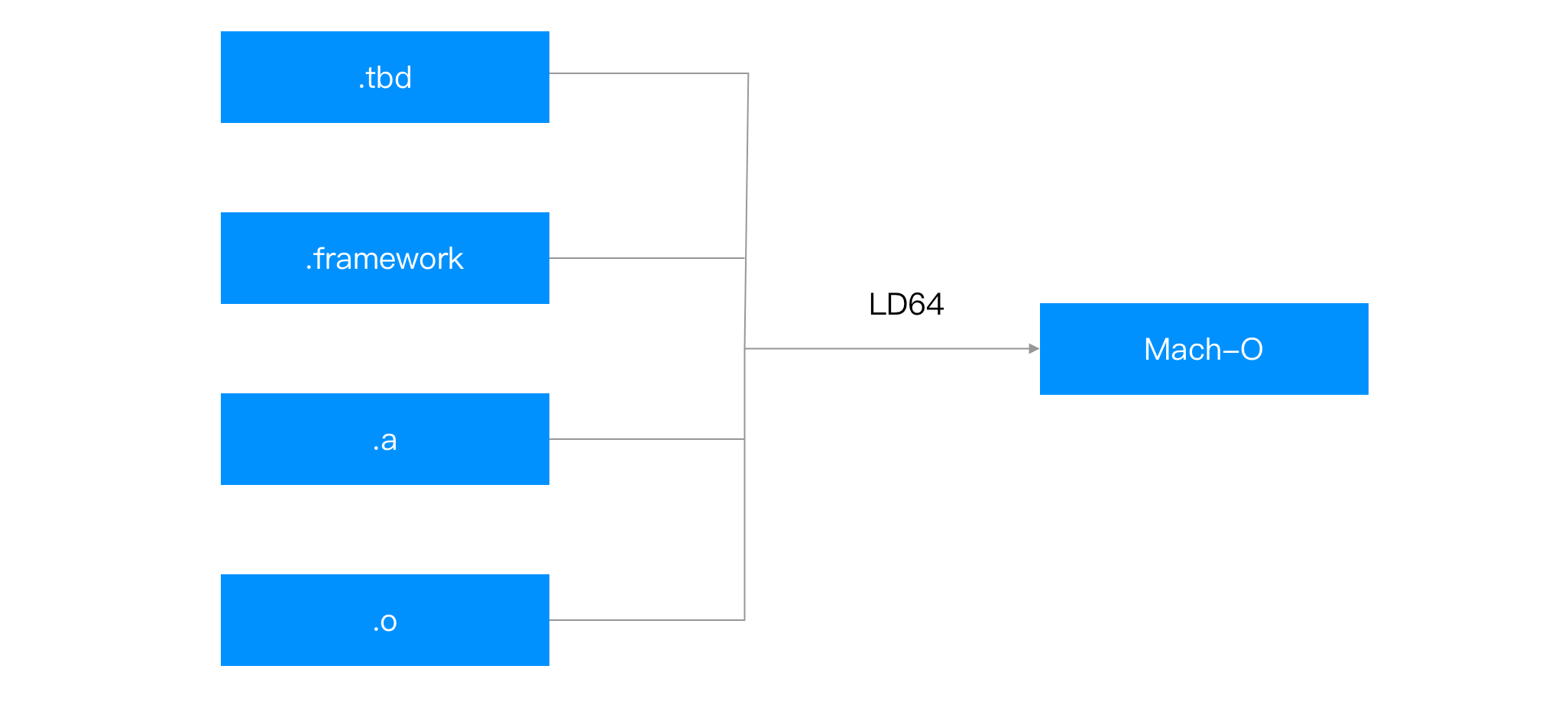
- tbd 的全称是 text-based stub library,是因为链接的过程中只需要符号就可以了,所以 Xcode 6 开始,像 UIKit 等系统库就不提供完整的 Mach-O,而是提供一个只包含符号等信息的 tbd 文件。
举一个基于链接优化启动速度的例子:
最开始讲解 Page In 的时候,我们提到 TEXT 段的页解密很耗时,有没有办法优化呢?
可以通过 ld 的-rename_section,把 TEXT 段中的内容,比如字符串移动到其他的段(启动路径上难免会读很多字符串),从而规避这个解密的耗时。
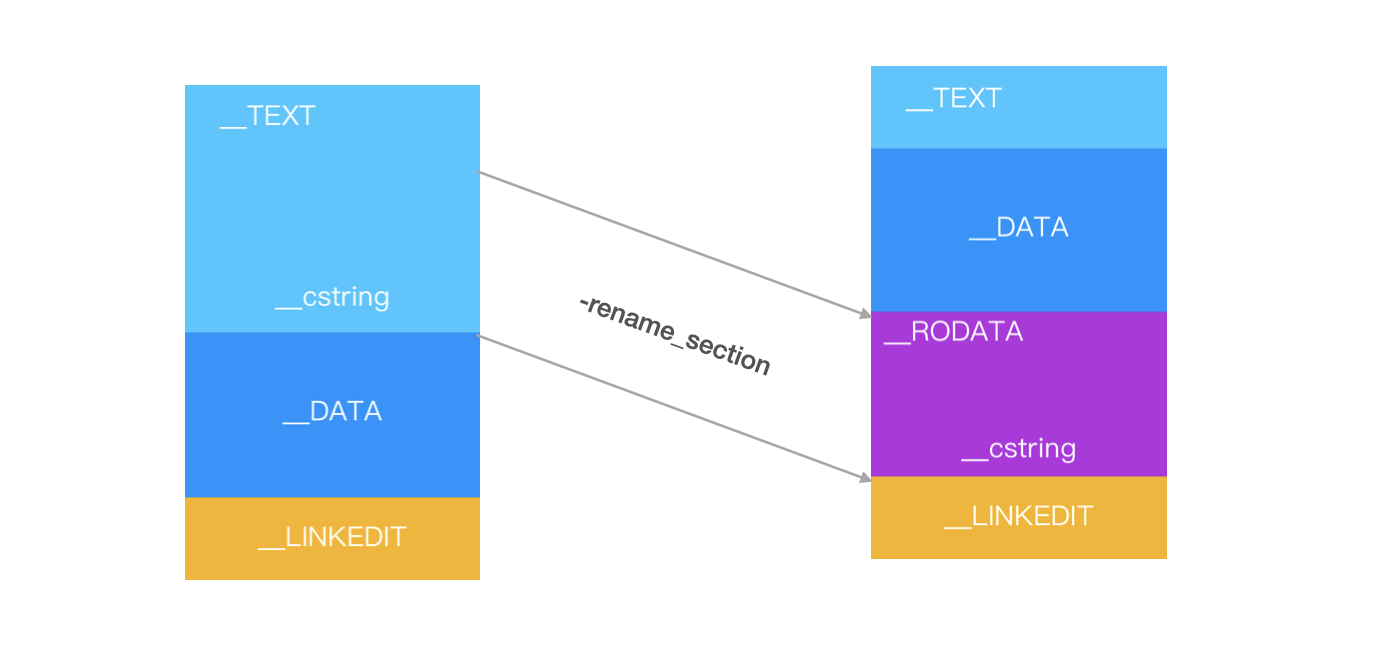
抖音的重命名方案:
"-Wl,-rename_section,__TEXT,__cstring,__RODATA,__cstring",
"-Wl,-rename_section,__TEXT,__const,__RODATA,__const",
"-Wl,-rename_section,__TEXT,__gcc_except_tab,__RODATA,__gcc_except_tab",
"-Wl,-rename_section,__TEXT,__objc_methname,__RODATA,__objc_methname",
"-Wl,-rename_section,__TEXT,__objc_classname,__RODATA,__objc_classname",
"-Wl,-rename_section,__TEXT,__objc_methtype,__RODATA,__objc_methtype"裁剪
编译完 Mach-O 之后会进行裁剪(strip),是因为里面有些信息,如调试符号,是不需要带到线上去的。裁剪有多种级别,一般的配置如下:
- All Symbols,主二进制
- Non-Global Symbols,动态库
- Debugging Symbols,二方静态库
为什么二方库在出静态库的时候要选择 Debugging Symbols 呢?是因为像 order_file 等链接期间的优化是基于符号的,如果把符号裁剪掉,那么这些优化也就不会生效了。
签名 & 上传
裁剪完二进制后,会和编译好的资源文件一起打包成.app 文件,接着对这个文件进行签名。签名的作用是保证文件内容不多不少,没有被篡改过。接着会把包上传到 iTunes Connect,上传后会对__TEXT段加密,加密会减弱 IPA 的压缩效果,增加包大小,也会降低启动速度 (iOS 13 优化了加密过程,不会对包大小和启动耗时有影响)。
dyld3 启动流程
Apple 在 iOS 13 上对第三方 App 启用了 dyld3,官方数据显示,过去四年新发布的设备中有 93%的设备是 iOS 13,所以我们重点看下 dyld3 的启动流程。
Before dyld
用户点击图标之后,会发送一个系统调用 execve 到内核,内核创建进程。接着会把主二进制 mmap 进来,读取 load command 中的 LC_LOAD_DYLINKER,找到 dyld 的的路径。然后 mmap dyld 到虚拟内存,找到 dyld 的入口函数_dyld_start,把 PC 寄存器设置成_dyld_start,接下来启动流程交给了 dyld。
注意这个过程都是在内核态完成的,这里提到了 PC 寄存器,PC 寄存器存储了下一条指令的地址,程序的执行就是不断修改和读取 PC 寄存器来完成的。
dyld
创建启动闭包
dyld 会首先创建启动闭包,闭包是一个缓存,用来提升启动速度的。既然是缓存,那么必然不是每次启动都创建的,只有在重启手机或者更新/下载 App 的第一次启动才会创建。闭包存储在沙盒的 tmp/com.apple.dyld 目录,清理缓存的时候切记不要清理这个目录。
闭包是怎么提升启动速度的呢?我们先来看一下闭包里都有什么内容:
- dependends,依赖动态库列表
- fixup:bind & rebase 的地址
- initializer-order:初始化调用顺序
- optimizeObjc: Objective C 的元数据
- 其他:main entry, uuid…
动态库的依赖是树状的结构,初始化的调用顺序是先调用树的叶子结点,然后一层层向上,最先调用的是 libSystem,因为他是所有依赖的源头。
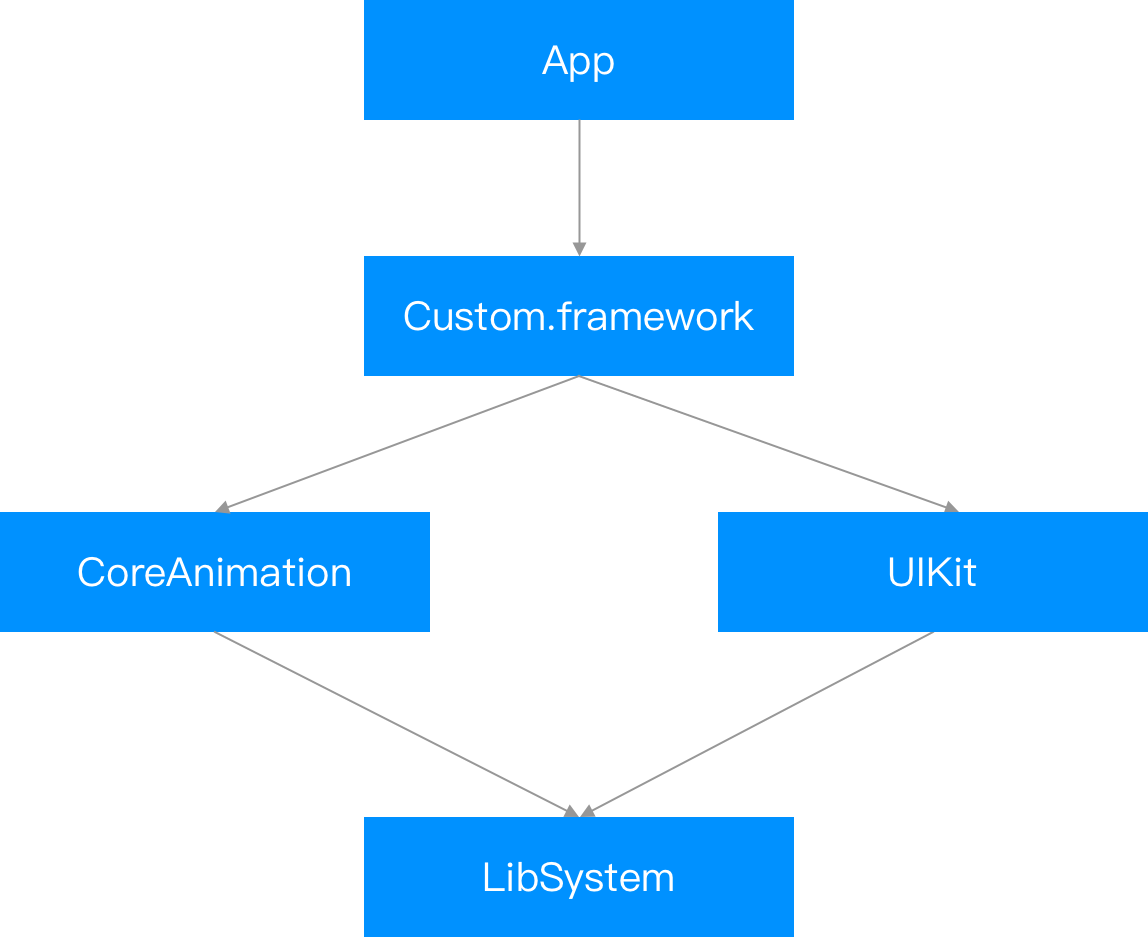
为什么闭包能提高启动速度呢?
因为这些信息是每次启动都需要的,把信息存储到一个缓存文件就能避免每次都解析,尤其是 Objective C 的运行时数据(Class/Method...)解析非常慢。
fixup
有了闭包之后,就可以用闭包启动 App 了。这时候很多动态库还没有加载进来,会首先对这些动态库 mmap 加载到虚拟内存里。接着会对每个 Mach-O 做 fixup,包括 Rebase 和 Bind。
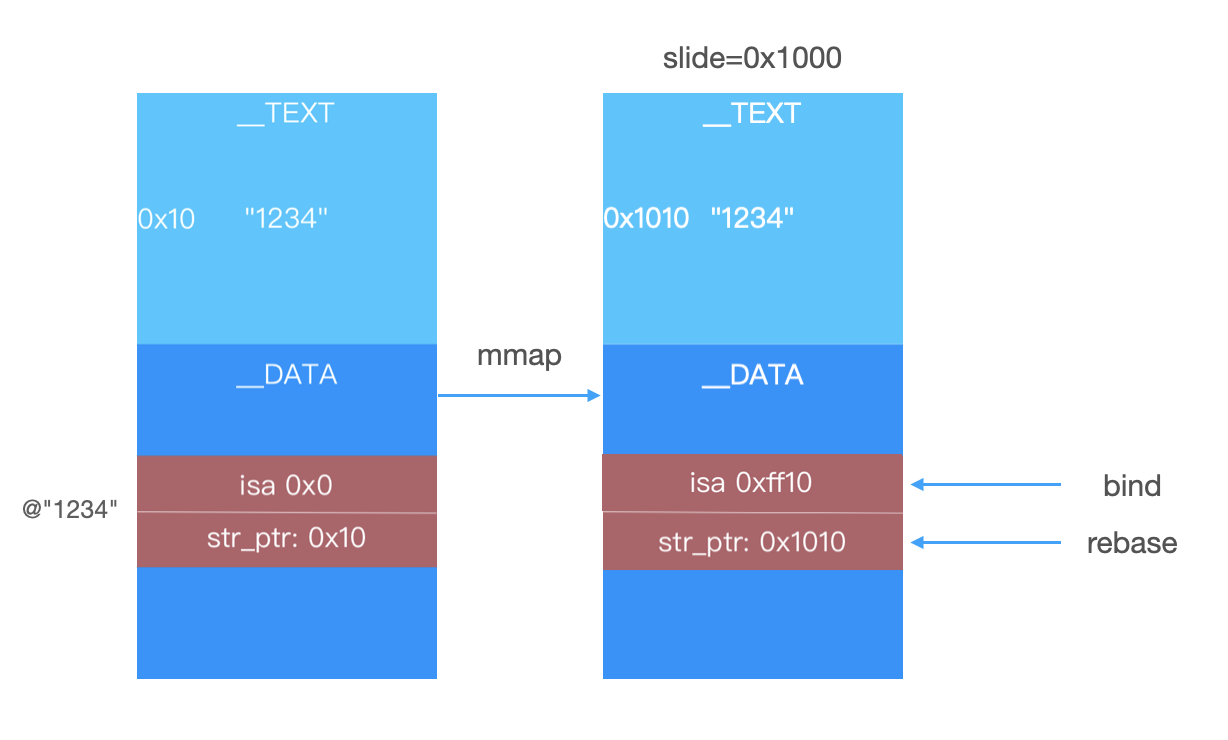
- Rebase:修复内部指针。这是因为 Mach-O 在 mmap 到虚拟内存的时候,起始地址会有一个随机的偏移量 slide,需要把内部的指针指向加上这个 slide。
- Bind:修复外部指针。这个比较好理解,因为像 printf 等外部函数,只有运行时才知道它的地址是什么,bind 就是把指针指向这个地址。
举个例子:一个 Objective C 字符串@"1234",编译到最后的二进制的时候是会存储在两个 section 里的
- __TEXT,__cstring,存储实际的字符串"1234"
- __DATA,__cfstring,存储 Objective C 字符串的元数据,每个元数据占用 32Byte,里面有两个指针:内部指针,指向__TEXT,__cstring中字符串的位置;外部指针 isa,指向类对象的,这就是为什么可以对 Objective C 的字符串字面量发消息的原因。
如下图,编译的时候,字符串 1234 在__cstring的 0x10 处,所以 DATA 段的指针指向 0x10。但是 mmap 之后有一个偏移量 slide=0x1000,这时候字符串在运行时的地址就是 0x1010,那么 DATA 段的指针指向就不对了。Rebase 的过程就是把指针从 0x10,加上 slide 变成 0x1010。运行时类对象的地址已经知道了,bind 就是把 isa 指向实际的内存地址。
LibSystem Initializer
Bind & Rebase 之后,首先会执行 LibSystem 的 Initializer,做一些最基本的初始化:
- 初始化 libdispatch
- 初始化 objc runtime,注册 sel,加载 category
注意这里没有初始化 objc 的类方法等信息,是因为启动闭包的缓存数据已经包含了 optimizeObjc。
Load & Static Initializer
接下来会进行 main 函数之前的一些初始化,主要包括+load 和 static initializer。这两类初始化函数都有个特点:调用顺序不确定,和对应文件的链接顺序有关系。那么就会存在一个隐藏的坑:有些注册逻辑在+load 里,对应会有一些地方读取这些注册的数据,如果在+load 中读取,很有可能读取的时候还没有注册。
那么,如何找到代码里有哪些 load 和 static initializer 呢?
在 Build Settings 里可以配置 write linkmap,这样在生成的 linkmap 文件里就可以找到有哪些文件里包含 load 或者 static initializer:
- __mod_init_func,static initializer
- __objc_nlclslist,实现+load 的类
- __objc_nlcatlist,实现+load 的 Category
load 举例
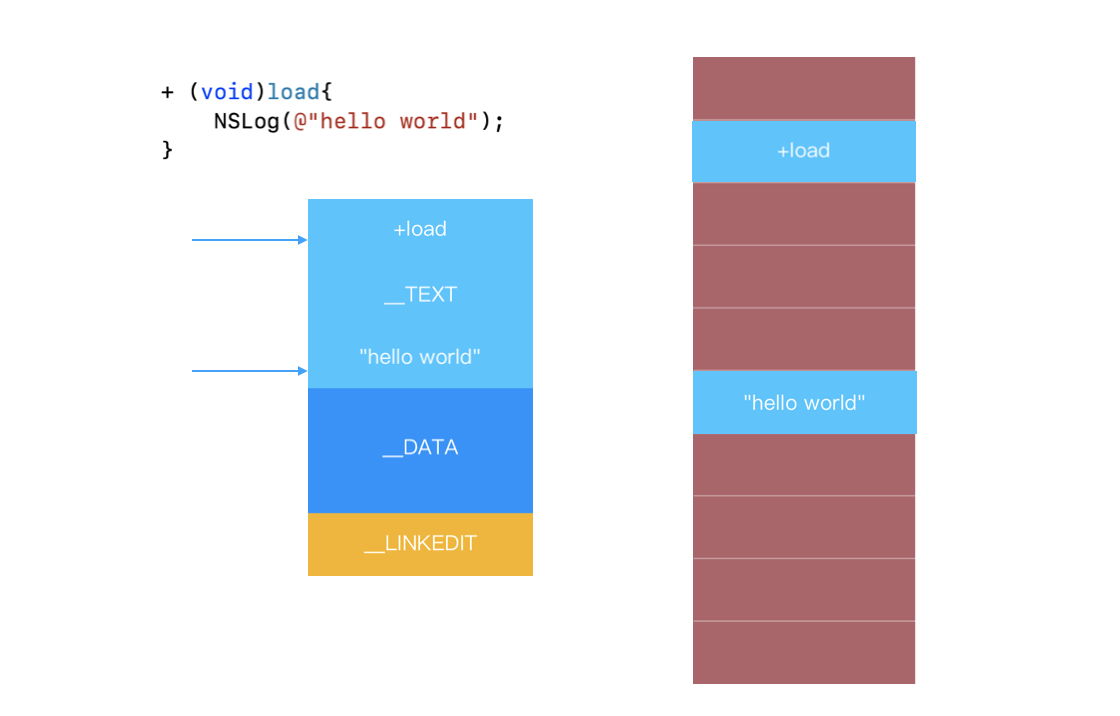
如果+load 方法里的内容很简单,会影响启动时间么?比如这样的一个+load 方法?
+ (void)load
{
printf("1234");
}
编译完了之后,这个函数会在二进制中的 TEXT 两个段存在:__text存函数二进制,cstring存储字符串 1234。为了执行函数,首先要访问__text触发一次 Page In 读入物理内存,为了打印字符串,要访问__cstring,还会触发一次 Page In。
- 为了执行这个简单的函数,系统要额外付出两次 Page In 的代价,所以 load 函数多了,page in 会成为启动性能的瓶颈。
static initializer 产生的条件
静态初始化是从哪来的呢?以下几种代码会导致静态初始化
- __attribute__((constructor))
- static class object
- static object in global namespace
注意,并不是所有的 static 变量都会产生静态初始化,编译器很智能,对于在编译期间就能确定的变量是会直接 inline。
//会产生静态初始化
class Demo{
static const std::string var_1;
};
const std::string var_2 = "1234";
static Logger logger;
//不会产生静态初始化
static const int var_3 = 4;
static const char * var_4 = "1234";
std::string 会合成 static initializer 是因为初始化的时候必须执行构造函数,这时候编译器就不知道怎么做了,只能延迟到运行时~
UIKit Init
+load 和 static initializer 执行完毕之后,dyld 会把启动流程交给 App,开始执行 main 函数。main 函数里要做的最重要的事情就是初始化 UIKit。UIKit 主要会做两个大的初始化:
- 初始化 UIApplication
- 启动主线程的 Runloop
由于主线程的 dispatch_async 是基于 runloop 的,所以在+load 里如果调用了 dispatch_async 会在这个阶段执行。
Runloop
线程在执行完代码就会退出,很明显主线程是不能退出的,那么就需要一种机制:事件来的时候执行任务,否则让线程休眠,Runloop 就是实现这个功能的。
Runloop 本质上是一个 While 循环,在图中橙色部分的 mach_msg_trap 就是触发一个系统调用,让线程休眠,等待事件到来,唤醒 Runloop,继续执行这个 while 循环。
Runloop 主要处理几种任务:Source0,Source1,Timer,GCD MainQueue,Block。在循环的合适时机,会以 Observer 的方式通知外部执行到了哪里。
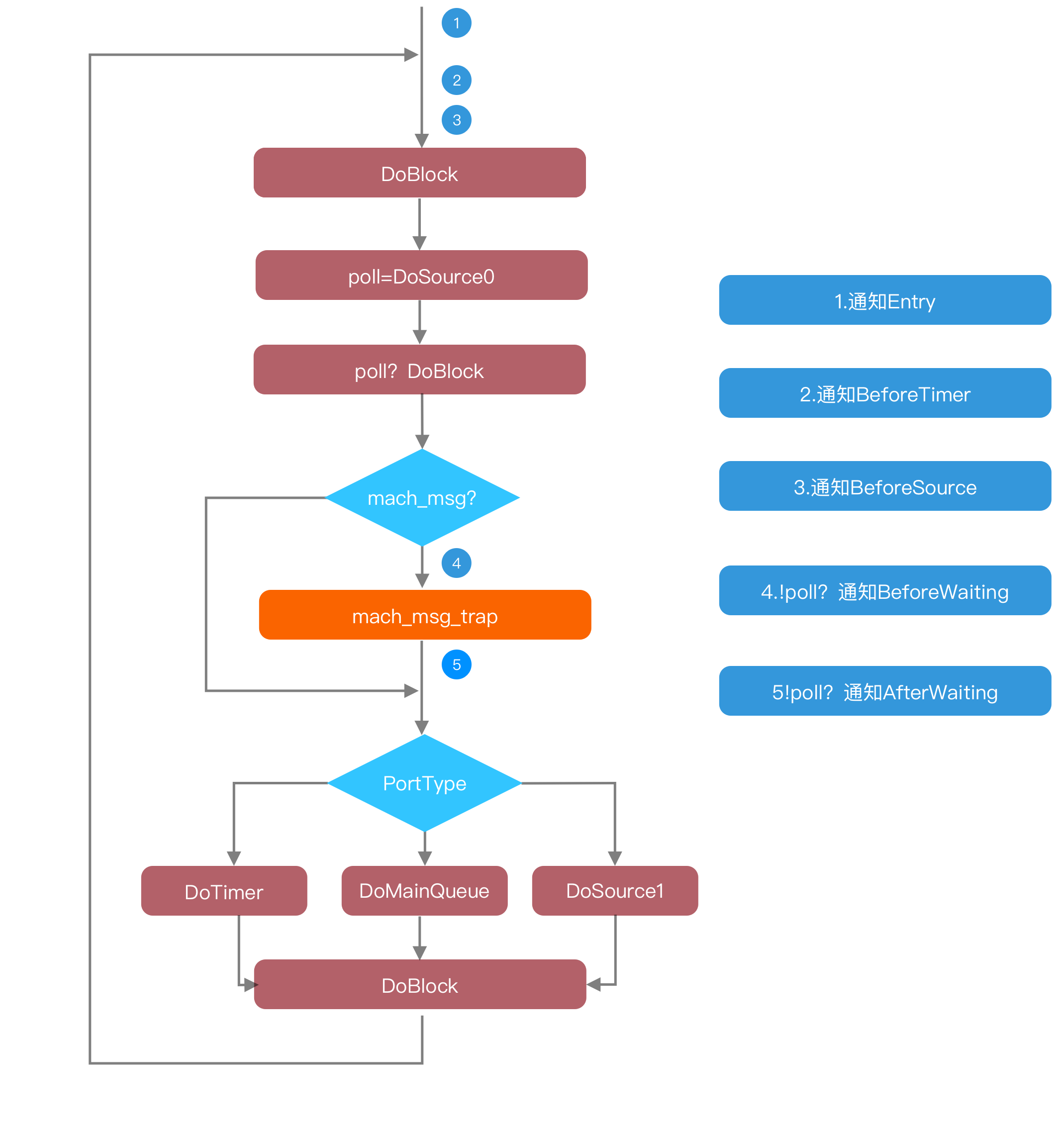
那么,Runloop 与启动又有什么关系呢?
- App 的 LifeCycle 方法是基于 Runloop 的 Source0 的
- 首帧渲染是基于 Runloop Block 的
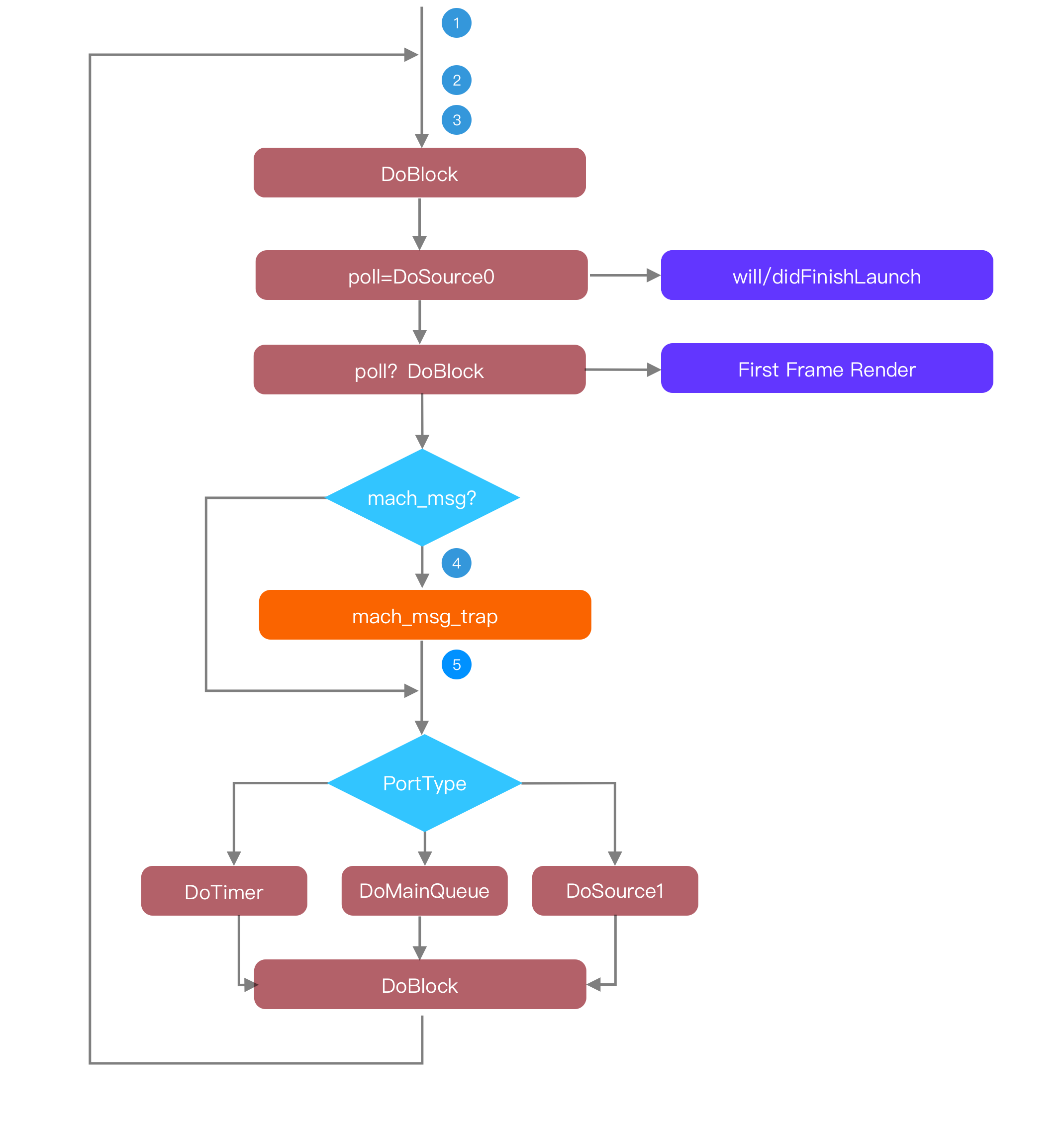
Runloop 在启动上主要有几点应用:
- 精准统计启动时间
- 找到一个时机,在启动结束去执行一些预热任务
- 利用 Runloop 打散耗时的启动预热任务
Tips: 会有一些逻辑要在启动之后 delay 一小段时间再回到主线程上执行,对于性能较差的设备,主线程 Runloop 可能一直处于忙的状态,所以这个 delay 的任务并不一定能按时执行。
AppLifeCycle
UIKit 初始化之后,就进入了我们熟悉的 UIApplicationDelegate 回调了,在这些会调里去做一些业务上的初始化:
- willFinishLaunch
- didFinishLaunch
- didFinishLaunchNotification
要特别提一下 didFinishLaunchNotification,是因为大家在埋点的时候通常会忽略还有这个通知的存在,导致把这部分时间算到 UI 渲染里。
First Frame Render
一般会用 Root Controller 的 viewDidApper 作为渲染的终点,但其实这时候首帧已经渲染完成一小段时间了,Apple 在 MetricsKit 里对启动终点定义是第一个CA::Transaction::commit()。
什么是 CATransaction 呢?我们先来看一下渲染的大致流程

iOS 的渲染是在一个单独的进程 RenderServer 做的,App 会把 Render Tree 编码打包给 RenderServer,RenderServer 再调用渲染框架(Metal/OpenGL ES)来生成 bitmap,放到帧缓冲区里,硬件根据时钟信号读取帧缓冲区内容,完成屏幕刷新。CATransaction 就是把一组 UI 上的修改,合并成一个事务,通过 commit 提交。
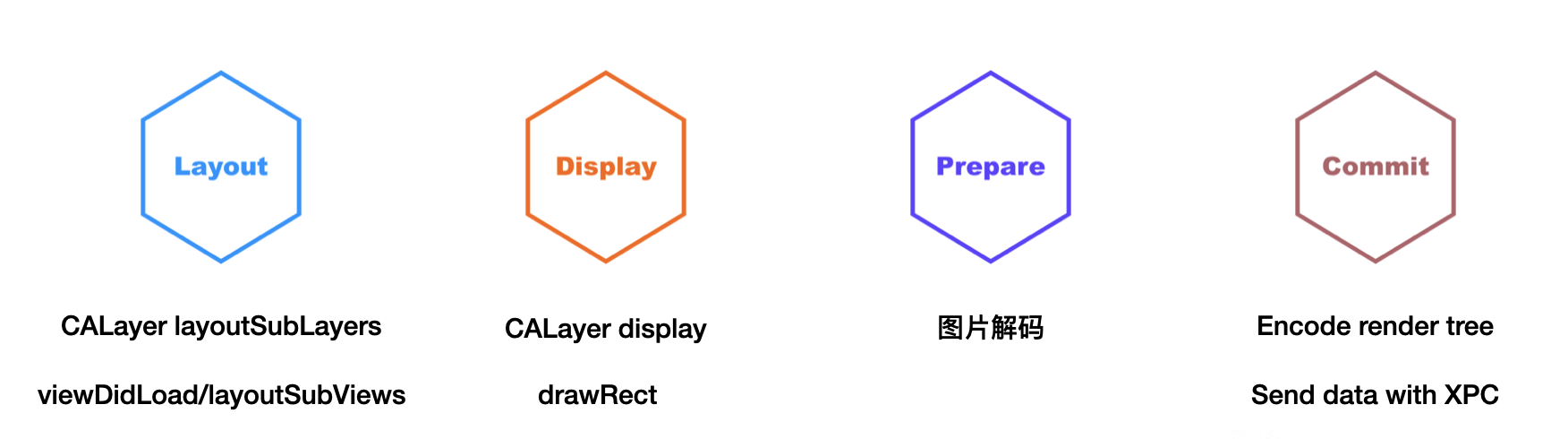
渲染可以分为四个步骤
- Layout(布局),源头是 Root Layer 调用[CALayer layoutSubLayers],这时候 UIViewController 的 viewDidLoad 和 LayoutSubViews 会调用,autolayout 也是在这一步生效
- Display(绘制),源头是 Root Layer 调用[CALayer display],如果 View 实现了 drawRect 方法,会在这个阶段调用
- Prepare(准备),这个过程中会完成图片的解码
- Commit(提交),打包 Render Tree 通过 XPC 的方式发给 Render Server
启动 Pipeline
详细回顾下整个启动过程,以及各个阶段耗时的影响因素:
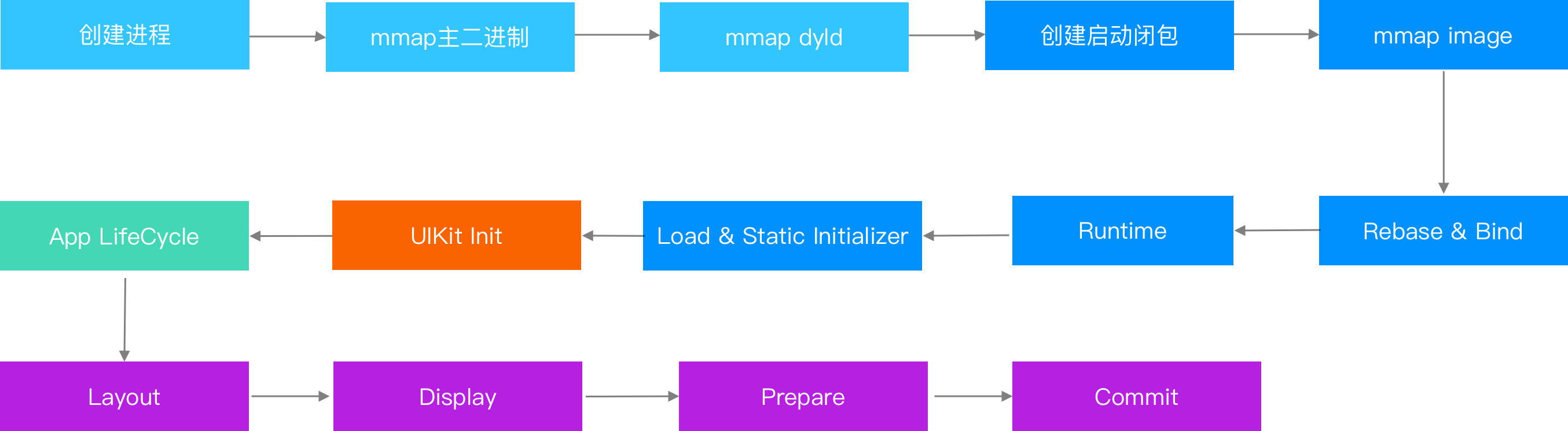
- 点击图标,创建进程
- mmap 主二进制,找到 dyld 的路径
- mmap dyld,把入口地址设为_dyld_start
- 重启手机/更新/下载 App 的第一次启动,会创建启动闭包
- 把没有加载的动态库 mmap 进来,动态库的数量会影响这个阶段
- 对每个二进制做 bind 和 rebase,主要耗时在 Page In,影响 Page In 数量的是 objc 的元数据
- 初始化 objc 的 runtime,由于闭包已经初始化了大部分,这里只会注册 sel 和装载 category
- +load 和静态初始化被调用,除了方法本身耗时,这里还会引起大量 Page In
- 初始化 UIApplication,启动 Main Runloop
- 执行 will/didFinishLaunch,这里主要是业务代码耗时
- Layout,viewDidLoad 和 Layoutsubviews 会在这里调用,Autolayout 太多会影响这部分时间
- Display,drawRect 会调用
- Prepare,图片解码发生在这一步
- Commit,首帧渲染数据打包发给 RenderServer,启动结束
dyld2
dyld2 和 dyld3 的主要区别就是没有启动闭包,就导致每次启动都要:
- 解析动态库的依赖关系
- 解析 LINKEDIT,找到 bind & rebase 的指针地址,找到 bind 符号的地址
- 注册 objc 的 Class/Method 等元数据,对大型工程来说,这部分耗时会很长
总结
本文回顾了 Mach-O,虚拟内存,mmap,Page In,Runloop 等基础概念,接下来介绍了 IPA 的构建流程,以及两个典型的利用编译器来优化启动的方案,最后详细的讲解了 dyld3 的启动 pipeline。
之所以花这么大篇幅讲原理,是因为任何优化都一样,只有深入理解系统运作的原理,才能找到性能的瓶颈,下一篇我们会介绍下如何利用这些原理解决实际问题。
注意:本文归作者所有,未经作者允许,不得转载

