接着上篇文章 Spark+Hbase 亿级流量分析实战(数据结构设计) 我们已经设计好了日志的结构,接下来我们就准备要开始撸代码了,我最喜欢这部分的环节了,可是一个上来连就撸代码的程序肯定不是好程序员,要不先设计设计流程图?那来吧!!!


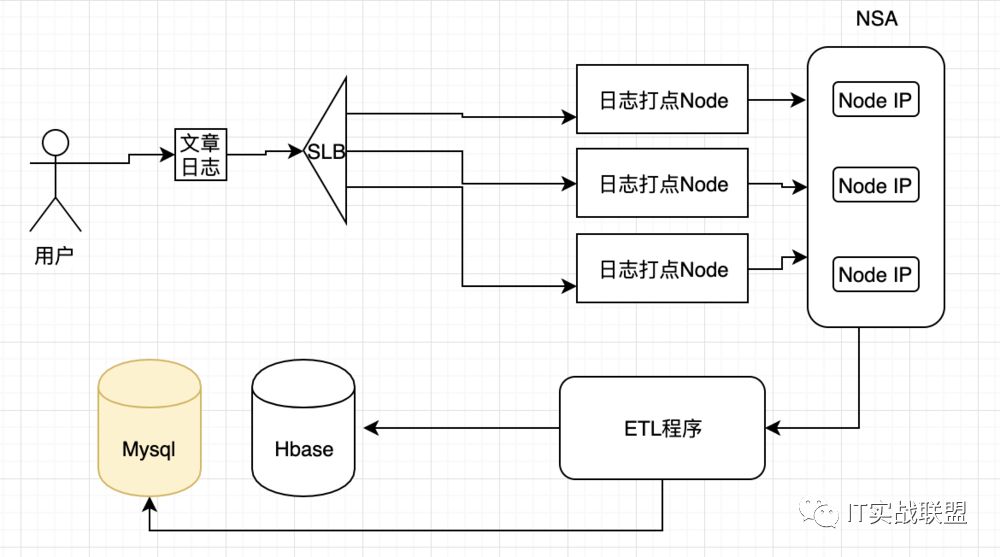

用户发起文章操作,发起请求日志
日志将由SLB服务器进行负载到日志打点服务器。
NSA将作为日志收集中心进行存储,也可以使用
Rsync把节点上的日志同步到日志中心。作为核心的
ETL程序,将要对日志中心上所有节点的数据进行抽取转换加载。上图中出现的Hbase比较好理解,但是为什么要出现
Mysql?因为我们要更细粒度地控制日志的写入时间点,主要用来记录日志时间的offset,后续会有详细的介绍。

用户发起文章操作,发起请求日志
日志将由SLB服务器进行负载到日志打点服务器。
Filebeat 收集节点日志 到Kafka,主要是用来日志削峰使用。
或者:使用nginx直接将日志写入kafka,因为nginx也是生产级别的。ETL 将消费Kafka 数据并写到Hbase。
与设计一相同

日志中心的存储会是下面这样
├── log│ ├── 2019-03-21│ │ ├── 111.12.32.11│ │ │ ├── 10_01.log│ │ │ └── 10_02.log│ │ ├── 222.22.123.123│ │ │ ├── 0_01.log│ │ │ ├── 0_02.log│ │ │ └── 0_03.log│ │ └── 33.44.55.11│ ├── 2019-03-22│ └── 2019-03-23
每分钟每节点会生成一个文件。
一天一个文件夹。
这样子的设计可以方便查错。
日志内容如下
{"time":1553269361115,"data":{"type": "read","aid":"10000","uid":"4229d691b07b13341da53f17ab9f2416","tid": "49f68a5c8493ec2c0bf489821c21fc3b","ip": "22.22.22.22"}}{"time":1553269371115,"data":{"type": "comment","content":"666,支持一下","aid":"10000","uid":"4229d691b07b13341da53f17ab9f2416","tid": "49f68a5c8493ec2c0bf489821c21fc3b","ip": "22.22.22.22"}}

选择设计一
因为我们就看上了第5点,在线上业务稳定了一年的使用情况来看,这种方案是可行的。
在下篇文章中,我们将真实开始撸我们的黄金代码了,所有程序将使用scala进行实现,你想问我什么吗?四个字:

心明眼亮的你、从此刻开始。


作者:大猪大猪
链接:https://www.jianshu.com/p/24a6daf93746
---------------END----------------
后续的内容同样精彩
长按关注“IT实战联盟”哦

注意:本文归作者所有,未经作者允许,不得转载

