为什么会有kafka
起源是数据集成,从不同地方拿数据,数据流非常的乱
数据集成超麻烦,你往往会发现你用在收集整理数据的时间是最多的,像这样
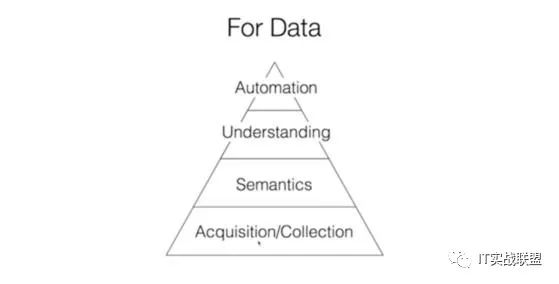
随着时代的发展,会有各种各样的新数据,特点:实时的,不断产生,量大
数据有两种:一种是数据库数据,比如用户、产品等关系型数据;另一种是实时的数据,比如数据(包括用户点击、浏览等),应用数据(包括CPU的使用等)和log。

因此有了各种各样的新系统来处理这些数据

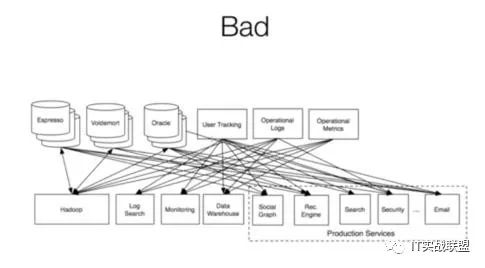
但是这些数据产生后,产生的问题:数据爆炸
如果不同的数据用不同的数据库来存储监控,不同应用要从不同的地方取得需要的数据,就会这样(炸了)
问题:
数据源多
数据传输可靠性
数据一致性
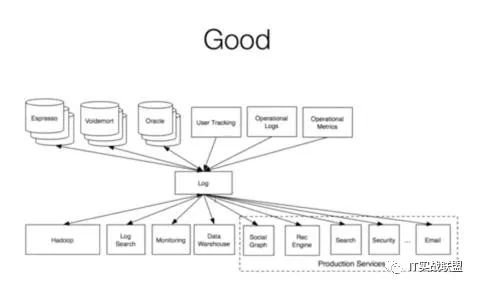
所以Kafka出现了,把数据集成这个环节做的简洁高效,像这样
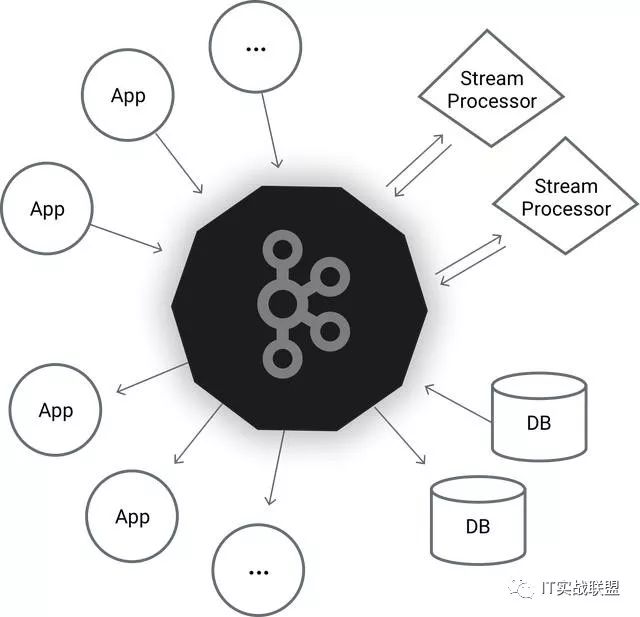
解决办法就是通过一个统一的部件来做数据的采集传输
Kafka把这个过程抽象了一下变成了这样(眼熟不眼熟,就是生产者消费者模型呀):
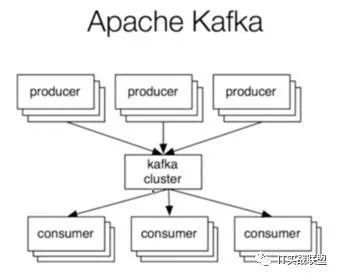
kafka设计的基本原则

一个流能不能解决所有问题
不仅仅是消息系统,而是一个流处理系统
不仅是单台,而是clusters
特性:

支持大数据,高吞吐
保证消息的有序
数据持久化
支持分布式

Kafka最核心的是log,什么是log呢,log就是记录什么时间发生了什么事
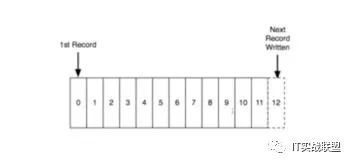
log抽象起来就是有序序列
如果log非常多,就进行partition
当log很多就要做成分布式,对log分区,每个partition是独立的、不交互的,这样避免了partition之间的协调,非常高效。像这样:
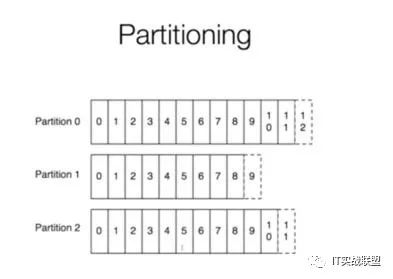
那为什么不考虑不同partition之间的顺序呢?因为复杂度
工作流程就是数据源(生产者)将数据写入log,消费者从log中提取数据,log起到了一个消息队列的作用。所以Kafka就是一个基于分布式log实现的,具有发布/订阅功能的消息系统。
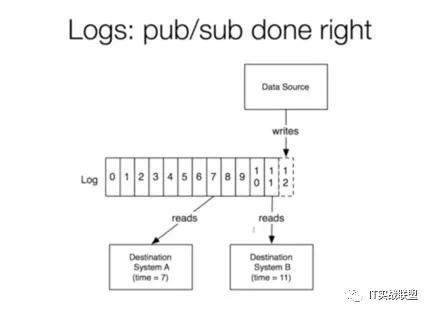
如何应用kafka
分布式系统
数据集成
实时计算
例子:
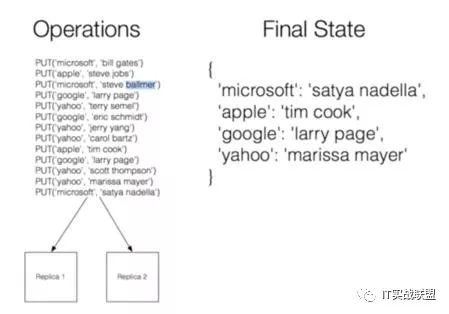
各个公司的ceo,如果其中某一个消息丢了怎么办
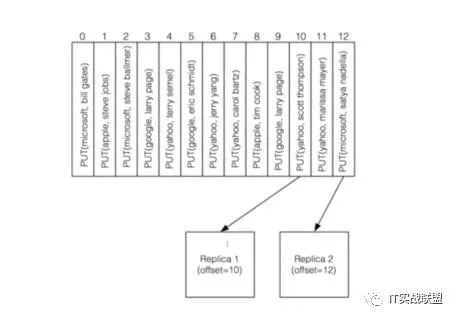
做法就是讲所有事件都排成有序队列,保证消息不丢
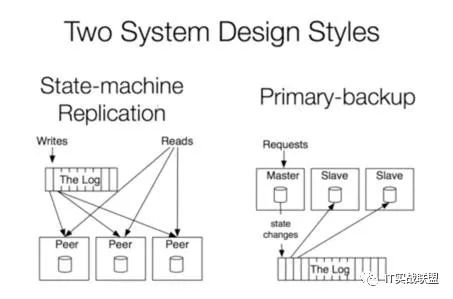
数据集成
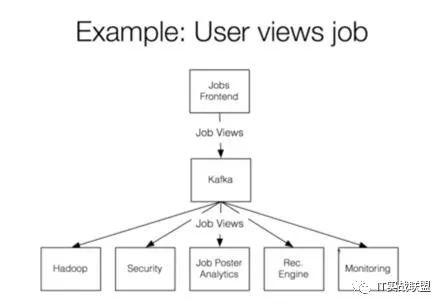
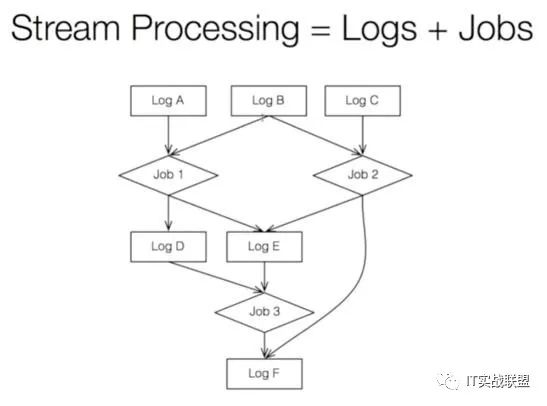
因为Kafka用log记下了所有时间发生的所有事,任何一个状态都可以被恢复出来。Kafka的理念就是实时处理就是log加计算(Job),像这样:

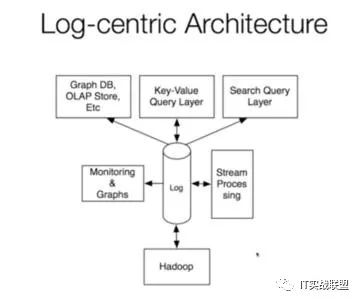
---------------END----------------
后续的内容同样精彩
长按关注“IT实战联盟”哦

注意:本文归作者所有,未经作者允许,不得转载

