来源:https://www.toutiao.com/i6773550684210987523在公司有一个需求是要核对一批数据,之前的做法是直接用SQL各种复杂操作给怼出来的,不仅时间慢,而且后期也不好维护,就算原作者来了过一个月估计也忘了SQL什么意思了,于是有一次我就想着问一下之前做这个需求的人为什么不将这些数据查出来后在内存里面做筛选呢?直接说了你不怕把内存给撑爆吗?此核算服务器是单独的服务器,配置是四核八G的,配置堆的大小是4G。本着怀疑的精神,就想要弄清楚几百万条数据真的放入内存的话会占用多少内存呢?
计算机的存储单位
计算机的存储单位常用的有bit、Byte、KB、MB、GB、TB后面还有但是我们基本上用不上就不说了,我们经常将bit称之为比特或者位、将Byte简称为B或者字节,将KB简称为K,将MB称之为M或者兆,将GB简称为G。那么他们的换算单位是怎样的呢?
换算关系
首先我们得知道在计算机中所有数据都是由0 1来组成的,那么存储0 1这些二进制数据是由什么存放呢?就是由bit存放的,一个bit存放一位二进制数字。所以bit是计算机最小的单位。
大部分计算机目前都是使用8位的块,就是我们上面称之为的字节Byte,来作为计算机容量的基本单位。所以我们一般称一个字符或者一个数字都是称之为占用了多少字节。
了解了上面关于位和字节的关系后,我们可以看一下其他的单位换算关系
11B(Byte字节)=8bit(位)21KB=1024B31MB=1024KB41GB=1024MB51TB=1024GBJava中对象占用多少内存
在了解了上面的换算关系后,我们来了解一下新建一个Java对象需要多少内存。
Java基本类型
我们知道Java类型分为基本类型和引用类型,八大基本类型有int、short、long、byte、float、double、boolean、char
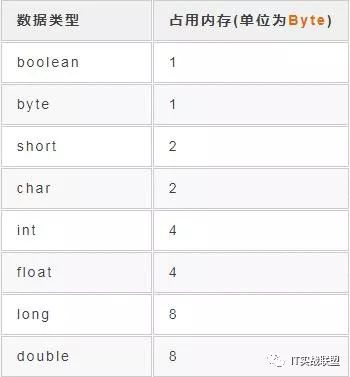
至于为什么Java中的char无论是中英文数字都占用两个字节,是因为Java中使用Unicode字符,所有的字符均以两个字节存储。
Java引用类型
在一个对象中除了有基本数据类型以外,我们也会有一些引用类型,引用类型的对象比较特殊,因为这些对象真正存储在虚拟机中的堆内存中,对象中只是存储了一个引用而已,如果是引用类型那么就会存储一个指向该引用的指针。指针默认情况下是占用4字节,是因为开启了指针压缩,如果没有开的话,那么一个引用就占用8个字节。
对象在内存中的布局
在HotSpot虚拟机中,对象在内存中存储的布局可以分为三个区域:对象头(Header)、实例数据(Instance Data)、对齐填充(Padding)。

对象头
在对象头中存储了两部分数据
运行时数据:存储了对象自身运行时的数据,例如哈希码、GC分代的年龄、锁状态标志、线程持有的锁、偏向线程ID等等。这部分数据在32位和64位的虚拟机中分别为32bit和64bit
类型指针:对象指向它的类元数据的指针,虚拟机通过这个指针来确定这个对象是哪个类的实例。如果对象是一个Java数组的话,那么对象头中还必须有一块用于记录数组长度的数据(占用4个字节)。所以这是一个指针,默认JVM对指针进行了压缩,用4个字节存储。
我们以虚拟机为64位的机器为例,那么对象头占用的内存是8(运行时数据)+4(类型指针)=12Byte。如果是数组的话那么就是16Byte
实例数据
实例数据中也拥有两部分数据,一部分是基本类型数据,一部分是引用指针。这两部分数据我们在上面已经讲了。具体占用多少内存我们需要结合具体的对象继续分析,下面我们会有具体的分析。
从父类中继承下来的变量也是需要进行计算的
对齐填充
对齐填充并不是必然存在的,也没有特别的含义。它仅仅起着占位符的作用。由于HotSpot VM的自动内存管理系统要求对象起始地址必须是8字节的整数倍,换句话说就是对象的大小必须是8字节的整数倍。而如果对象头加上实例数据不是8的整数倍的话那么就会通过对其填充进行补全。
实战演练
我们在上面分析一大堆,那么是不是就如我们分析的一样,新建一个对象在内存中的分配大小就是如此呢?我们可以新建一个对象。
1classAnimal{23privateintage;45}那么怎么知道这个对象在内存中占用多少内存呢?JDK提供了一个工具jol-core可以给我们分析出来一个对象在内存中占用的内存大小。直接在项目中引入包即可。
1--Gradle2compile'org.openjdk.jol:jol-core:0.9'34--Maven5<dependency>6<groupId>org.openjdk.jol</groupId>7<artifactId>jol-core</artifactId>8<version>0.9</version>9</dependency>然后我们在main函数中调用如下
1publicclassAboutObjectMemory{23publicstaticvoidmain(String[]args){4System.out.print(ClassLayout.parseClass(Animal.class).toPrintable());5}6}就可以查看到输出的内容了,可以看到输出结果占用的内存是16字节,和我们分析的一样。
1aboutjava.other.Animalobjectinternals:2OFFSETSIZETYPEDESCRIPTIONVALUE3012(objectheader)N/A4124intAnimal.ageN/A5Instancesize:16bytes6Spacelosses:0bytesinternal+0bytesexternal=0bytestotalString占用多少内存
String字符串在Java中是个特殊的存在,比如一个字符串"abcdefg"这样一个字符串占用多少字节呢?相信会有人回答说是7个字节或者是14个字节,这两个答案都是不准确的,我们先看一下String类在内存中占用的内存是多少。
我们先自己进行分析一下。在String类中有两个属性,其中对象头固定了是12字节,int是4字节,char[]数组其实在这里相当于引用对象存的,所以存的是地址,因此占用4个字节,所以大小为对象头12Byte+实例数据8Byte+填充数据4Byte=24Byte这里的对象头和实例数据加起来不是8的倍数,所以需要填充数据进行填充。
1privatefinalcharvalue[];23privateinthash;//Defaultto0那么我们分析的到底对不对呢,我们还是用上面的工具进行分析一下。可以看到我们算出的结果和我们分析的结果是一致的。
1java.lang.Stringobjectinternals:2OFFSETSIZETYPEDESCRIPTIONVALUE3012(objectheader)N/A4124char[]String.valueN/A5164intString.hashN/A6204(lossduetothenextobjectalignment)7Instancesize:24bytes那么一个空字符串占用多少内存呢?我们刚才得到的是一个String对象占用了24字节,其实char[]数组还是会占用内存的,我们在上面讲对象头的时候说过,数组对象也是一个实例对象,它的对象头比一般的对象多出来4字节,用来描述此数组的长度,所以char[]数组的对象头长度为16字节,由于此时是空字符串,所以实例数据长度为0。因此一个空char[]数组占用内存大小为对象头16Byte+实例数据0Byte=16Byte。一个空字符串占用内存为String对象+char[]数组对象=40Byte
那么我们上面举的例子abcdefg占用多少内存呢?其中String对象占用的内存是不会变了,变化的是char[]数组中的内容,这里我们需要知道字符串是存放于char[]数组中的,而一个char占用2个字节,所以abcdefg的char[]数组大小为对象头16Byte+实例数据14Byte+对齐填充2Byte=32Byte。那么abcdefg占用内存大小就是String对象+char[]数组对象=56Byte
用List存储对象
那么我们在内存中放入二千万个这个对象的话,需要占用多少内存呢?根据上面的知识我们能大概估算一下。我们定义一个List数组用于存放此对象,不让其回收。
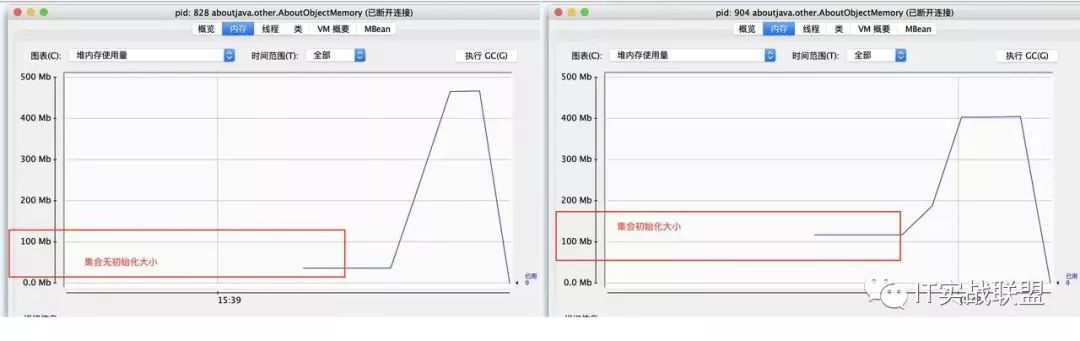
1List<Animal>animals=newArrayList<>(20000000);2for(inti=0;i<20000000;i++){3Animalanimal=newAnimal();4animals.add(animal);5}注意这里我是直接将集合的大小初始化为了二千万的大小,所以程序在正常启动的时候占用内存是100+MB,正常程序启动仅仅占用30+MB的,所以多出来的60+MB正好是我们初始化的数组的大小。至于为什么要初始化大小的原因就是为了消除集合在扩容时对我们观察结果的影响
这里我贴一张,集合未初始化大小和初始化大小内存占用对比图,大家可以看到是有内存上的差异,在ArrayList数组中用于存放数据的是transient Object[] elementData;Object数组,所以它里面存放的是指向对象的指针,一个指针占用4个字节,所以就有两千万个指针,那么就是76M。我们可以看到差异图和我们预想的一样。
上面我们已经算出来了一个Animal对象占用16个字节,所以两千万个占用大概是305MB,和集合加起来就是将近380MB的空间大小,接下来我们就启动程序来看一下我们结果是不是对的呢,接下来我用的jconsole工具查看内存占用情况。
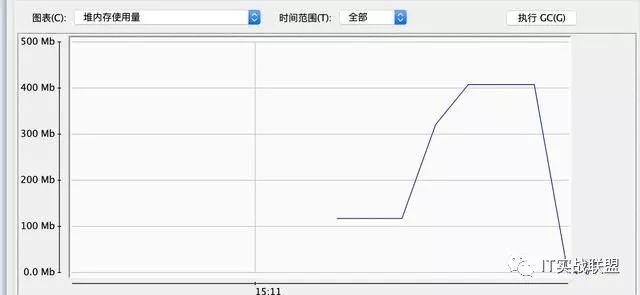
我们可以看到和我们预算的结果是相吻合的。
那么以后如果有大量的对象需要从数据库中查找出来放入内存的话,那么如果是使用对象来接的话,那么我们就应该尽量减少对象中的字段,因为即使你不赋值,其实他也是占用着内存的,我们接下来再举个例子看一下对个属性值的话占用内存是不是又高了。我们将Animal对象改造如下
1classAnimal{23privateintage;4privateintage1;5privateintage2;6privateintage3;7privateintage4;89}此时我们能够计算得到一个Animal对象占用的内存大小是(对象头12Byte+实例数据20Byte=32Byte)此时32由于是8的倍数所以无需进行填充补齐。那么此时如果还是二千万条数据的话,此对象占用内存应该是610MB,加上刚才集合中指针的数据76MB,那么加起来将近占用686MB,那么预期结果是否和我们的一样呢,我们重新启动程序观察,可以看到下图。可以看到和我们分析的数据是差不多的。

用Map存储对象
用Map存储对象计算内存大小有些麻烦了,众所周知Map的结构是如下图所示。
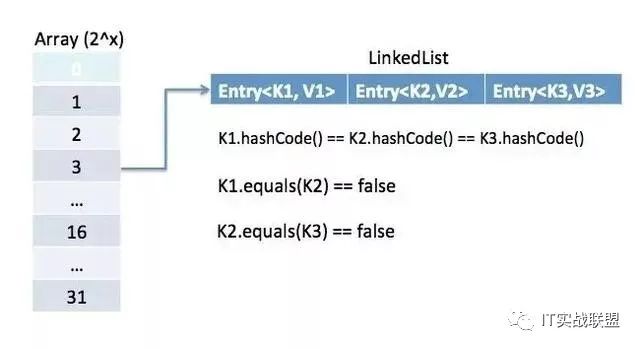
它是一个数组加链表(或者红黑树)的结构,而数组中存放的数据是Node对象。
1staticclassNode<K,V>implementsMap.Entry<K,V>{2finalinthash;3finalKkey;4Vvalue;5Node<K,V>next;6}我们举例定义下面一个Map对象
1Map<Animal,Animal>map此时我们可以自己计算一下一个Node对象需要的内存大小对象头12Byte+实例数据16Byte+对其填充4Byte=32Byte,当然这里的key和value的值还需要另算,因为Node对象此时存放的仅仅是他们的引用而已。一个Animal对象所占用内存大小我们上面也说了是16Byte,所以这里一个Node对象占用的大小为32Byte+16Byte+16Byte=64Byte。
下面我们用实际例子来验证下我们的猜想
1Map<Animal,Animal>map=newHashMap<>(20000000);2for(inti=0;i<20000000;i++){3map.put(newAnimal(),newAnimal());4}上面的例子在一个Map对象中存放二千万条数据,计算大概在内存中占用多少内存。
数组占用内存大小:我们先来计算一下数组占了多少,这里有个小知识点,在HashMap中初始化大小是按照2的倍数来的,比如你定义了大小为60,那么系统会给你初始化大小为64。所以我们定义为二千万,系统其实是会给我们初始化为33554432,所以此时仅仅HashMap中数组就占用了将近132MB
数据占用内存大小:我们上面计算了一个Node节点占用了64Byte,那么两千万条数据就占用了1280MB
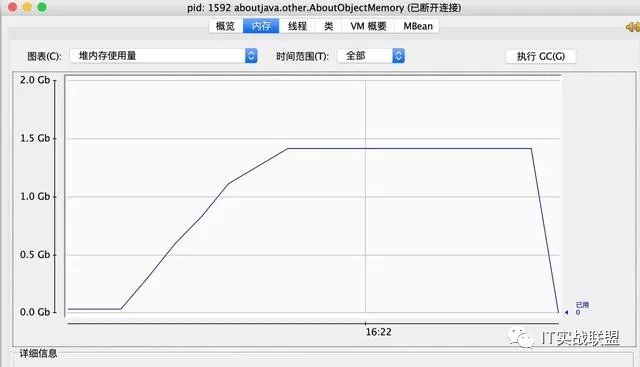
两个占用内存大小相加我们可以知道大概系统中占用了1.4G内存的大小。那么事实是否是我们想象的呢?我们运行程序可以看到内存大小如图所示。可以看到结果确实和我们猜想的一样。
总结
回归到上面所说的需求,几百万数据放到内存中会把内存撑爆吗?这时候你可以通过自己的计算得到。最终我们那个需求经过我算出来其实占用内存量几百兆,对于4个G的堆内存来说其实远远还没达到撑爆的地步。所以有时候我们对任何东西都要存在怀疑的态度。大家可以到GitHub中下载代码自己在本地跑一下监测一下,并且可以自己定义几个对象然后计算看是不是和图中的内存大小一致。这样才能记忆更深刻。送给大家一句话从来如此,便对吗?。其实我写的文章里面也留了一个小坑,大家可以试着找找,是在对集合进行初始化计算那一块。
注意:本文归作者所有,未经作者允许,不得转载

