导读
实用的推荐系统的构建经验,如何进行信息增强。
大家好,欢迎来到我的另一篇文章,我试图驯服推荐系统的海洋,并与挪威海怪战斗(或产品—随你怎么叫)

在我之前的两篇文章中,推荐系统中的产品聚类:一种文本聚类的方法,推荐系统中的命名实体识别:把产品匹配到不同的性别,你看到了我是如何处理产品的,如何搞定让事情变得非常困难的问题。
你可以看到,数据(在我们的数据库中,是商店的产品和客户)越多,计算就越大,也越复杂。大而复杂的计算占用了大量的时间。我要对付的是一只真正的怪兽!
我需要花很多时间来解决这个问题,但我手头还有另一个任务:就像每一个优秀的英雄都会做的那样,我需要用交互数据来帮助较小的商店,因为他们的交互数据是不够的。
在这篇文章中,我将调查一下我的任务对我们模型的影响。
但让我先提醒你推荐系统是什么:
推荐系统是一个系统,旨在预测用户对某项商品的偏好。
它使用的数据是用户过去的交互(浏览、购买评级等等),然后推荐类似的产品给用户,或者推荐物品与用户之间交互的关键因素,这样的话,会使得推荐的物品具有类似的特性。
但我知道你不喜欢长篇大论,这是行动,我们需要直奔主题。那么,言归正传:
产品聚类和实体识别让我驶向了不同的方向
为了避免更多的陷阱,我使用了和第一次相同的模型,但有一点不一样:我在其中使用了产品聚类和命名实体识别。
让我告诉你,这确实让事情变得更安全了。
产品聚类是我将不同品牌的所有相同或相似的产品放在同一个类别下的过程。
命名实体识别是我们在非结构化文本中寻找和识别信息单元并将其归类到预定义类别中的过程。
现在,在合并客户与产品的交互之前,我完成了产品聚类。
这样就创建了产品的组(聚类)。
下一步是将客户的交互分配给与之交互的产品所属的聚类。
这样的结果是,每个产品的信息都被增强了。我使用了交互数据,并在聚类中的所有产品之间共享它。
让我为你解释一下:
John 买了一件耐克的 t 恤衫,简买了一件阿迪达斯的 t 恤衫,Peter 买了一双阿迪达斯的鞋子。
T恤在同一组中,但是鞋子没有在同一组里面。
这些交互是这样分配的:
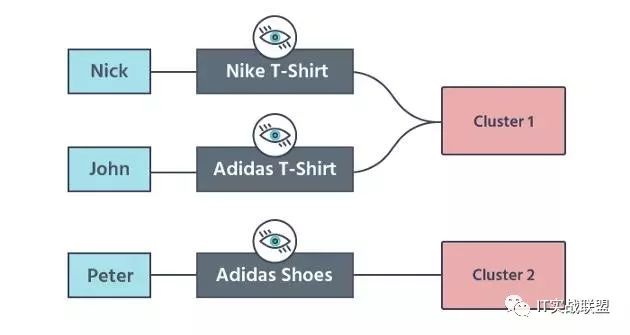
但还有一件事需要注意:单个聚类中只包含来自一种性别的产品。
因此,除了中性(男女通用或其他未指定的)产品外,不可能有人选择属于另一种性别的产品。
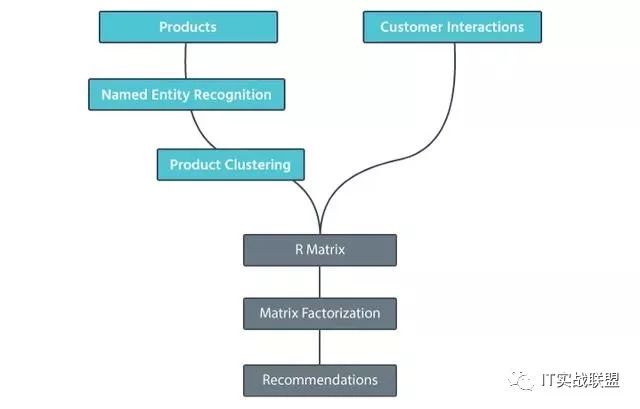
模型的工作流
选择产品的烦恼(以及我是如何解决这个问题的)
从聚类中选择要推荐的产品并不都是有趣的游戏。这些小虫子有时候会有点狡猾。
所以,我手上还有另一个问题,我必须解决它,为了让我的努力真正有意义。
我试图找到一种方法来对聚类中的每个产品根据流行度来评分。但是有一个参数我没有注意到:这使我最终一次又一次地从聚类中选择完全相同的产品。
这个问题是,最高的分数每次只分配给同一个产品,没有其他类型的数据来挽救其余的产品。
现在,似乎这还不够,这个评分方法使另一个怪物出现了:
一款针对男性的产品与一款针对女性的产品混在了一起
我不知道如何摆脱这个问题,当时唯一的逻辑解决方案是从聚类中随机选择每个产品。
最后变成了一场数字游戏
显然,当时我有点不知所措。然而,没有解决办法,只能坚持下去 — 即使这意味着我将在这个过程中崩溃和燃烧。
我使用了与我构建的第一个模型相同的度量标准,但是有一个小问题阻碍了整个过程:聚类。
在那个阶段,我有了产品聚类而不是单个产品。聚类由相同或非常相似的产品组成。
这让我别无选择,只能在两个不同的级别上度量我的船的性能:聚类和产品级别。
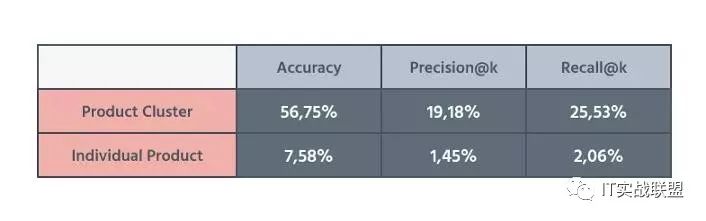
结果很明显。我的第一个模型是不完整的,但是通过添加产品聚类和命名实体识别,我设法改进了我的原始模型的各个组件并使其通过。
其准确性增加,从 2,3%到 7,58%
其精度增加,从 0,51%到 1,45%
其召回率增加,从 1,8%到 2,06%
到目前为止,一切都很好,这次旅行被认为是一次成功的旅行!
至少我是这么想的。但我很快就做出了判断……
数字会说谎(如果你数错了)
是的,当我使用产品聚类时,矩阵的大小减小了。计算时间也减少了(万岁!)。但这并不意味着我设法把它缩小到一个可工作的规模,它仍然太大,难以管理。
我面临的另一个问题是,计算太复杂了,我的计划无法正常工作。
我的计算在一两件事上出了问题(请继续关注我是如何解决这些问题的!)
当我观察模型推荐的产品并将它们与我提供给模型的产品交互信息进行比较时,我意识到有些东西有点不对劲。
与产品的交互(浏览、添加到购物车、购买,等等)和客户是不同的个体之间没有区别。
这根本不是等式的一部分。
对我来说,这听起来像是雷雨即将来临。我别无选择,只能找到解决办法。
我找到了。但我现在还不会告诉你。欢迎收看我的下一次冒险。更多的怪物,复杂的机制和英雄任务等待着你!
英文原文:https://medium.com/moosend-engineering-data-science/recommender-system-the-information-enhancement-trick-79dd12ea88e3
注意:本文归作者所有,未经作者允许,不得转载

